国家建设部网站查询做网站一月能赚50万吗
自动复盘 2023-10-16
凡所有相,皆是虚妄。若见诸相非相,即见如来。
k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让市场来告诉你
跟踪板块总结:
-
成交额超过 100 亿 -
排名靠前,macd柱由绿转红 -
成交量要大于均线 -
有必要给每个行业加一个上级的归类,这样更能体现主流方向 -
rps 有时候比较滞后,但不少是欲杨先抑, 应该持续跟踪,等 macd 反转时参与 -
一线红:第一次买点出现后往往是顶峰,等回调,macd 反转,rps50 还一直红,第二次买点重现 -
行业趋势依旧在,做最强个股,别恐高。 -
第一波行情 rps20 + 10日均线,第二波行情 rps50 + macd反转。
板块 rps 排名
| rps10排名 | rps20排名 | rps50排名 | rps120排名 |
|---|---|---|---|
| 1. 屏下摄像 | 1. 创新药 | 1. 屏下摄像 | 1. 减速器 |
| 2. 3D摄像头 | 2. CRO | 2. 3D摄像头 | 2. 汽车零部件 |
| 3. 创新药 | 3. 屏下摄像 | 3. 通信服务 | 3. 屏下摄像 |
| 4. CRO | 4. 化学制药 | 4. 消费电子 | 4. 汽车热管理 |
| 5. 生物识别 | 5. 3D摄像头 | 5. CRO | 5. 激光雷达 |
| 6. 消费电子 | 6. 生物制品 | 6. 光学光电子 | 6. 汽车整车 |
| 7. 激光雷达 | 7. 中药 | 7. 创新药 | 7. 银行 |
| 8. 化学制药 | 8. 医疗美容 | 8. 生物识别 | 8. 电机 |
| 9. 光学光电子 | 9. 中药概念 | 9. 植物照明 | 9. 地摊经济 |
| 10. 植物照明 | 10. 医疗服务 | 10. 激光雷达 | 10. 铁路公路 |
| 11. 电子车牌 | 11. 工业大麻 | 11. ST股 | 11. 船舶制造 |
