网站建设专业培训义乌网站建设方式
文章目录
- 分布式任务调度
- XXL-Job 简介
- XXL-Job 环境搭建
- XXL-Job (源码说明)
- 配置部署调度中心
- docker安装
- Bean模式任务(方法形式)-入门案例
- 任务详解
- 任务详解-执行器
- 任务详解-基础配置
- 任务详解-调度配置
- 任务详解-基础配置
- 任务详解-阻塞处理策略
- 任务详解-路由策略
- 路由策略
- 路由策略(轮询)-案例
- 路由策略(分片广播)
- 路由策略(分片广播)-案例
spring 传统的定时任务@Scheduled,但是这样存在这一些问题 :
- 做集群任务的重复执行问题
- cron表达式定义在代码之中,修改不方便
- 定时任务失败了,无法重试也没有统计
- 如果任务量过大,不能有效的分片执行
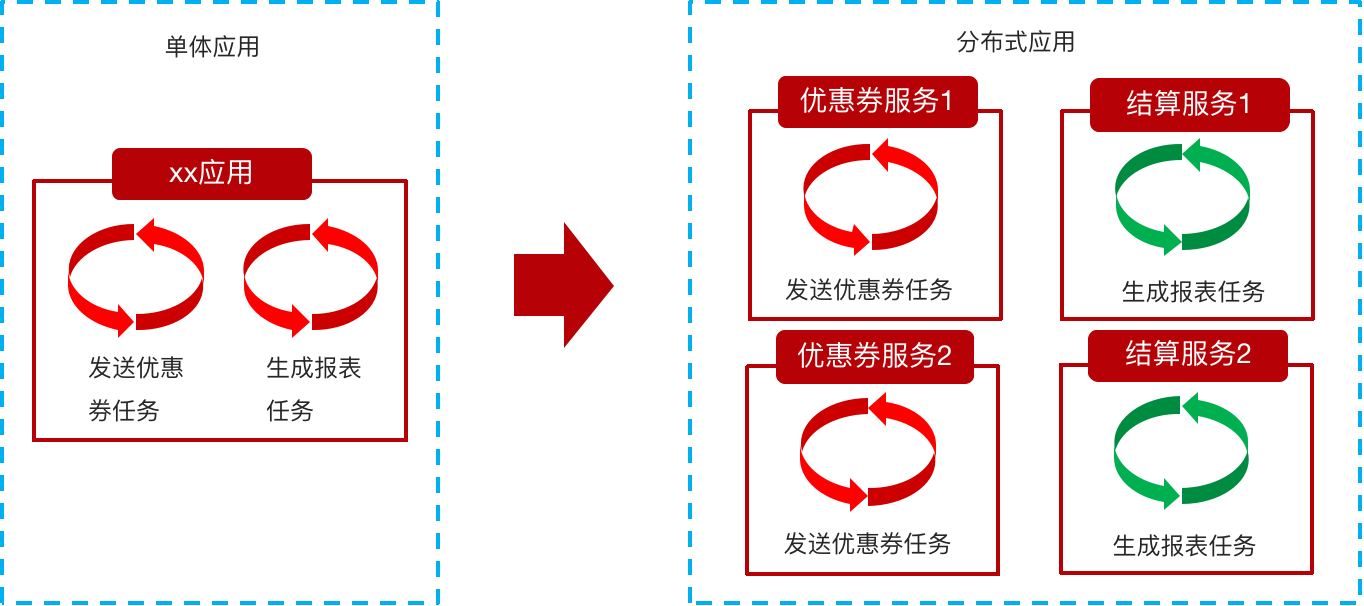
分布式任务调度
在分布式架构下,一个服务往往会部署多个实例来运行我们的业务,如果在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度。
XXL-Job 简介
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
源码地址:https://gitee.com/xuxueli0323/xxl-job
文档地址:https://www.xuxueli.com/xxl-job/
同类产品:

XXL-Job 环境搭建
-
调度中心环境要求
Maven3+
Jdk1.8+
Mysql5.7+ -
源码仓库地址
| 源码仓库地址 | Release Download |
|---|---|
| https://github.com/xuxueli/xxl-job | https://github.com/xuxueli/xxl-job/releases |
| http://gitee.com/xuxueli0323/xxl-job | http://gitee.com/xuxueli0323/xxl-job/releases |
XXL-Job (源码说明)

