江西建设质量检测网站关于网站建设实验报告
基于卷积神经网络的立体视频编码质量增强方法_余伟杰
- 提出的基于TSAN的合成视点质量增强方法
- 全局信息提取流
- 像素重组
- 局部信息提取流
- 多尺度空间注意力机制
- 提出的基于RDEN的轻量级合成视点质量增强方法
- 特征蒸馏注意力块
- 轻量级多尺度空间注意力机制
- 概念
- 扭曲失真
- 孔洞问题
- 失真和伪影
提出的基于TSAN的合成视点质量增强方法
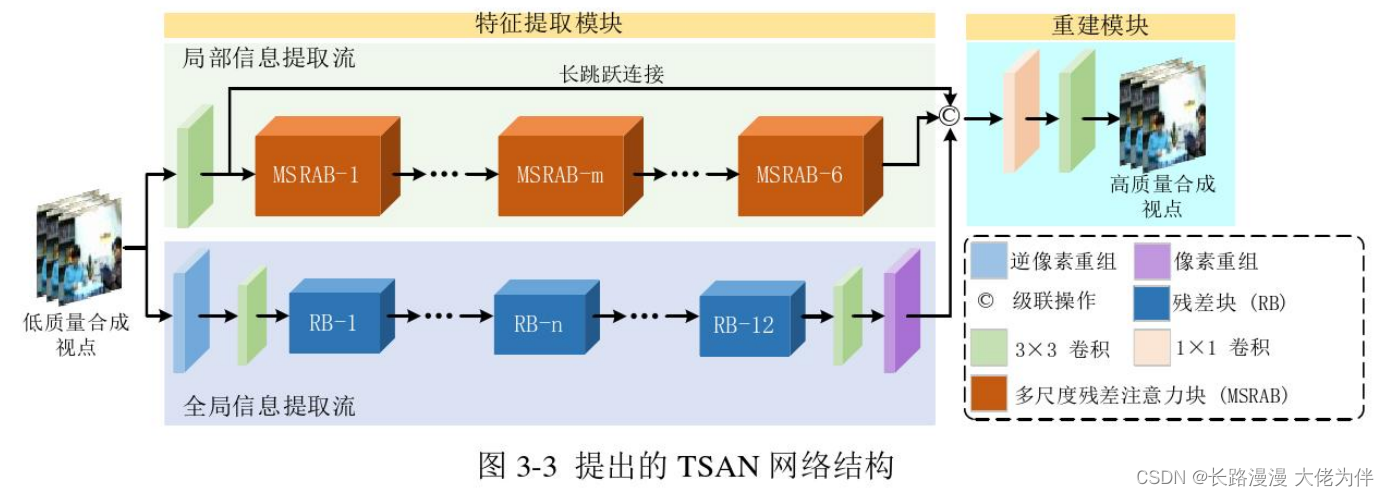
提出的网络包含两个模块:特征提取模块和重建模块。
为了从低质量合成视点中提取局部和全局信息,特征提取模块中提出了两条信息流,分别为局部信息提取流和全局信息提取流。
随着网络层数的增长,提取的特征在传输的过程中可能消失,这会降低网络模型的表达能力,为了提升特征的有效性和复用性,受人眼视觉系统的启发,在局部信息提取流中提出了一种多尺度残差注意力块
全局信息提取流
基于单一信息流的神经网络缺乏全局信息,全局信息可以将合成视点视作整体以概括整个对象,所以网络的学习能力受到限制。
通过使用全局信息,更多的上下文信息被学习到,从而帮助网络消除低质量合成视点中出现的扭曲失真。
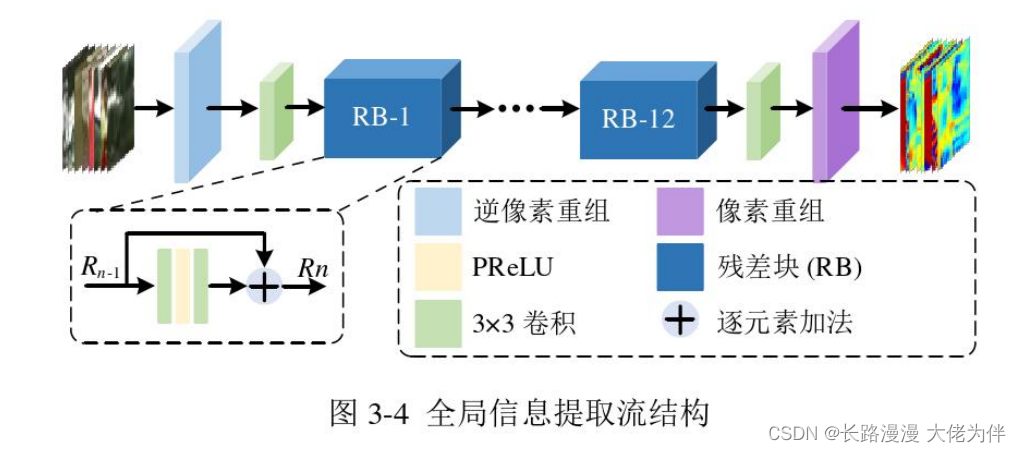 首先,将低质量合成视点图下采样为子块,接着将这些字块送入12个完全相同的残差块(Residual Block,RB)中以提取特征,最后,通过一个上采样层反转下采样过程。为了在建模能力和训练速度上做到平衡,下采样和上采样因子被设置为2。
首先,将低质量合成视点图下采样为子块,接着将这些字块送入12个完全相同的残差块(Residual Block,RB)中以提取特征,最后,通过一个上采样层反转下采样过程。为了在建模能力和训练速度上做到平衡,下采样和上采样因子被设置为2。