| 12. 风电设备 | 12. 激光雷达 | 12. 电子车牌 | 12. 煤炭行业 |
| 13. 智能穿戴 | 13. 精准医疗 | 13. 化学制药 | 13. 页岩气 |
| 14. 车联网 | 14. 医疗器械 | 14. 通信设备 | 14. 燃气 |
| 15. 无线耳机 | 15. 汽车整车 | 15. 智能穿戴 | 15. 无人驾驶 |
| 16. 汽车整车 | 16. 消费电子 | 16. 煤炭行业 | 16. 通信设备 |
| 17. MiniLED | 17. 汽车零部件 | 17. MiniLED | 17. 消费电子 |
| 18. 汽车零部件 | 18. 生物识别 | 18. 5G概念 | 18. 光学光电子 |
| 19. 生物制品 | 19. 体外诊断 | 19. 工业大麻 | 19. 3D摄像头 |
| 20. 通信服务 | 20. 植物照明 | 20. 数字水印 | 20. 植物照明 |
| 21. 无人驾驶 | 21. 汽车热管理 | 21. 时空大数据 | 21. 通信服务 |
| 22. 汽车热管理 | 22. 互联医疗 | 22. 空间站概念 | 22. 工业4.0 |
| 23. 时空大数据 | 23. 智能穿戴 | 23. 电子化学品 | 23. 证券 |
| 24. 电子烟 | 24. 化妆品概念 | 24. 无线耳机 | 24. 空气能热泵 |
| 25. 5G概念 | 25. 通信设备 | 25. 中药 | 25. 空间站概念 |
板块 rps20 排名详情
| 板块 | 详情 |
|---|---|
| 1. 创新药 | 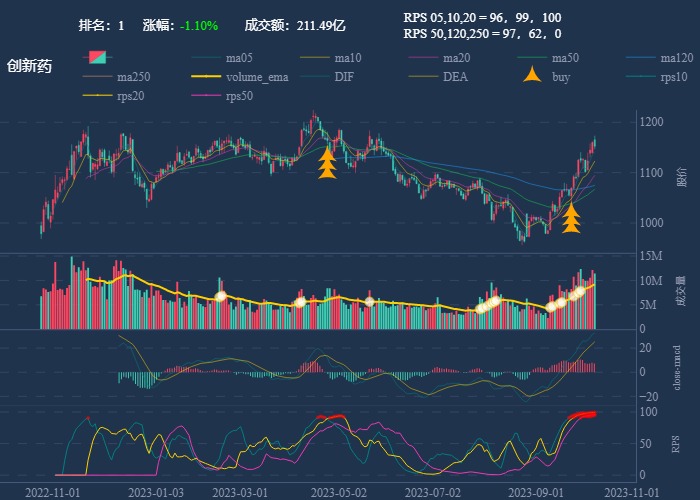 |
| 2. CRO | 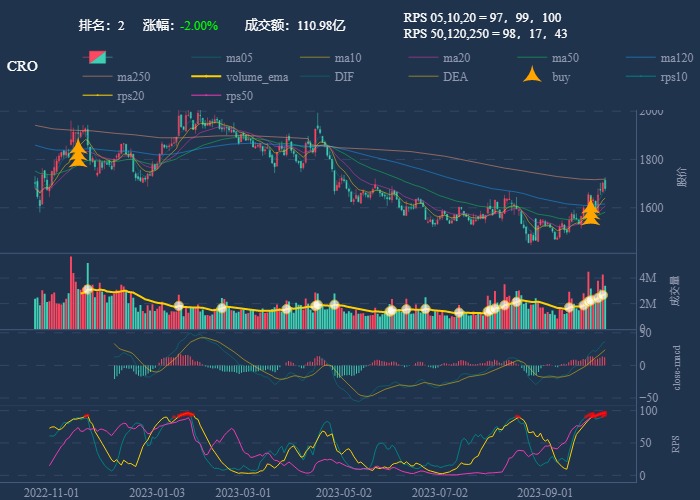 |
| 3. 屏下摄像 | 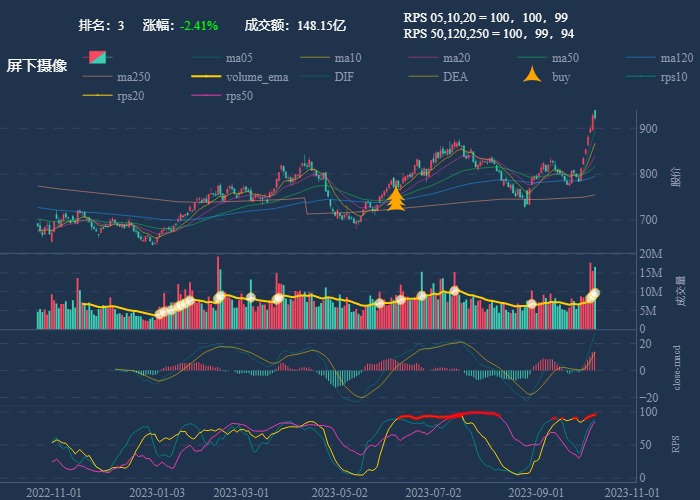 |
| 4. 化学制药 | 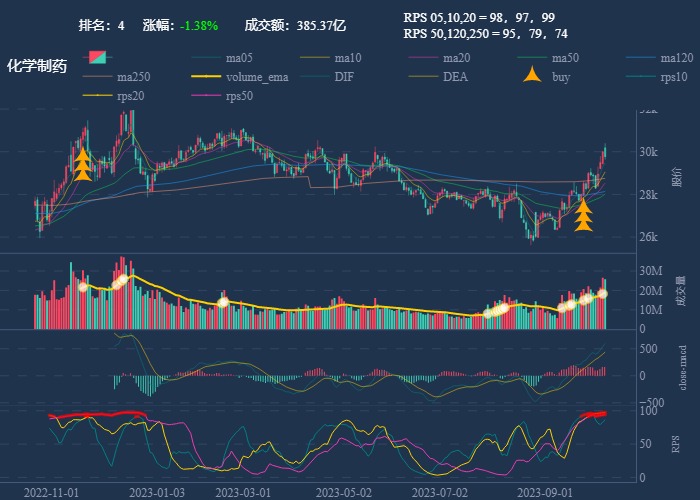 |
