iis找出网站死循环全国城建证书查询
计算 PDF 文件中的页数对于各种目的都至关重要,例如确定文档长度、组织内容和评估打印要求。除了使用 PDF 查看器了解页数信息外,您还可以通过编程自动执行该任务。在本文中,您将学习如何使用C#通过Spire.PDF for .NET获取 PDF 文件中的页数。
Spire.PDF for .NET 是一款独立 PDF 控件,用于 .NET 程序中创建、编辑和操作 PDF 文档。使用 Spire.PDF 类库,开发人员可以新建一个 PDF 文档或者对现有的 PDF 文档进行处理,且无需安装 Adobe Acrobat。
E-iceblue 功能类库Spire 系列文档处理组件均由中国本土团队研发,不依赖第三方软件,不受其他国家的技术或法律法规限制,同时适配国产操作系统如中科方德、中标麒麟等,兼容国产文档处理软件 WPS(如 .wps/.et/.dps 等格式
安装 Spire.PDF for .NET
首先,您需要将 Spire.PDF for .NET 包中包含的 DLL 文件添加为 .NET 项目中的引用。 可以从此链接下载 DLL 文件,也可以通过NuGet安装。
PM> Install-Package Spire.PDF
使用 C# 获取 PDF 文件的页数
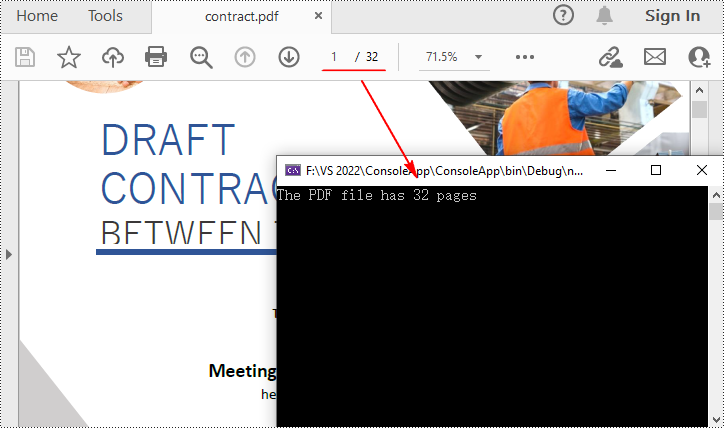
Spire.PDF for .NET 提供了PdfDocument.Pages.Count属性,无需打开 PDF 文件即可快速计算其页数。以下是详细步骤。
- 创建一个PdfDocument对象。
- 使用PdfDocument.LoadFromFile()方法加载示例 PDF 文件。
- 使用PdfDocument.Pages.Count属性计算 PDF 文件中的页数。
- 输出结果并关闭PDF。
【C#】
using Spire.Pdf;namespace GetNumberOfPages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument pdf = new PdfDocument();//Load a sample PDF file
pdf.LoadFromFile("Contract.pdf");//Count the number of pages in the PDF
int PageNumber = pdf.Pages.Count;
Console.WriteLine("The PDF file has {0} pages", PageNumber);//Close the PDF
pdf.Close();
}
}
}