配置部署调度中心
作用:统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台。
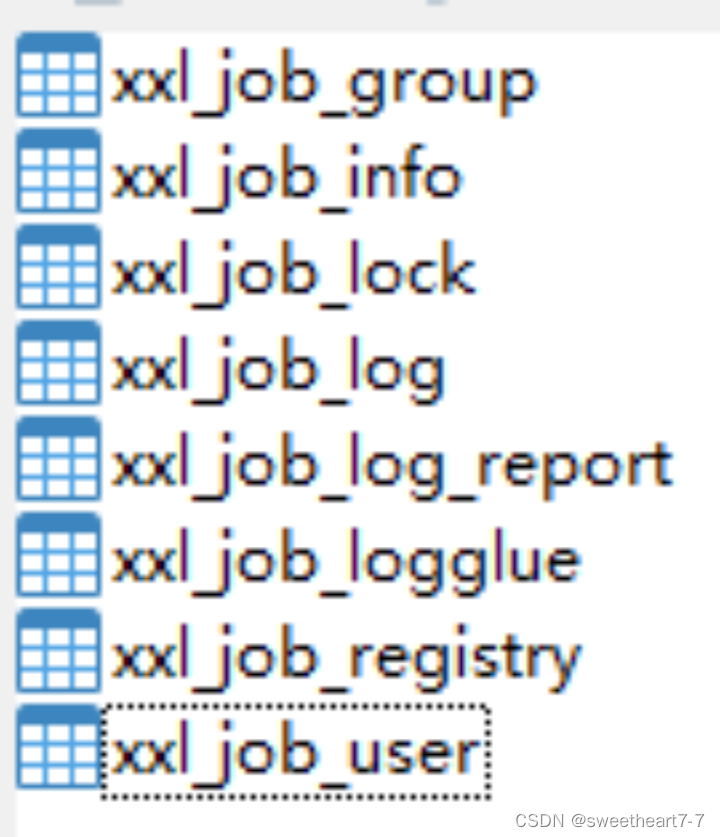
- 调度数据库初始化SQL脚本执行
位置:xxl-job/doc/db/tables_xxl_job.sql 共8张表
- 调度中心配置
配置文件位置:xxl-job/xxl-job-admin/src/main/resources/application.properties

- 启动调度中心,默认登录账号 “admin/123456”, 登录后运行界面如下图所示。
docker安装
- 创建mysql容器,初始化xxl-job的SQL脚本

- 拉取镜像

- 创建容器

Bean模式任务(方法形式)-入门案例
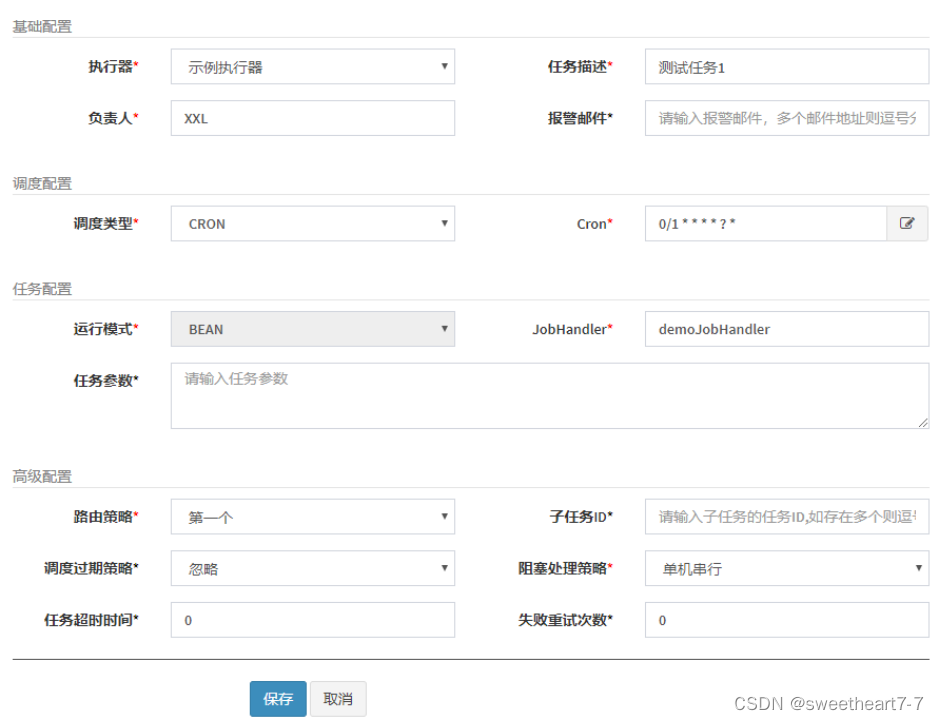
- 登录调度中心,点击下图所示“新建任务”按钮,新建示例任务
- 创建xxljob-demo项目,导入依赖