| 5. 生物制品 | 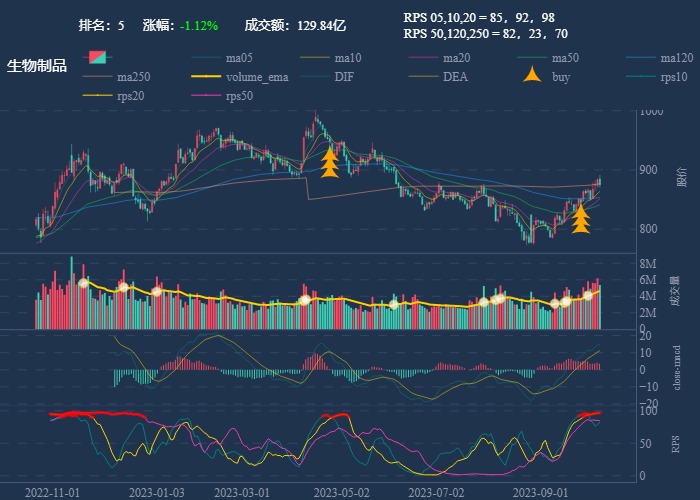 |
| 6. 3D摄像头 | 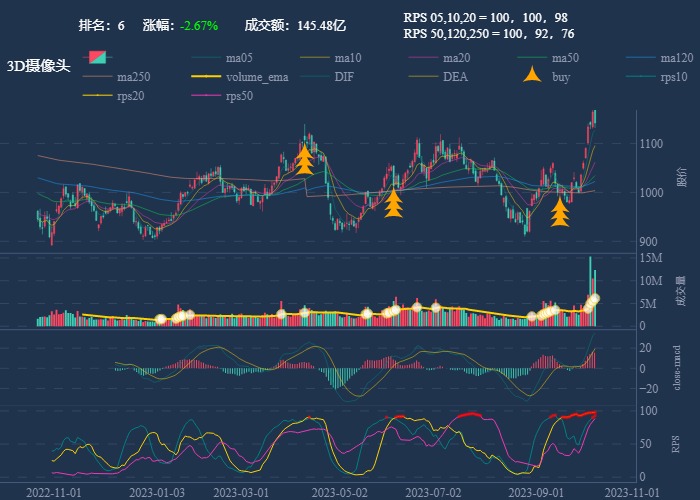 |
| 7. 中药概念 | 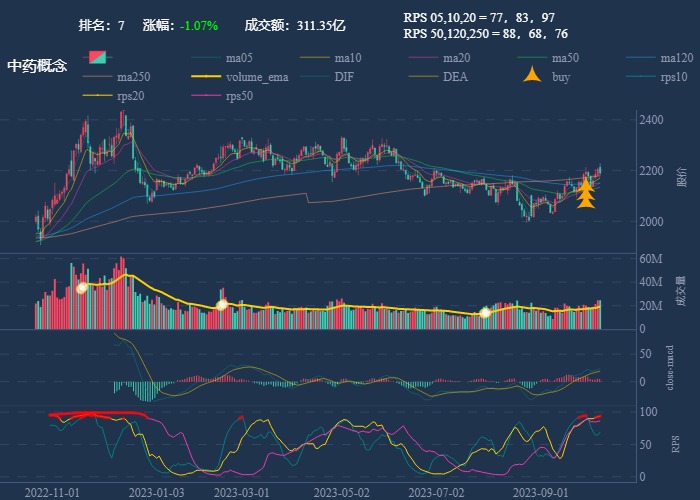 |
| 8. 医疗美容 | 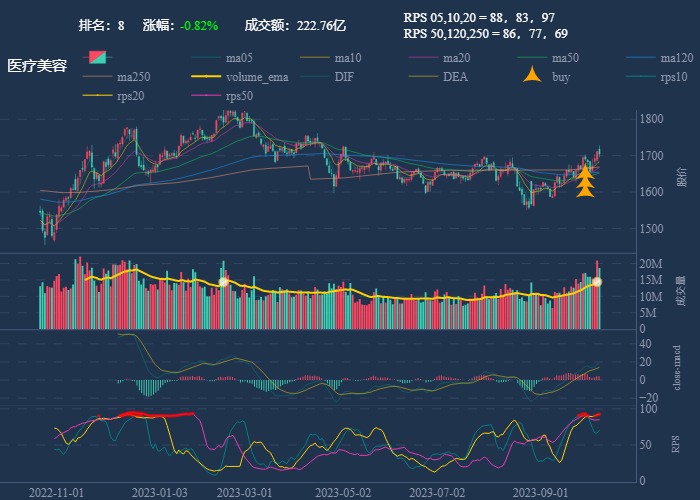 |
| 9. 中药 | 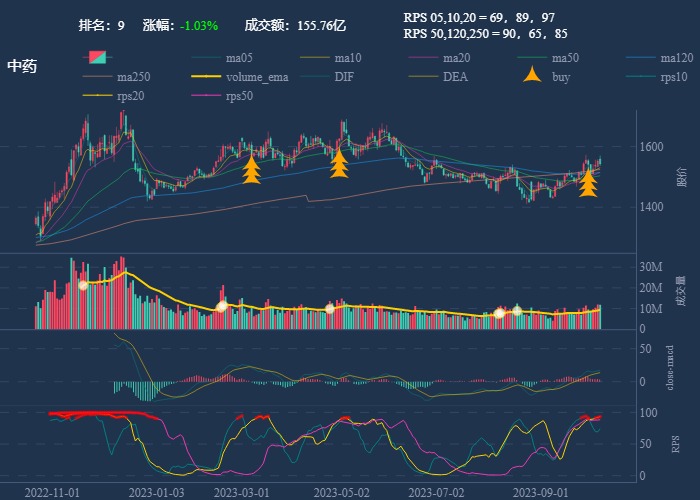 |
| 10. 医疗服务 | 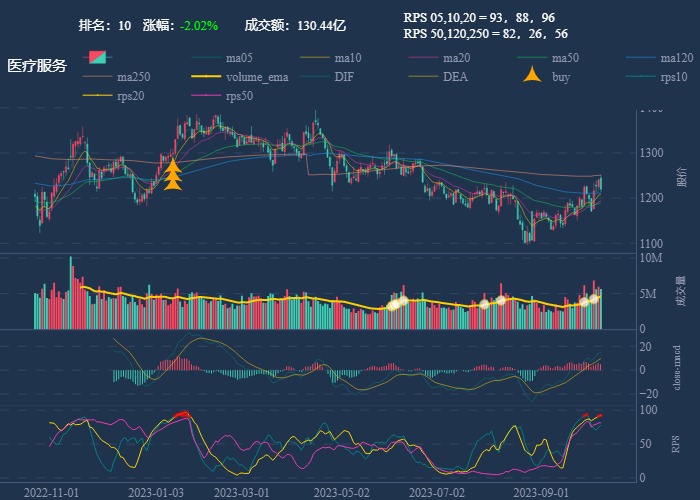 |
| 11. 工业大麻 | 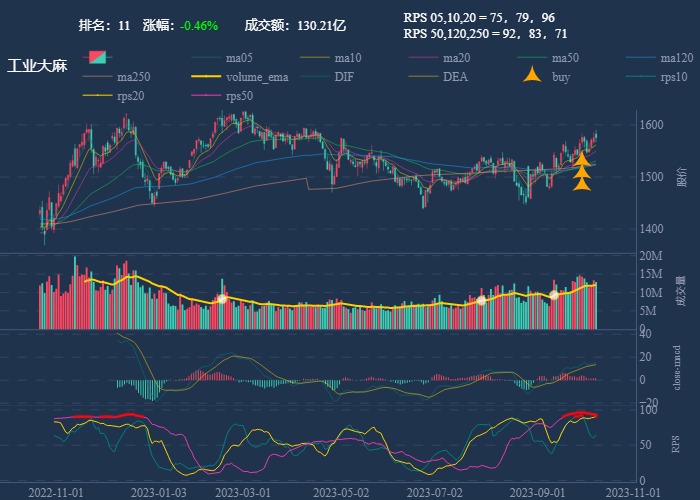 |
| 12. 精准医疗 | 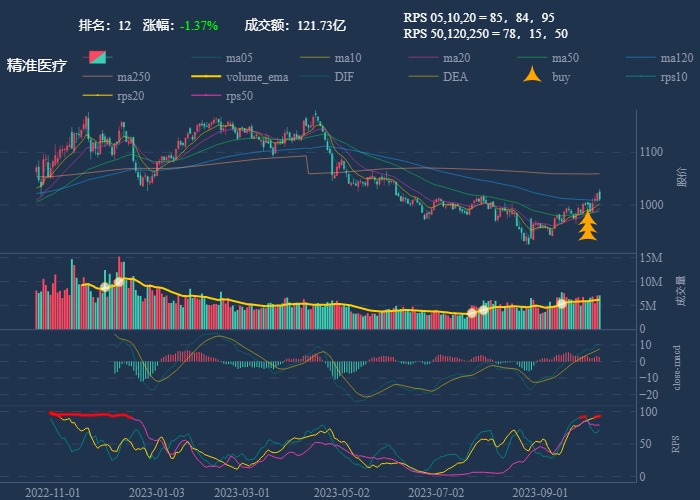 |
