网站制作培训价格怎么在拼多多开网店
一、安装python并配置环境变量
1、打开python官网,下载并安装
Welcome to Python.org
下载
寻找版本:推荐使用3.9版本,或其他表中显示为安全(security)的版本


安装:(略)

2、配置环境变量:
复制python安装路径:高级系统设置、环境变量、Path、新建、将复制的python安装路径粘贴下去

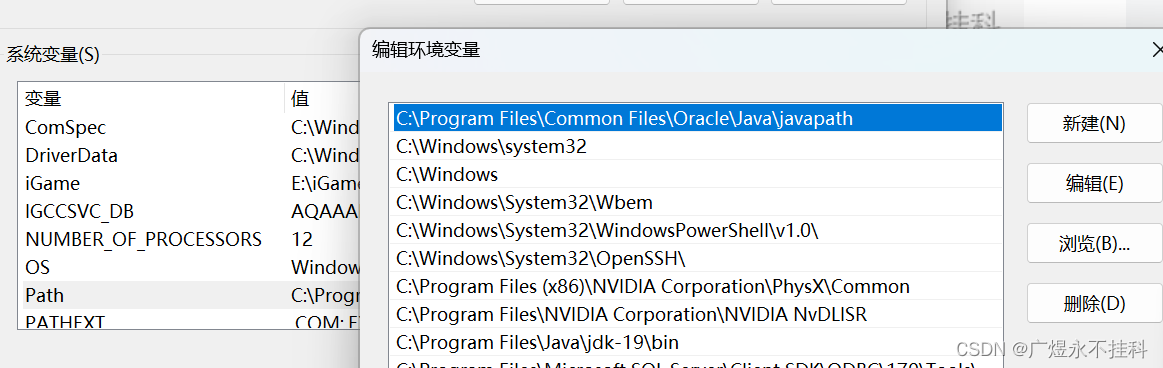
一般来说需要两个
路径\python<版本> # python路径
路径\python<版本>\Scripts # 第三方库的路径
3、如何确认安装完成?
打开《命令提示符》(win+R+cmd或者搜索命令提示符)
输入:python,打开python。

再次打开命令提示符:输入pip list

什么是pip list? pip list 是 Python 命令行中用于查看当前安装的第三方库的命令。通过这个命令,您可以了解 Python 环境中安装了哪些第三方库,以及它们的版本信息。python最为人称道的就是他强大的对第三方库的兼容性。
如果需要第三方库则可以通过:
pip install <package_name>:安装指定的第三方库。
pip uninstall <package_name>:卸载指定的第三方库。
pip update <package_name>:更新指定的第三方库到最新版本。
二、下载pycharm
1、下载pycharm(略)
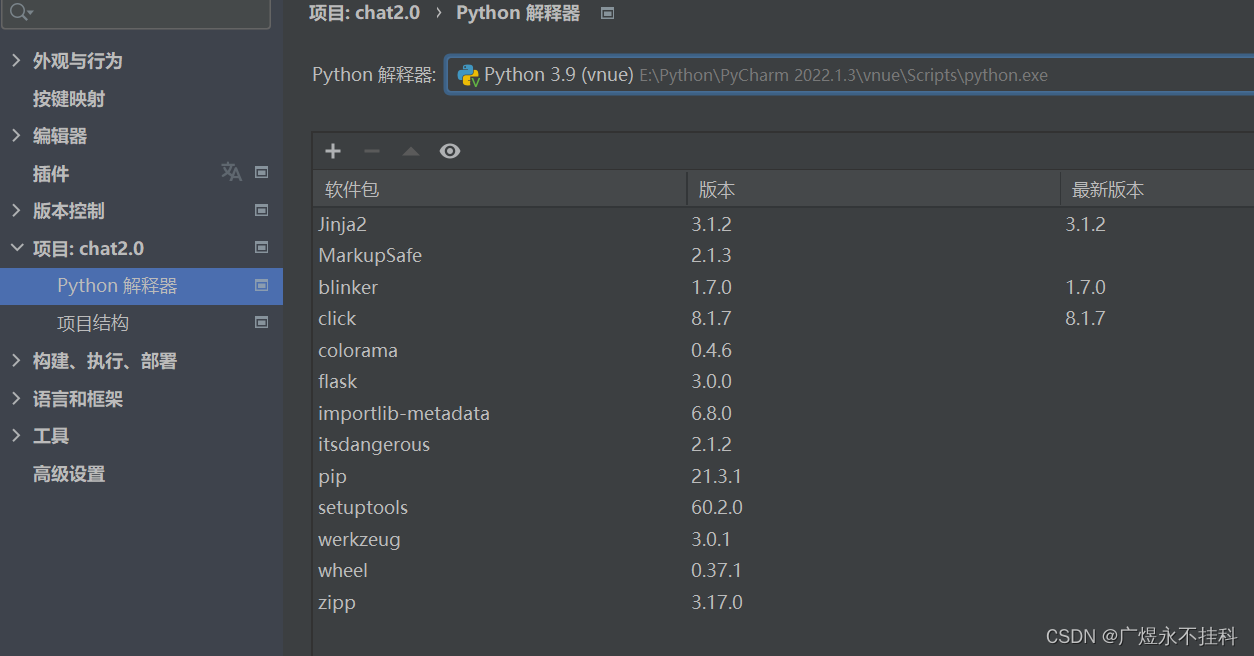
2、配置python解释器:
文件、设置、Python解释器、设置标志、添加、选择新解释器的存储位置、新解释器的基础解释器(python的安装路径)、确定、应用(来自后期,建议看看第4步)




pycharm的python解释器的作用,是一个接口,可以理解为一条数据线,连接着python和pycharm。

3、使用pychon解释器,当你打开一个项目以后:
右上角点开配置器、编辑配置、选择想要编辑的配置、选择python解释器、应用、运行


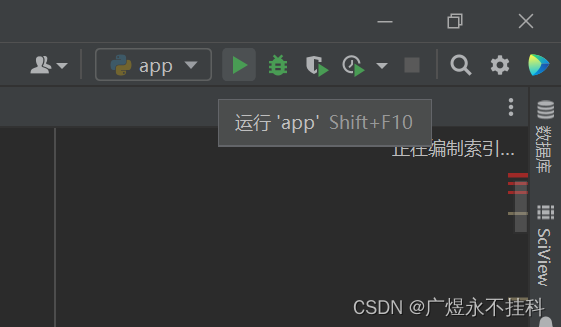
出错了?未检测到模块!
4、未检测到模块?
 出现这个错误的原因之一是你的pip第三方库的安装路径和你在第二部中配置的python解释器的环境不一致。
出现这个错误的原因之一是你的pip第三方库的安装路径和你在第二部中配置的python解释器的环境不一致。
文件、设置、Python解释器、设置标志、添加、现有环境、复制下方路径、确定、应用
路径\Python39\Lib\venv\scripts\nt\python.exe