硚口区建设局网站wordpress后台更改语言
一. bootz启动Linux
uboot 启动Linux内核使用bootz命令。当然还有其它的启动命令,例如,bootm命令等等。
本文只分析 bootz命令启动 Linux内核的过程中涉及的几个重要函数。具体分析 do_bootm_linux函数执行过程。
本文继上一篇文章,地址如下:
bootz启动 Linux内核涉及 bootm_os_get_boot_func 函数-CSDN博客
二. bootz 启动 Linux 内核涉及函数
2. do_bootm_linux 函数
经过前面的分析,我们知道了 do_bootm_linux 函数就是最终启动 Linux 内核的函数,此函数定
义在文件 arch/arm/lib/bootm.c,函数内容如下:
int do_bootm_linux(int flag, int argc, char * const argv[],bootm_headers_t *images)
{/* No need for those on ARM */if (flag & BOOTM_STATE_OS_BD_T || flag & BOOTM_STATE_OS_CMDLINE)return -1;if (flag & BOOTM_STATE_OS_PREP) {boot_prep_linux(images);return 0;}if (flag & (BOOTM_STATE_OS_GO | BOOTM_STATE_OS_FAKE_GO)) {boot_jump_linux(images, flag);return 0;}boot_prep_linux(images);boot_jump_linux(images, flag);return 0;
}
do_bootm_linux 函数:
第13行,如果参数flag等于BOOTM_STATE_OS_GO或者BOOTM_STATE_OS_FAKE_GO ,就行 boot_jump_linux 函数。
boot_selected_os 函数在调用 do_bootm_linux 时,会将 flag 设置为 BOOTM_STATE_OS_GO。
第 14 行,执行函数 boot_jump_linux,此函数定义在文件 arch/arm/lib/bootm.c 中,函数内容如下:
static void boot_jump_linux(bootm_headers_t *images, int flag)
{
#ifdef CONFIG_ARM64
..........
#elseunsigned long machid = gd->bd->bi_arch_number;char *s;void (*kernel_entry)(int zero, int arch, uint params);unsigned long r2;int fake = (flag & BOOTM_STATE_OS_FAKE_GO);kernel_entry = (void (*)(int, int, uint))images->ep;s = getenv("machid");if (s) {if (strict_strtoul(s, 16, &machid) < 0) {debug("strict_strtoul failed!\n");return;}printf("Using machid 0x%lx from environment\n", machid);}debug("## Transferring control to Linux (at address %08lx)" \"...\n", (ulong) kernel_entry);bootstage_mark(BOOTSTAGE_ID_RUN_OS);announce_and_cleanup(fake);if (IMAGE_ENABLE_OF_LIBFDT && images->ft_len)r2 = (unsigned long)images->ft_addr;elser2 = gd->bd->bi_boot_params;.............kernel_entry(0, machid, r2);}
#endif
}第 6 行,变量 machid 保存机器 ID。
如果不使用设备树,这个机器 ID 会被传递给 Linux 内核,Linux 内核会在自己的机器 ID 列表里面查找是否存在与 uboot 传递进来的 machid 匹配的项目,如果存在就说明 Linux 内核支持这个机器,则 Linux 就会启动!
如果使用设备树的话,这个 machid 就无效了,设备树文件中存有一个“兼容性”这个属性,Linux 内核会比较“兼容性”属性的值(字符串)来查看是否支持这个机器。
static void announce_and_cleanup(int fake)
{printf("\nStarting kernel ...%s\n\n", fake ?"(fake run for tracing)" : "");bootstage_mark_name(BOOTSTAGE_ID_BOOTM_HANDOFF, "start_kernel");
.............cleanup_before_linux();
}
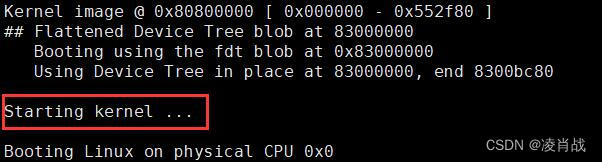
第 28 行,如果使用设备树的话,r2 应该是设备树的起始地址,而设备树地址保存在 images