application.yml配置

- 任务代码,重要注解:@XxlJob(“JobHandler”)

- 测试-单节点
- 启动微服务
- 启动任务
任务详解
任务详解-执行器
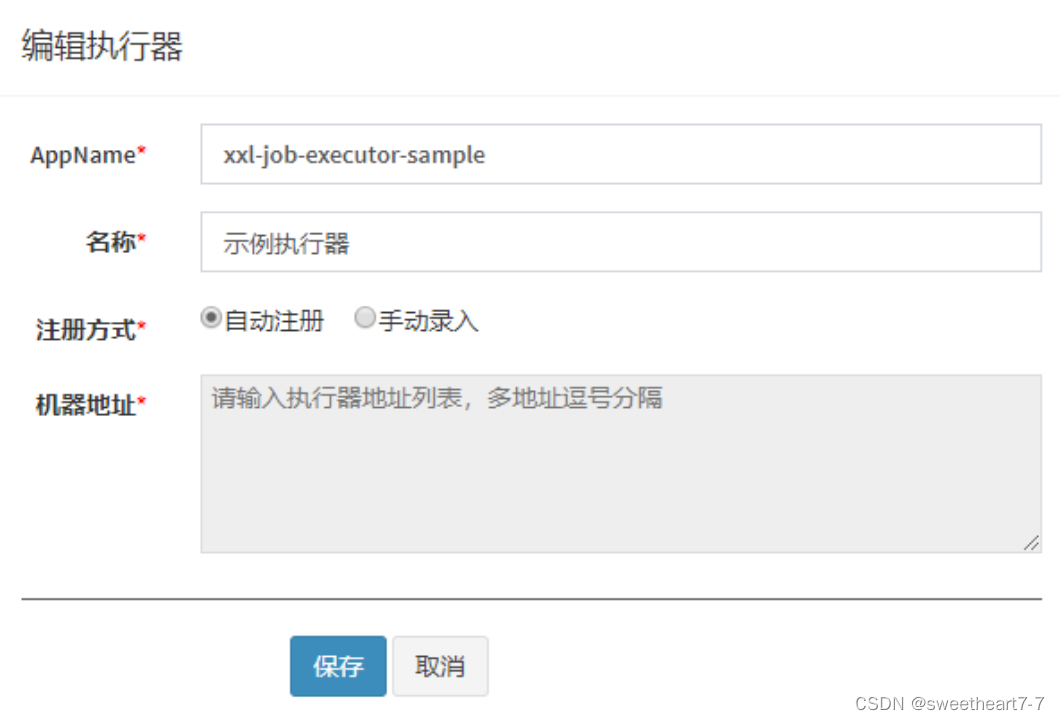
- 执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能;
- 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器
任务详解-基础配置
- 执行器:每个任务必须绑定一个执行器, 方便给任务进行分组
- 任务描述:任务的描述信息,便于任务管理;
- 负责人:任务的负责人;
- 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔

任务详解-调度配置
- 调度类型:
- 无:该类型不会主动触发调度;
- CRON:该类型将会通过CRON,触发任务调度;
- 固定速度:该类型将会以固定速度,触发任务调度;按照固定的间隔时间,周期性触发;

任务详解-基础配置
-
运行模式:
BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 -
“JobHandler” 属性匹配执行器中任务;
JobHandler:运行模式为 “BEAN模式” 时生效,对应执行器中新开发的 JobHandler 类“@JobHandler”注解自定义的 value 值; -
执行参数:任务执行所需的参数;

