陕西省交通建设集团西长分公司网站建筑设计官网
数据链路层概述
数据链路层以帧为单位传输数据。
封装成帧:给网络层提供的协议数据单元添加帧头帧尾
差错检测:检错码封装在帧尾
可靠传输:尽管误码不能避免,但如果可以实现发送什么就接受什么,就叫可靠传输
封装成帧
帧头帧尾具有重要控制信息
帧头和帧尾的作用之一为帧定界
透明传输:数据链路层对上层交付的传输数据没有任何限制
 帧的数据部分应该尽量大,但也有上限。
帧的数据部分应该尽量大,但也有上限。
差错检测
比特差错:0->1 ,0->1
差错检测码(FCS)来检测是否数据出现差错
检错方法:
奇偶校验:添加奇偶校验位,使整个数据的1为奇数或者偶数。需要奇性改变才可检错。
循环冗余校验(CRC):生成多项式(必须包含最低次项)来进行计算校验,漏检率低。

检错码只能检错不能纠错。
可靠传输
不可靠传输服务:丢弃有误码的帧即可
可靠传输服务:想办法实现重发帧,直到能正确接收

可开传输的实现机制
停止- 等待协议(SW)
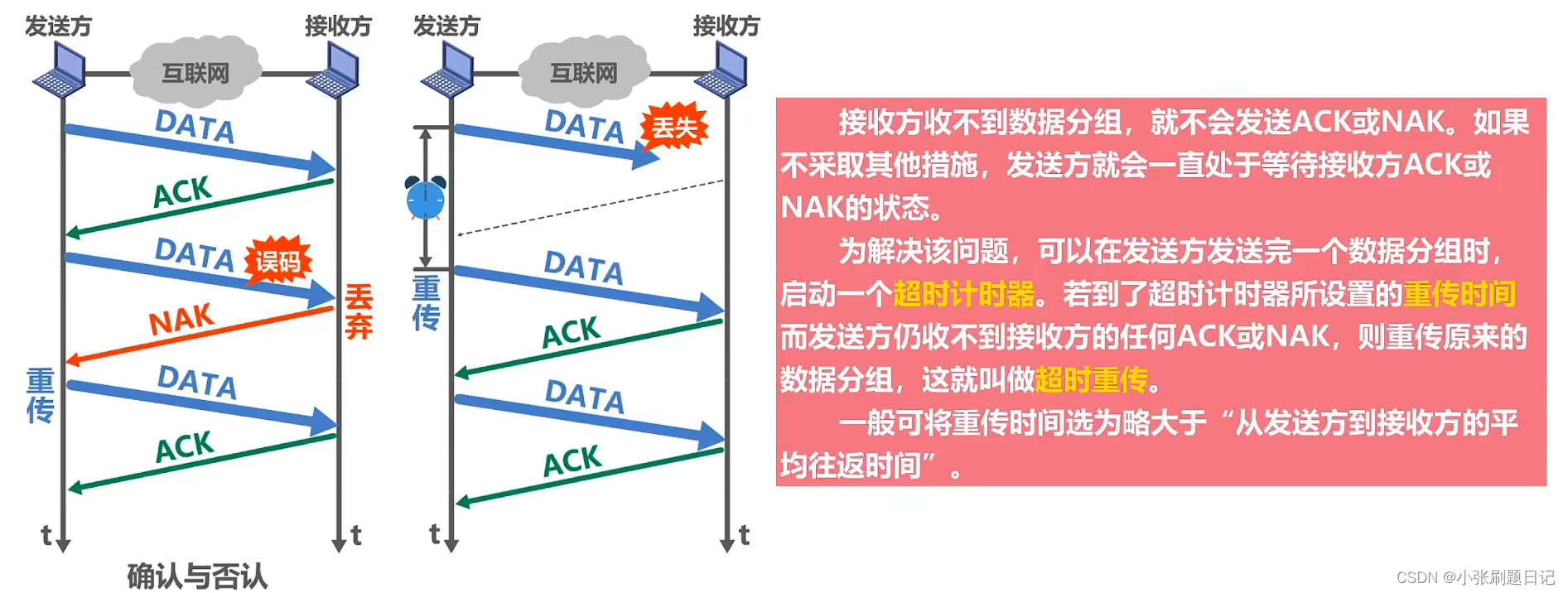
收到确认分组后,才能将数据从缓存删除。但如果会出现接收方的确认否认丢失,会造成分组重复,所以需要给分组带上序号,用来标识与上个发送数组是否相同。


SW协议信道利用率:发送端延时/(发送端发送延时+往返时间+接收端发送延时);信道利用率较低,(接收端发送延时一般可忽略)。
回退N帧协议(GBN)
采用流水线传输,提高信道利用率。
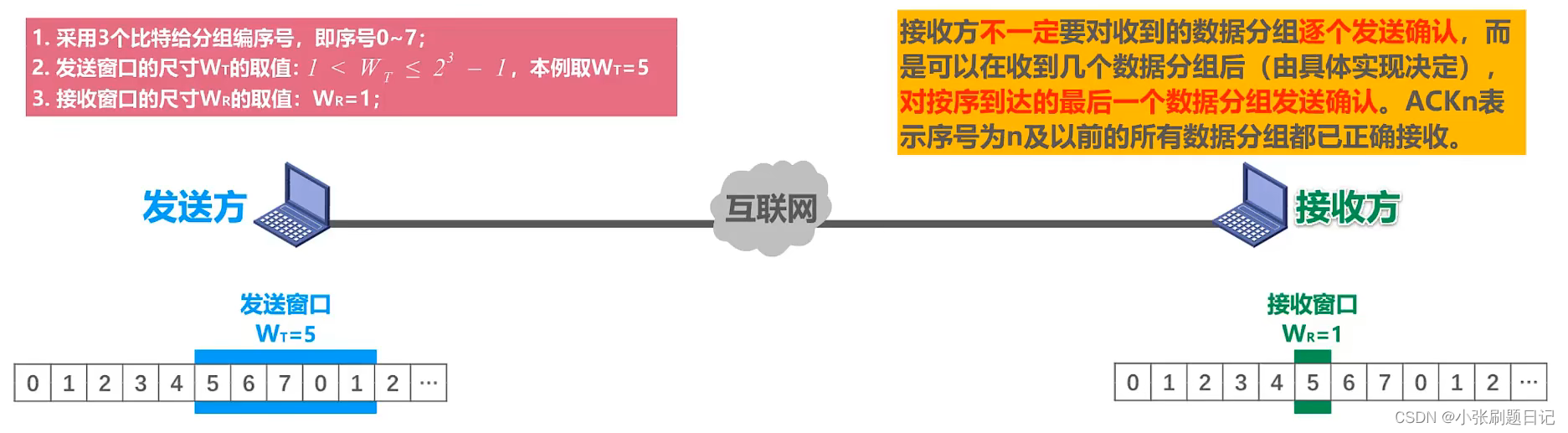
如果分组出错,接收方会再传输上一个接受分组的ACK,发送方重发。
如果发送窗口尺寸超过上限会导致接收方无法分辨新旧数据分组。

选择重传协议(SR)—— 对于GBN的改进
增大接收窗口的尺寸,这样需要进行逐一确认。

