如何做网站里的子网站空间商网站
文理学院数据库应用技术实验报告0
实验内容
- 打开cmd,利用MySQL命令连接MySQL服务器。
mysql -u root -p
- 查看当前MySQL服务实例使用的字符集(character)。
SHOW VARIABLES LIKE 'character_set_server';

- 查看当前MySQL服务实例支持的字符序(collation)。
SHOW VARIABLES LIKE 'collation_server';

- 创建一个以自己名字命名的数据库,使用默认设置。
要求:第一次不加if not exists,第二次加if not exists,第三次不加if not exists,并将三次截图都放在报告中。
CREATE DATABASE yangjinxue;

CREATE DATABASE IF NOT EXISTS yangjinxue;

CREATE DATABASE yangjinxue; -- 如果数据库不存在才会创建

- 查看数据库。
要求:1.查看所有的数据库;
(1)
SHOW DATABASES;

2.查看以’s’开头的数据库;
(1)
SELECT database() LIKE 's%';

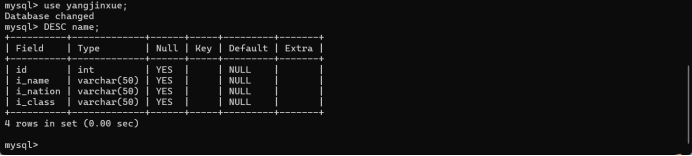
3.查看自己建立的数据库结构。
(1)
use yangjinxue;DESC name;
- 选择当前的数据库。
要求:
1.选择自己建立的数据库,并查看其数据库中的表;
use yangjinxue;SHOW TABLES;

2.选择一个其他数据库,并查看其数据库中的表。
use books;SHOW TABLES;

- 修改数据库;
要求:
1.将自己创建的数据库的字符集修改为UTF8,并查看;
use yangjinxue;ALTER DATABASE yangjinxue CHARACTER SET utf8 COLLATE utf8_general_ci;

2.将自己创建的数据库的字符序修改为gbk_chinese_ci。
use yangjinxue;ALTER DATABASE yangjinxue CHARACTER SET = gbk COLLATE = gbk_chinese_ci;

- 删除数据库。
要求:删除自己创建的数据库,第一次不加if exists,第二次加if exists,第三次不加if exists,并将三次截图都放在报告中。
(1)
DROP DATABASE YangJinXue;

(2)
DROP DATABASE IF EXISTS yangjinxue;

(3)
DROP DATABASE YangJinXue;