任务详解-阻塞处理策略
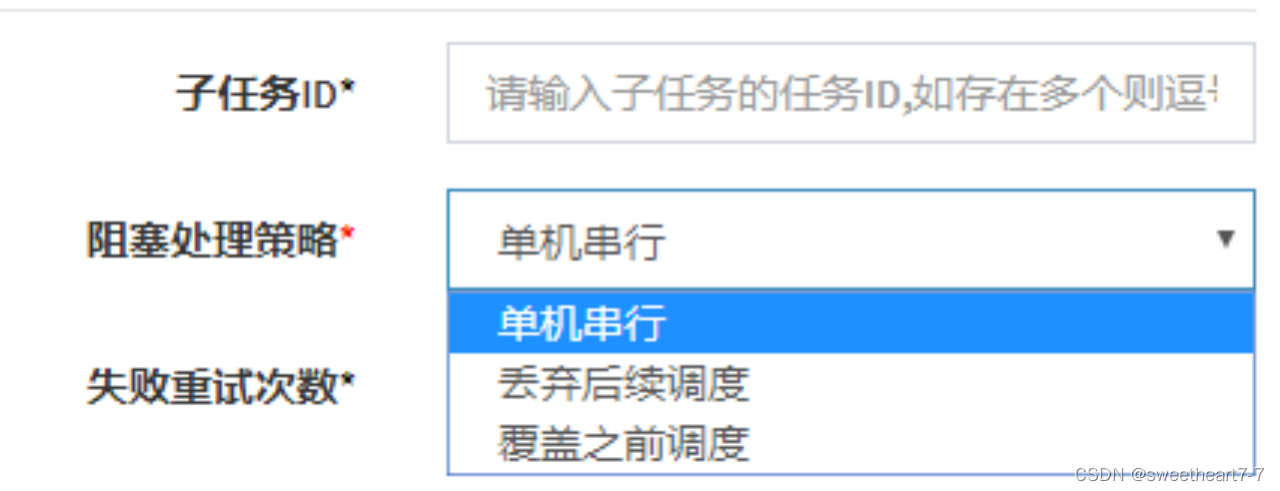
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO(First Input First Output)队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
任务详解-路由策略
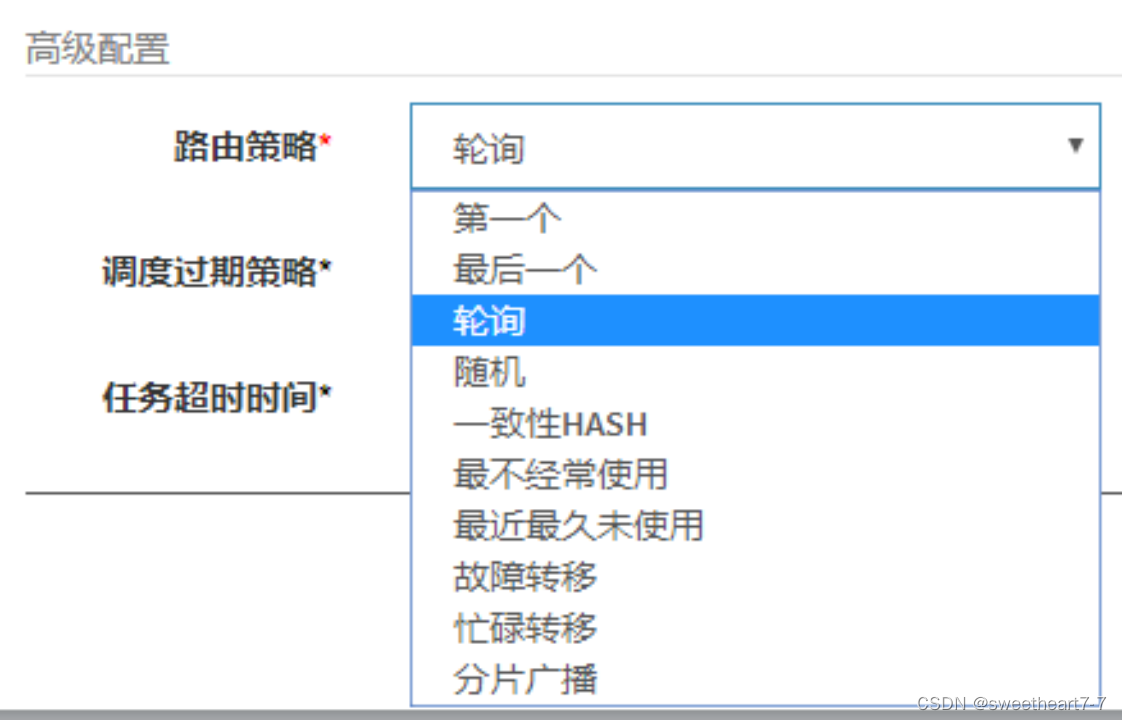
当执行器集群部署时,提供丰富的路由策略,包括;
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询):
