网站信息填写要求做外贸网站用哪些小语种
简介:
简单工厂模式,它提供了一个用于创建对象的接口,但具体创建的对象类型可以在运行时决定。这种模式通常用于创建具有共同接口的对象,并且可以根据客户端代码中的参数或配置来选择要创建的具体对象类型。
在简单工厂模式中,有一个专门的类负责创建其他类的实例,这个类称为工厂类。被创建的实例通常都具有共同的父类。工厂类中有一个用于创建对象的静态工厂方法,系统可以根据该方法所传入的参数来动态决定应该创建出哪一个产品类的实例。
以汽车生产为例,简单工厂模式可以模拟该生产过程。我们将汽车抽象为一个产品接口,不同品牌的汽车则具体实现该接口并提供各自的功能。工厂类负责根据传入的品牌参数来创建相应的汽车对象。
以下是简单工厂模式的步骤:
1、定义产品接口:首先定义一个产品接口,例如“汽车”,它包含一些公共的方法,如“启动”、“刹车”等。
2、实现具体产品类:针对不同的品牌,创建具体的实现类来实现产品接口。例如,“奔驰”和“宝马”都实现了“汽车”接口,并提供了各自特有的功能。
3、创建工厂类:创建一个工厂类,它包含一个静态工厂方法,用于根据传入的品牌参数来创建相应的汽车对象。例如,在“奔驰”工厂中,我们创建了一个静态方法“createCar”,它根据传入的品牌来实例化相应的汽车对象。
4、使用工厂类创建产品对象:客户端代码直接调用工厂类的静态工厂方法来创建需要的汽车对象,而无需关心具体的品牌和创建细节。例如,我们调用“奔驰”工厂的“createCar”方法,并传入型号参数“E-260-L”,即可得到一个奔驰E260L对象。
简单工厂模式的优点:它能将对象的创建和对象本身业务处理分离,降低系统的耦合度,使得两者修改起来都相对容易。同时,由于工厂方法是静态方法,使用起来很方便,只需通过工厂类类名直接调用即可,无需了解对象的创建细节。它可以在不修改客户端代码的情况下扩展新的产品类型,因为新产品只需实现抽象产品接口,并在工厂类中添加相应的创建逻辑即可。而不需要修改其它已经存在的代码,这样就保持了良好的封装性。
简单工厂模式的缺点:如果Shape类型的数量很多,那么ShapeFactory类就会变得很庞大,而且所有创建对象的逻辑都集中在一个类中,破坏了代码的模块化,破坏了“开闭原则”。
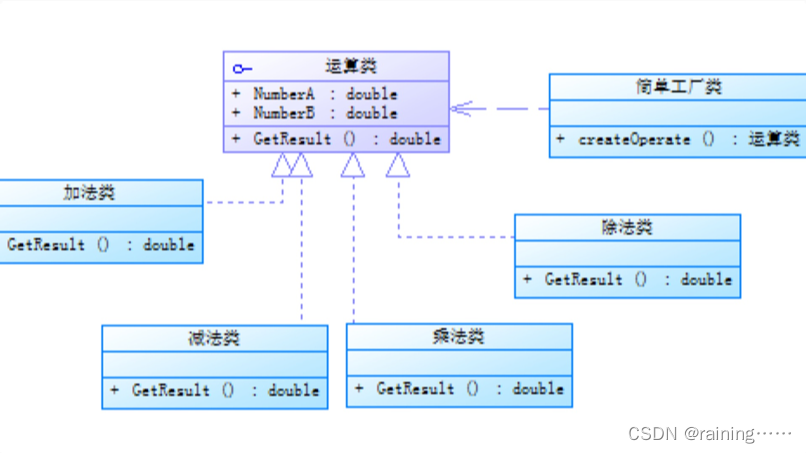
示例:
一、C#简单工厂模式
以下是一个示例,展示了如何在C#中实现简单工厂模式:
// 接口
public interface Shape
{ void Draw();
} // 实现接口的实体类
public class Circle : Shape
{ public void Draw() { Console.WriteLine("绘制一个圆形"); }
} public class Rectangle : Shape
{ public void Draw() { Console.WriteLine("绘制一个矩形"); }
} // 工厂类,创建实体类的对象
public class ShapeFactory
{ // 通过GetShape方法来根据传入的字符串来返回相应的Shape类型的对象 public Shape GetShape(string type) { if (type == "Circle") { return new Circle(); } else if (type == "Rectangle") { return new Rectangle(); } else { throw new ArgumentException("无效的图形类型"); } }
}
//使用这个工厂,你可以在运行时决定创建哪种类型的 Shape。例如:
class FactoryPatternDemo
{static void Main(string[] args){ShapeFactory shapeFactory = new ShapeFactory(); Shape shape1 = shapeFactory.GetShape("Circle"); shape1.Draw(); // 输出"绘制一个圆形" Shape shape2 = shapeFactory.GetShape("Rectangle"); shape2.Draw(); // 输出"绘制一个矩形" }
}二、java简单工厂模式
以下是一个示例,展示了如何在Java中实现简单工厂模式:
// 接口
public interface Shape { void draw();
}
// 实现接口的实体类
public class Circle implements Shape { @Override public void draw() { System.out.println("绘制一个圆形"); }
} public class Rectangle implements Shape { @Override public void draw() { System.out.println("绘制一个矩形"); }
}
// 工厂类,创建实体类的对象
public class ShapeFactory { // 通过getShape方法来根据传入的字符串来返回相应的Shape类型的对象 public Shape getShape(String type) { if (type.equalsIgnoreCase("CIRCLE")) { return new Circle(); } else if (type.equalsIgnoreCase("RECTANGLE")) { return new Rectangle(); } else { throw new IllegalArgumentException("无效的形状类型"); } }