| 13. 激光雷达 | 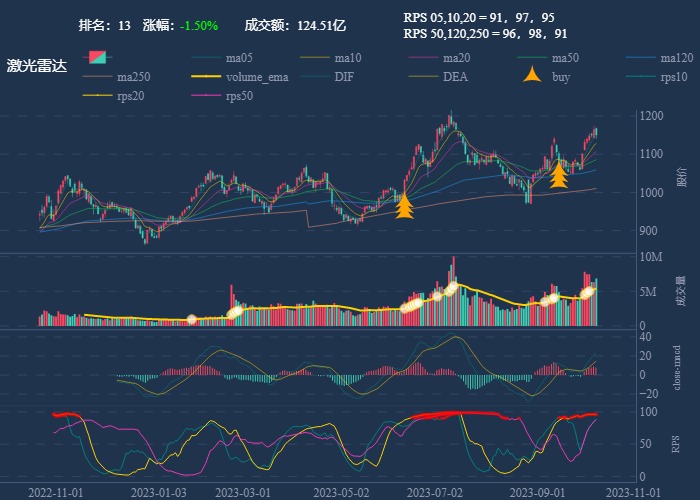 |
| 14. 医疗器械 | 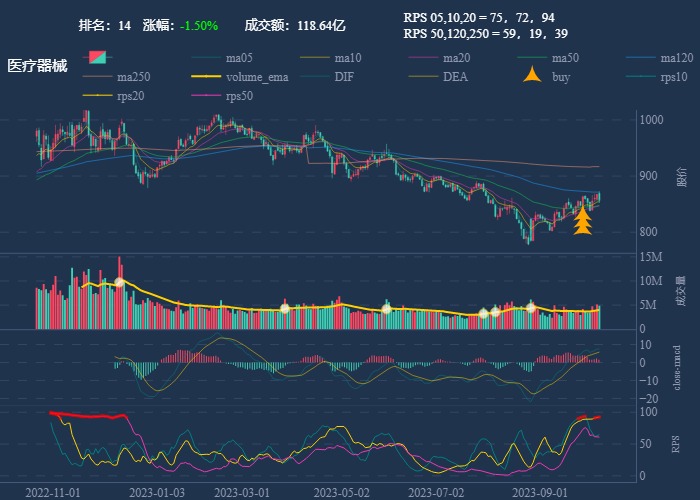 |
| 15. 汽车整车 | 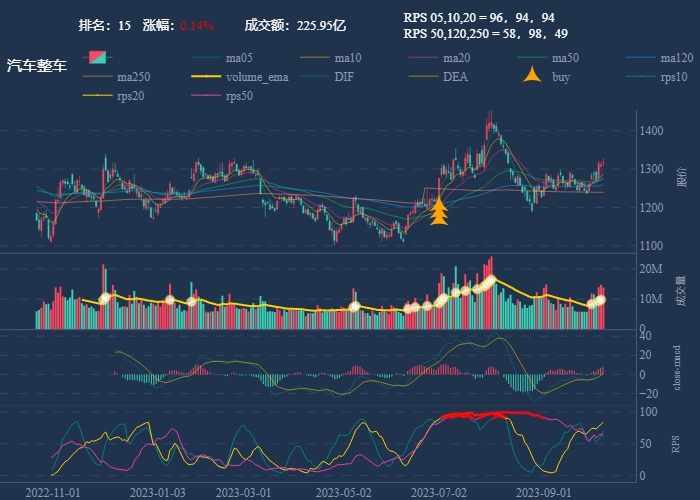 |
| 16. 消费电子 | 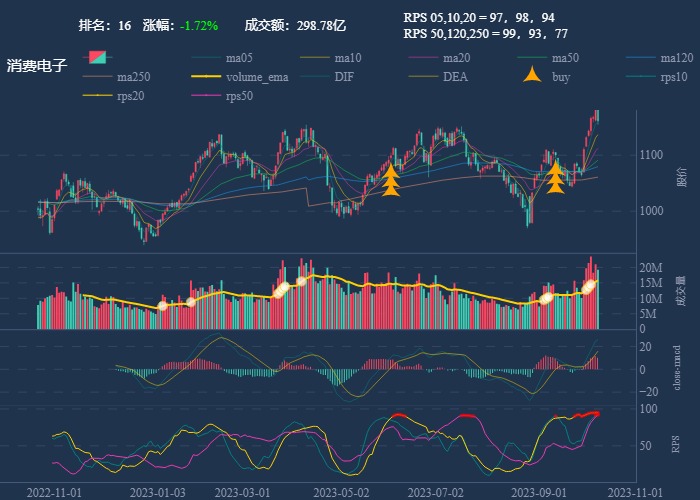 |
| 17. 生物识别 | 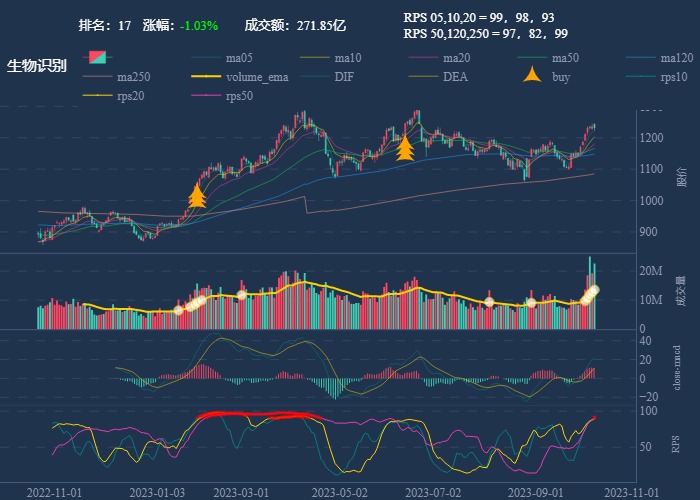 |
| 18. 汽车零部件 | 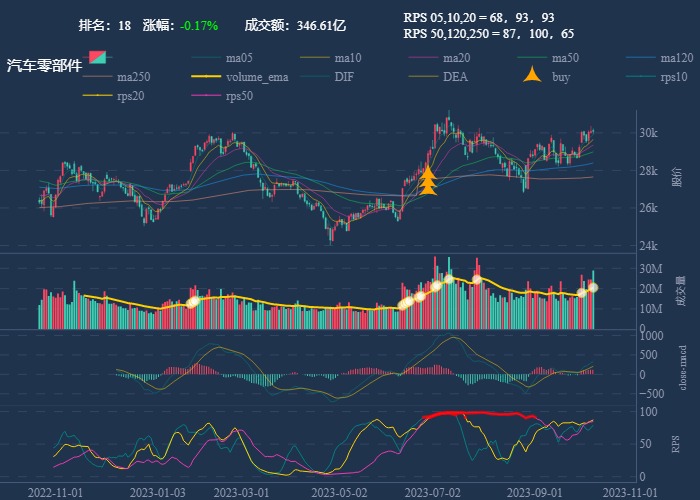 |
| 19. 植物照明 | 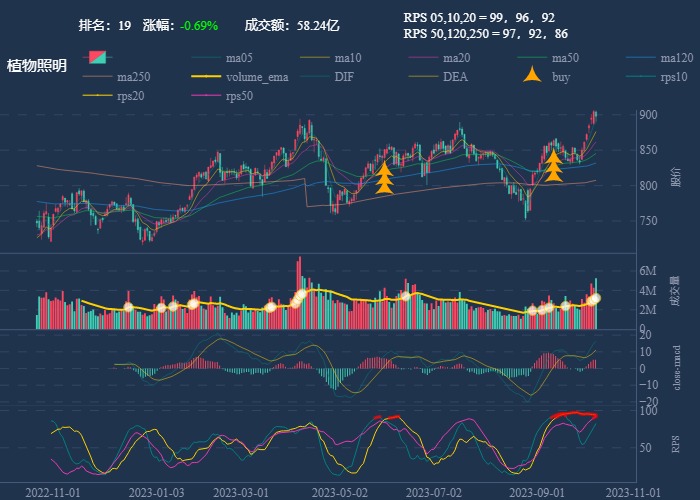 |
| 20. 体外诊断 | 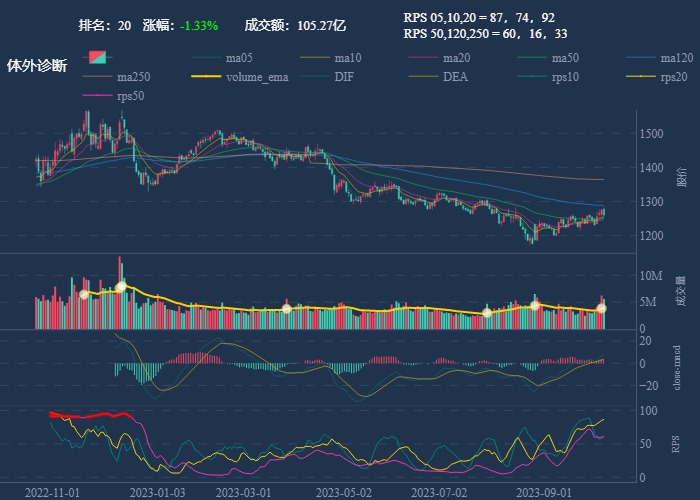 |
| 21. 汽车热管理 | 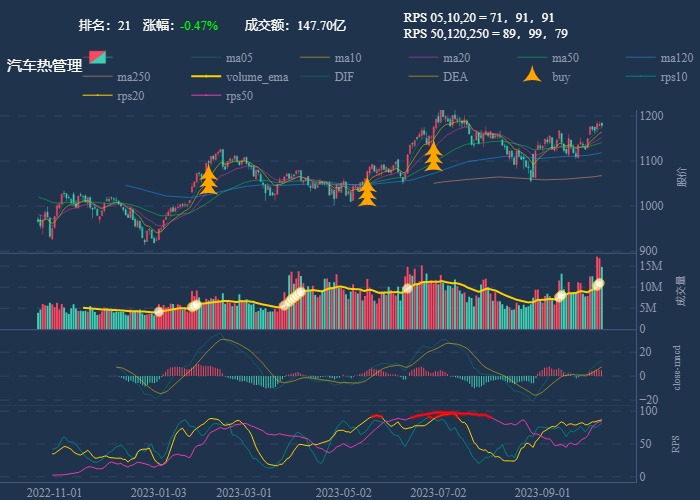 |