对于下采样过程,本文网络中使用了像素逆重组(pixel-unshuffle)层。不同于池化,步长为2的卷积以及双线性插值方法,pixel-unshuffle操作在下采样过程中不会造成任何的信息丢失,其通过将空间特征重新排列为通道来获得下采样的子图像。
此外,pixel-unshuffle操作不但可以扩大感受野,还可以降低显存使用率。
像素逆重组(pixel-unshuffle)
像素重组
为了将两条信息流中的特征级联起来,全局信息流的输出特征需要上采样至原始大小,由于像素重组(pixel-shuffle)操作l54生成更多真实细节信息,所以本文上采样使用pixel-shuffle操作。pixel-shuffle通过使用卷积层生成多个通道,然后将其重塑为高级特征,一个2倍pixel-shuffle操作的例子如图3-6所示
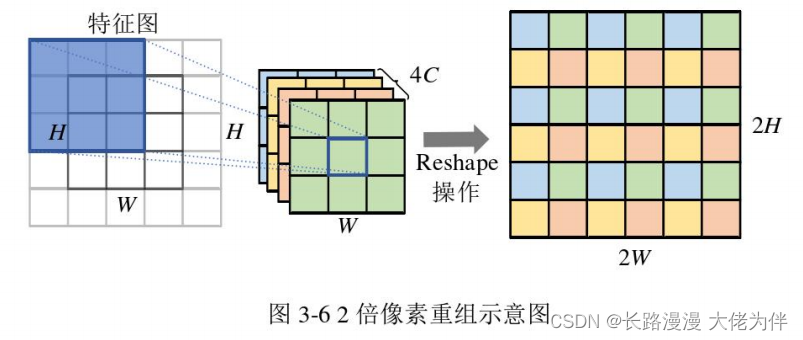
从图中可以看出,其输入特征图尺寸为W×Hx C,首先通过一次卷积操作将输入尺寸转变为WxH×4C,接着通过重塑操作将特征图尺寸转变为2W×2H ×C。
局部信息提取流
。由于局部特征之间的相关性很小,并且图像中存在大量的局部信息,因此学习更多的局部信息有助于恢复合成视点的质量。提出的局部信息提取流的结构如图3-7所示
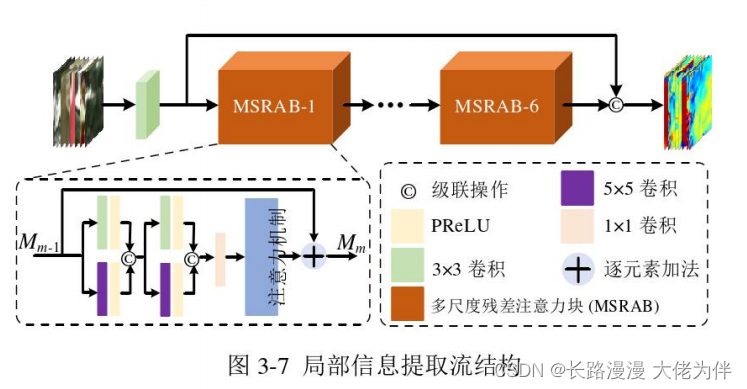 受 HVS 的启发,本文提出了一种新颖的多尺度空间注意力机制,该机制被集成到MSRB中,以利用更多有用的特征信息来增强低质量的合成视点效果。通过从空间维度考虑特征之间的相互依赖性,特征图中的关键信息可以被提取。
受 HVS 的启发,本文提出了一种新颖的多尺度空间注意力机制,该机制被集成到MSRB中,以利用更多有用的特征信息来增强低质量的合成视点效果。通过从空间维度考虑特征之间的相互依赖性,特征图中的关键信息可以被提取。
此外,为了提高结果的准确性,将原始块中使用的激活函数ReLU替换为PReLU
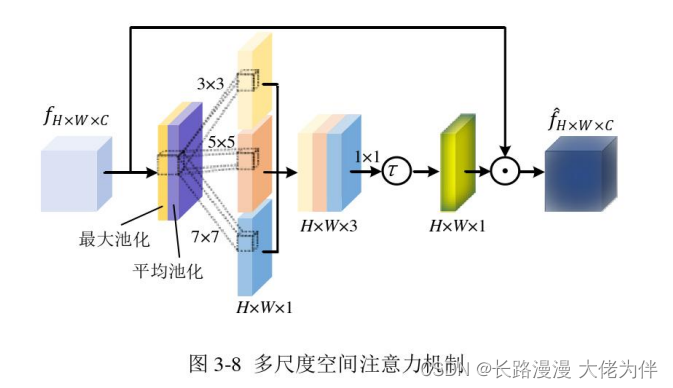