}
//然后我们就可以这样使用这个工厂类创建Shape对象:
public class FactoryPatternDemo { public static void main(String[] args) { ShapeFactory shapeFactory = new ShapeFactory(); Shape shape1 = shapeFactory.getShape("CIRCLE"); shape1.draw(); // 输出"绘制一个圆形" Shape shape2 = shapeFactory.getShape("RECTANGLE"); shape2.draw(); // 输出"绘制一个矩形" }
}
三、javascript简单工厂模式
在JavaScript 中,它使用一个共同的接口来实例化不同类型的对象,而无需直接使用具体类。在工厂模式中,您可以创建一个工厂类来负责创建对象,而无需暴露创建逻辑。
以下是一个示例,展示了如何在JavaScript中实现简单工厂模式:
// Car 接口
class Car { constructor(name) { this.name = name; } start() { console.log(this.name + ' started'); } stop() { console.log(this.name + ' stopped'); }
} // CarFactory 工厂类
class CarFactory { constructor() { this.cars = {}; } // 创建轿车对象 createCar(name, type='Sedan') { if (!this.cars[type]) { this.cars[type] = new Car(type); } return this.cars[type]; } // 创建卡车对象 createTruck(name, type='Pickup') { if (!this.cars[type]) { this.cars[type] = new Car(type); } return this.cars[type]; }
}
//接下来,我们使用 CarFactory 工厂类来制造不同类型的汽车:
// 创建 CarFactory 实例
const carFactory = new CarFactory(); // 制造轿车
const sedan = carFactory.createCar('Alice', 'Sedan');
sedan.start(); // 输出 "Sedan started"
sedan.stop(); // 输出 "Sedan stopped" // 制造卡车
const truck = carFactory.createCar('Bob', 'Truck');
truck.start(); // 输出 "Pickup started"
truck.stop(); // 输出 "Pickup stopped"四、C++简单工厂模式
在C++中,可以通过以下步骤来实现简单工厂模式:
1、定义一个抽象基类(或接口),其中包含所有派生类的公共方法。这个抽象基类可以看作是工厂的公共接口,它不知道具体对象的类型。
2、创建多个派生类,这些派生类实现了抽象基类中的所有公共方法,每个派生类具有不同的状态和行为。
3、创建一个工厂类,它包含一个用于创建对象的纯虚函数。这个纯虚函数根据传入的参数类型来创建相应的派生类对象,并返回该对象的指针。
4、在客户端代码中,通过调用工厂类的纯虚函数来创建对象。由于客户端代码不知道具体对象的类型,因此可以使用抽象基类的指针来操作这些对象。
以下是一个示例,展示了如何在C++中实现简单工厂模式:
#include <iostream> // 抽象基类
class Shape {
public: virtual void draw() = 0;
}; // 圆形派生类
class Circle : public Shape {
public: void draw() override { std::cout << "绘制圆形" << std::endl; }
}; // 矩形派生类
class Rectangle : public Shape {
public: void draw() override { std::cout << "绘制矩形" << std::endl; }
}; // 工厂类
class ShapeFactory {
public: // 根据传入的参数类型来创建相应的对象,并返回该对象的指针 static Shape* createShape(const std::string& type) { if (type == "Circle") { return new Circle(); } else if (type == "Rectangle") { return new Rectangle(); } else { throw std::invalid_argument("无效的形状类型"); } }
}; int main() { // 创建圆形对象 Shape* circle = ShapeFactory::createShape("Circle"); circle->draw(); // 输出"绘制圆形" delete circle; // 创建矩形对象 Shape* rectangle = ShapeFactory::createShape("Rectangle"); rectangle->draw(); // 输出"绘制矩形" delete rectangle; return 0;