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
路由策略
路由策略(轮询)-案例
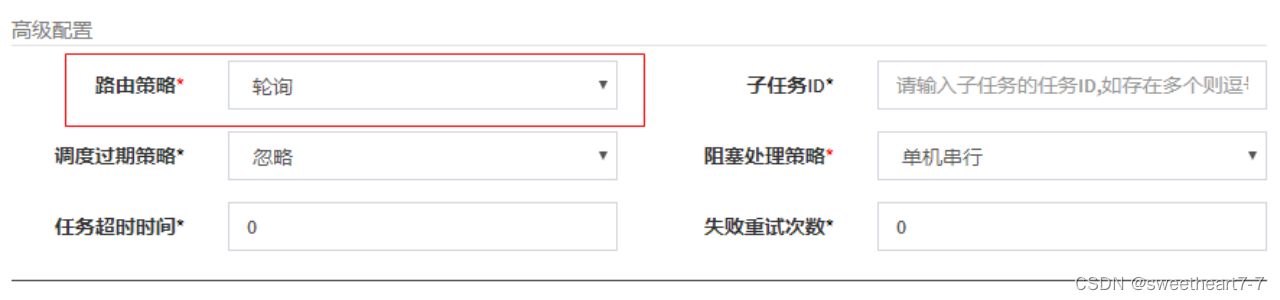
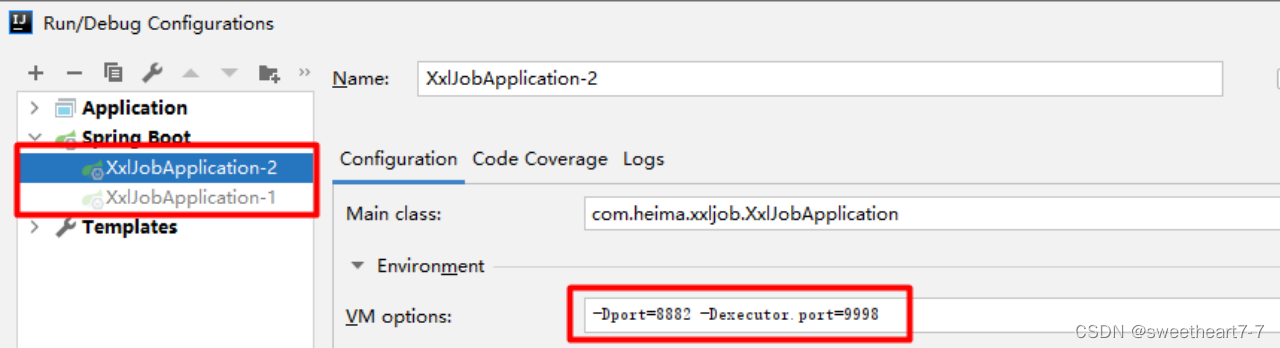
- 修改任务为轮询
- 启动多个微服务
路由策略(分片广播)
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务
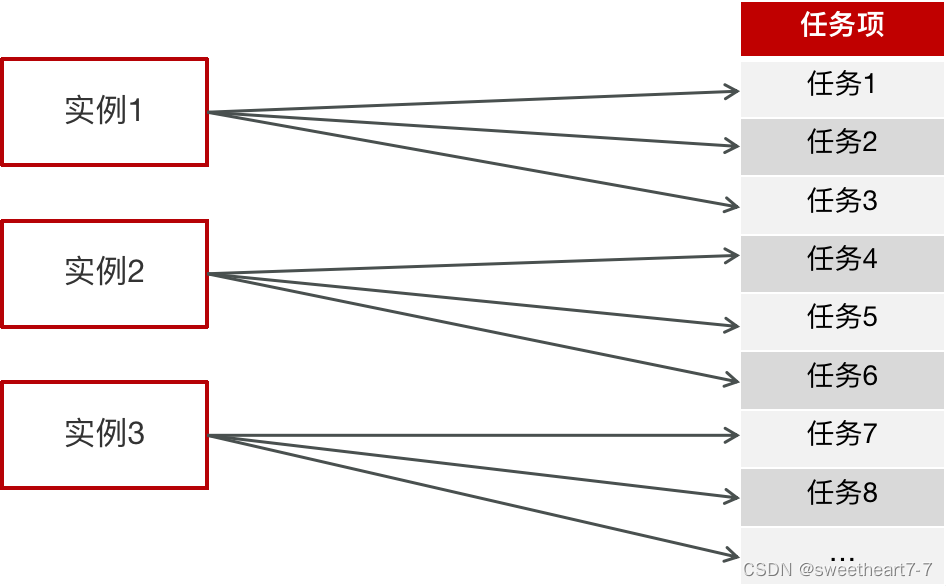