多尺度空间注意力机制
本文提出了一种多尺度空间注意机制,通过合并多个尺度的感受野以更好地在空间域中学习特征之间的关系。在提出的多尺度空间注意机制中,较大的感受野对于引导网络学习孔洞,而较小的感受野则更适合于提取背景特征,所提出的多尺度空间注意机制的结构如图3-8所示。
提出的基于RDEN的轻量级合成视点质量增强方法
特征蒸馏注意力块
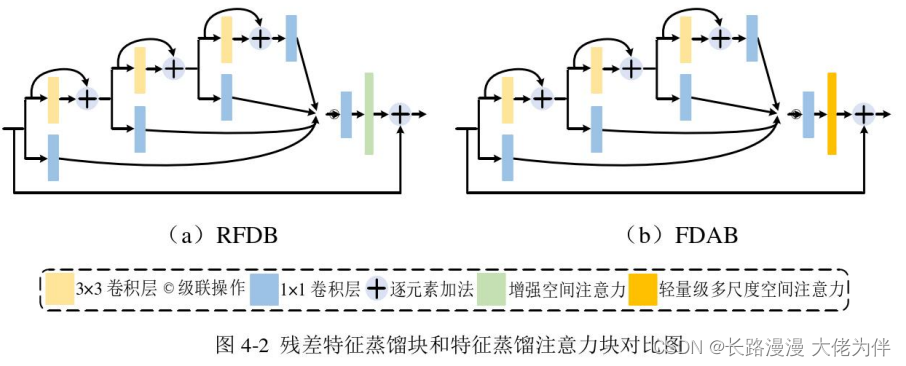
多尺度残差注意力块可以充分利用特征信息增强低质量合成视点的效果,但由于块中使用不同大小的卷积核共享和重用信息,使得网络存在冗余参数,计算不够灵活和高效,有进一步提升的空间。
为了降低模型复杂度,同时保证模型特征提取的性能,文献[6!提出了残差特征蒸馏块(Residual Feature Distillation Block,RFDB),通过通道分离和特征蒸馏的方式显著降低参数量。
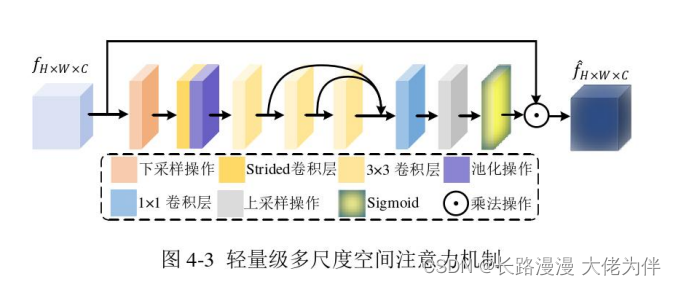
轻量级多尺度空间注意力机制
提出了轻量级多尺度空间注意力机制,其结构如图4-3所示。首先通过一个1×1的卷积进行降维,以减少通道数,然后采用步长为2的跨步卷积和最大池化操作减少空间尺寸,接着采用跳跃连接的方式串联三个3×3卷积层,以模拟3×3,5×5和7×7的多尺度卷积核。由于开始采用了池化操作,与之对应,添加了上采样层以恢复空间尺寸,此外,采用了1×1的卷积以恢复同通道尺寸,通过 sigmoid激活函数得到2D空间注意力图,以计算特征图中被强调的部分。最后,学习到的权重W被用于自适应地调整输入特征图fwxwxc。整个注意
概念
扭曲失真
在 DIBR操作过程中,不正确的深度值可能会使合成视点中的位置发生移动,这种情况被称为扭曲失真。
孔洞问题
参考视点中被前景物体遮盖的区域在合成视点变得可见,这导致了孔洞问题。
失真和伪影
同时纹理视频在视频压缩后会发生几何形变,引入多种失真和伪影。