| 22. 互联医疗 | 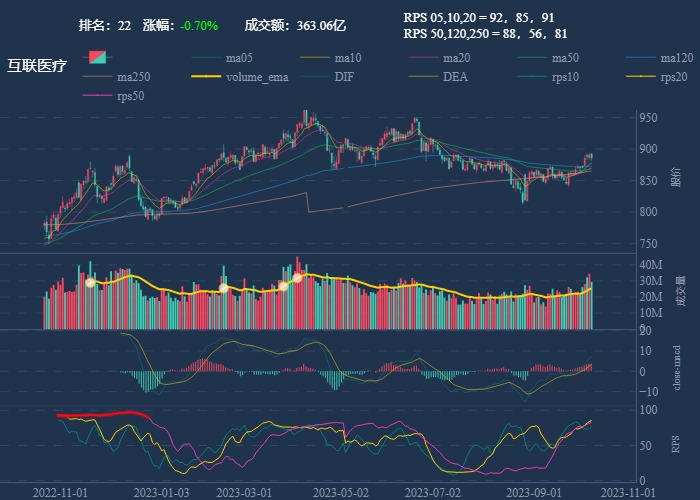 |
| 23. 智能穿戴 | 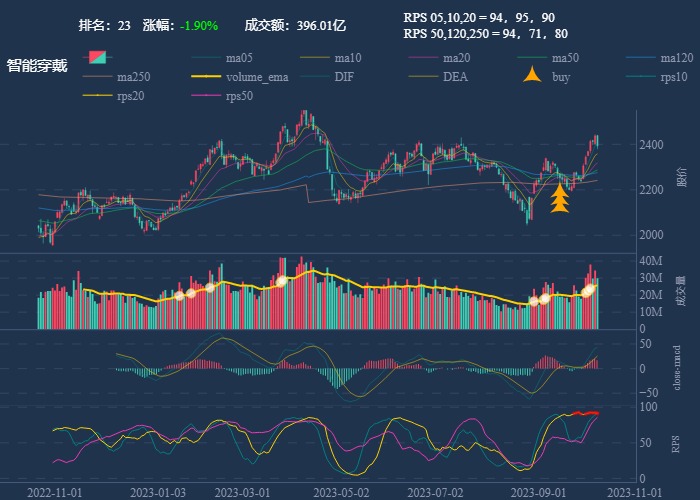 |
| 24. 化妆品概念 | 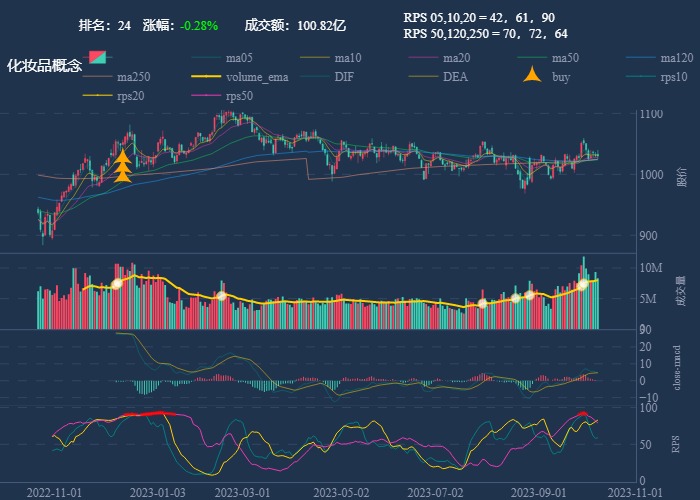 |
| 25. 通信设备 | 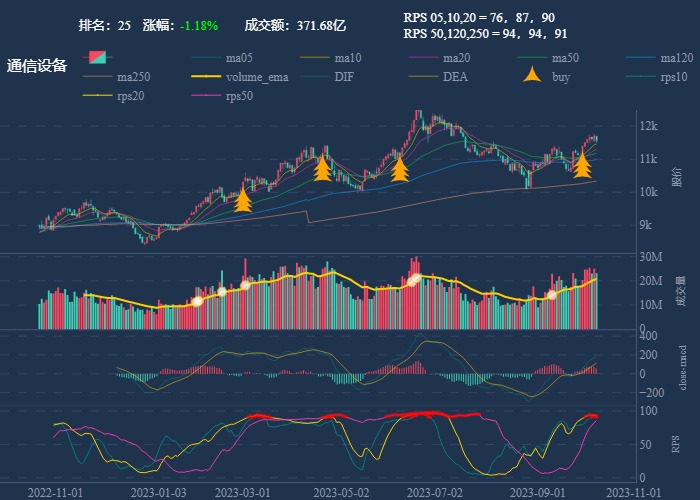 |
板块 rps50 排名详情
| 板块 | 详情 |
|---|---|
| 1. 3D摄像头 | 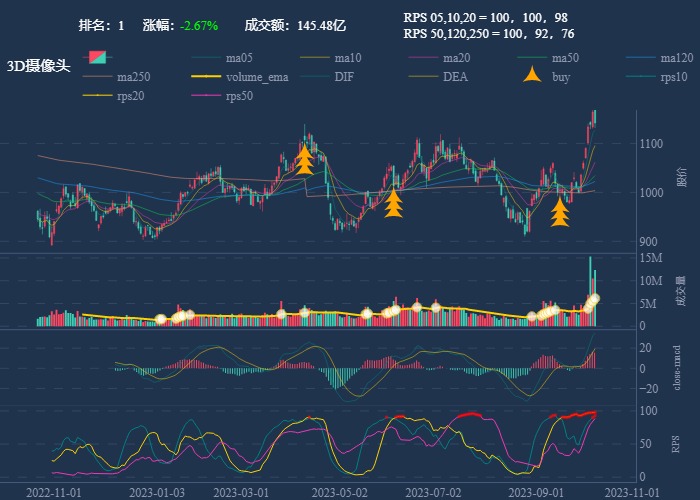 |
| 2. 屏下摄像 | 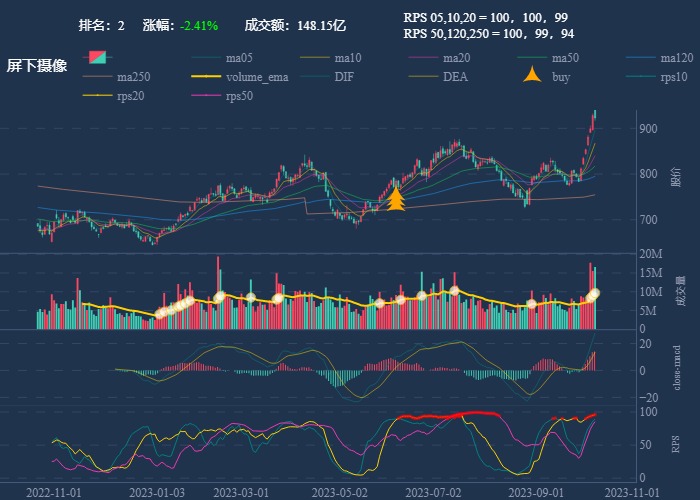 |
| 3. 消费电子 | 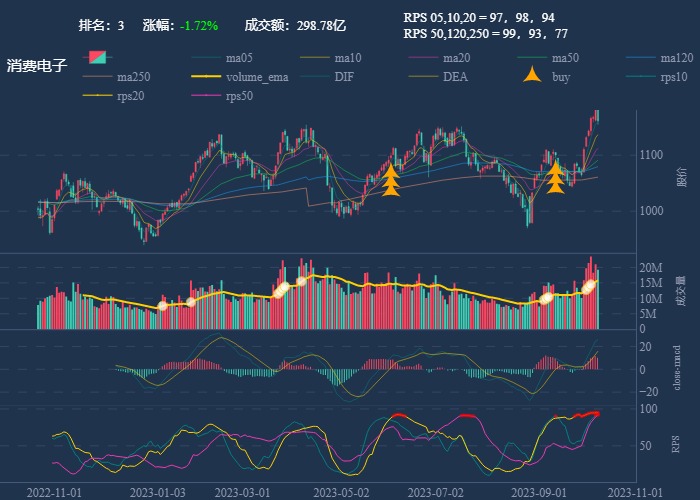 |