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务
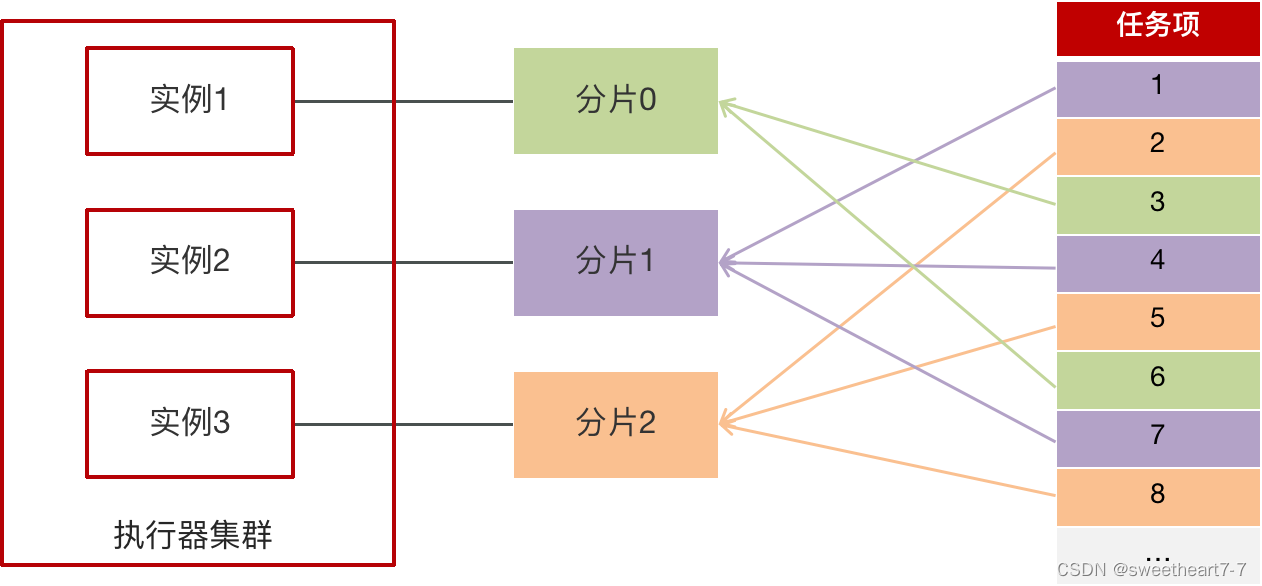
路由策略(分片广播)-案例
需求:让两个节点同时执行10000个任务,每个节点分别执行5000个任务
①:创建分片执行器

②:创建任务,路由策略为分片广播

③:分片广播代码
分片参数
- index:当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
- total:总分片数,执行器集群的总机器数量;