}五、python简单工厂模式
在Python中,工厂模式通常是通过函数或类来创建其他类的实例。简单工厂模式是一种常见的工厂模式,它通过一个单独的工厂类来创建产品对象,这个工厂类一般用来创建与环境有关的具体产品。
下面是一个Python中简单工厂模式的例子:
class Product(object): def operation(self): pass class ConcreteProduct1(Product): def operation(self): return "ConcreteProduct1 operation" class ConcreteProduct2(Product): def operation(self): return "ConcreteProduct2 operation" class Factory: @staticmethod def create_product(product_type): if product_type == "type1": return ConcreteProduct1() elif product_type == "type2": return ConcreteProduct2() else: return None def client_code(factory=Factory): product = factory.create_product("type1") print(product.operation()) if __name__ == "__main__": client_code()
六、Go简单工厂模式
以下是一个示例,展示了如何在go中实现简单工厂模式:
// 抽象产品接口
interface Product { void use();
} // 具体产品类1
class ConcreteProduct1 implements Product { public void use() { System.out.println("使用具体产品1"); }
} // 具体产品类2
class ConcreteProduct2 implements Product { public void use() { System.out.println("使用具体产品2"); }
} // 工厂类
class Factory { public Product createProduct(String type) { if (type.equals("product1")) { return new ConcreteProduct1(); } else if (type.equals("product2")) { return new ConcreteProduct2(); } else { throw new IllegalArgumentException("无效的产品类型"); } }
} // 客户端代码
public class Client { public static void main(String[] args) { Factory factory = new Factory(); Product product1 = factory.createProduct("product1"); product1.use(); // 输出:使用具体产品1 Product product2 = factory.createProduct("product2"); product2.use(); // 输出:使用具体产品2 }
}
七、PHP简单工厂模式
以下是一个示例,展示了如何在PHP中实现简单工厂模式:
<?php // 产品接口
interface Product { public function useProduct();
} // 具体产品类 1
class ConcreteProduct1 implements Product { public function useProduct() { echo "使用具体产品1\n"; }
} // 具体产品类 2
class ConcreteProduct2 implements Product { public function useProduct() { echo "使用具体产品2\n"; }
} // 工厂类
class Factory { public static function createProduct($type) { if ($type === 'product1') { return new ConcreteProduct1(); } elseif ($type === 'product2') { return new ConcreteProduct2(); } else { throw new Exception('无效的产品类型'); } }
} // 客户端代码
function clientCode() { $product1 = Factory::createProduct('product1'); $product1->useProduct(); // 输出:使用具体产品1 $product2 = Factory::createProduct('product2'); $product2->useProduct(); // 输出:使用具体产品2
} // 调用客户端代码
clientCode();
?>《完结》