| 4. 通信服务 | 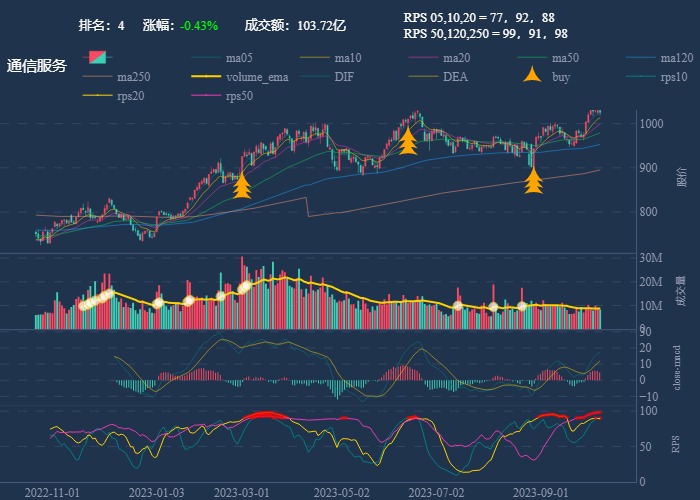 |
| 5. 光学光电子 | 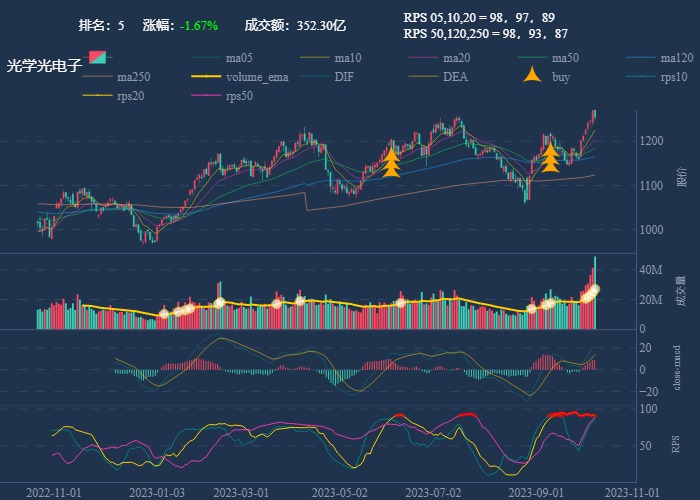 |
| 6. CRO | 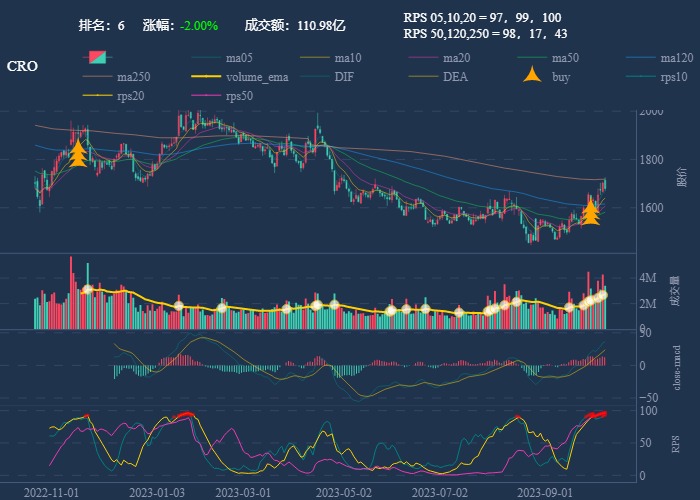 |
| 7. 植物照明 | 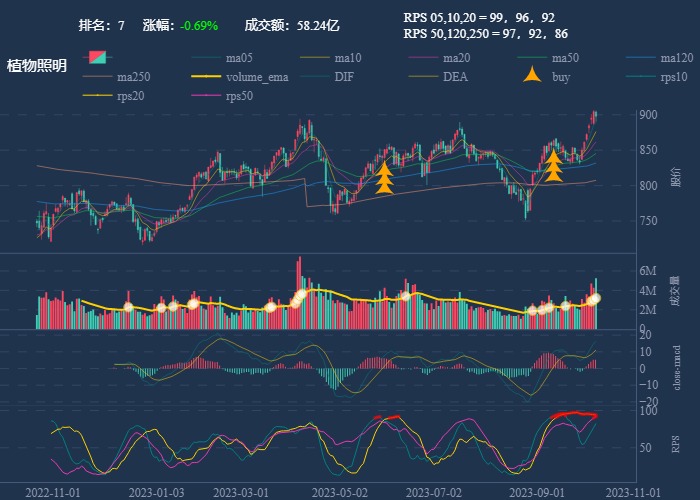 |
| 8. 创新药 | 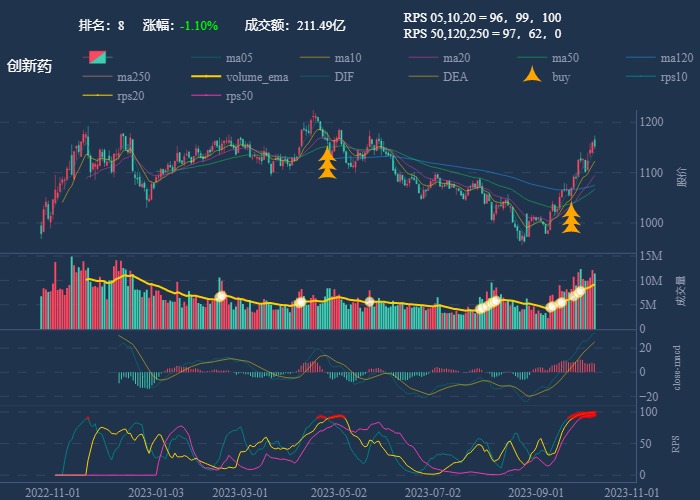 |
| 9. 生物识别 | 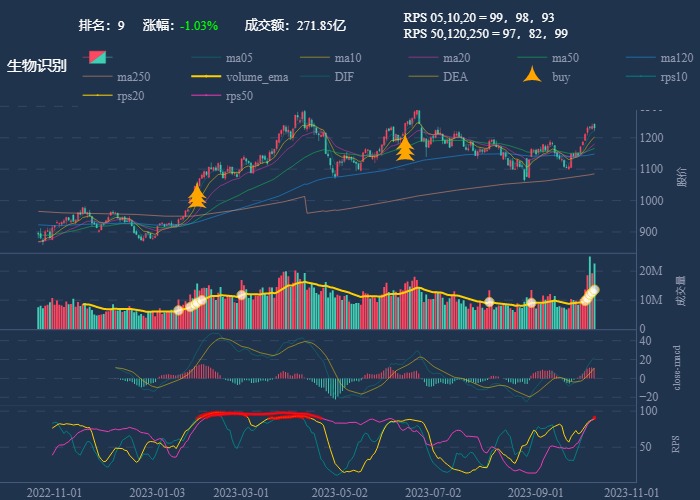 |
| 10. ST股 | 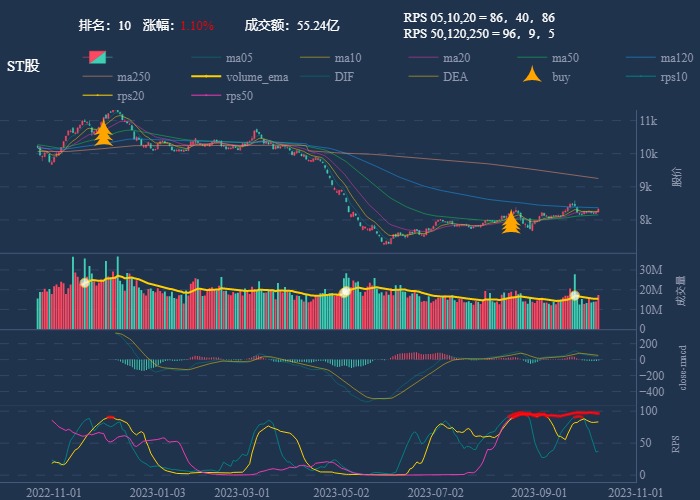 |
| 11. 激光雷达 | 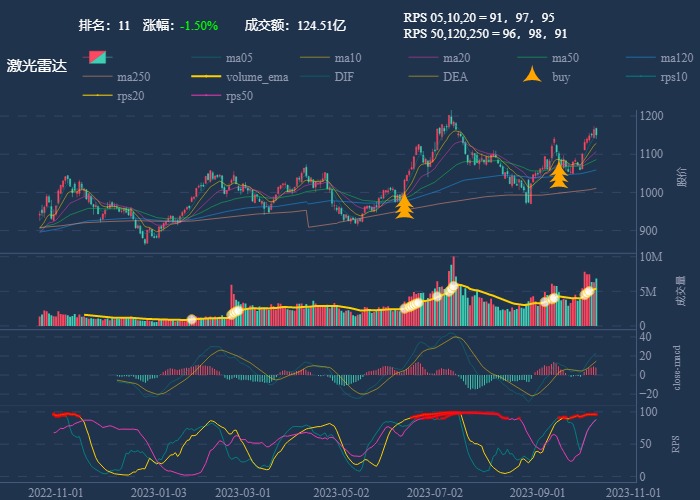 |
本文由 mdnice 多平台发布