网站建设朋友圈怎么写品牌建设的建议
一、简介
命令模式:将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等(附加控制)功能。
二、优点
- 动作封装
- 解耦发送者跟接受者
- 可扩展性
- 简化和集中错误处理
- 支持撤销和重做功能
- 易于实现组合命令
三、UML类图
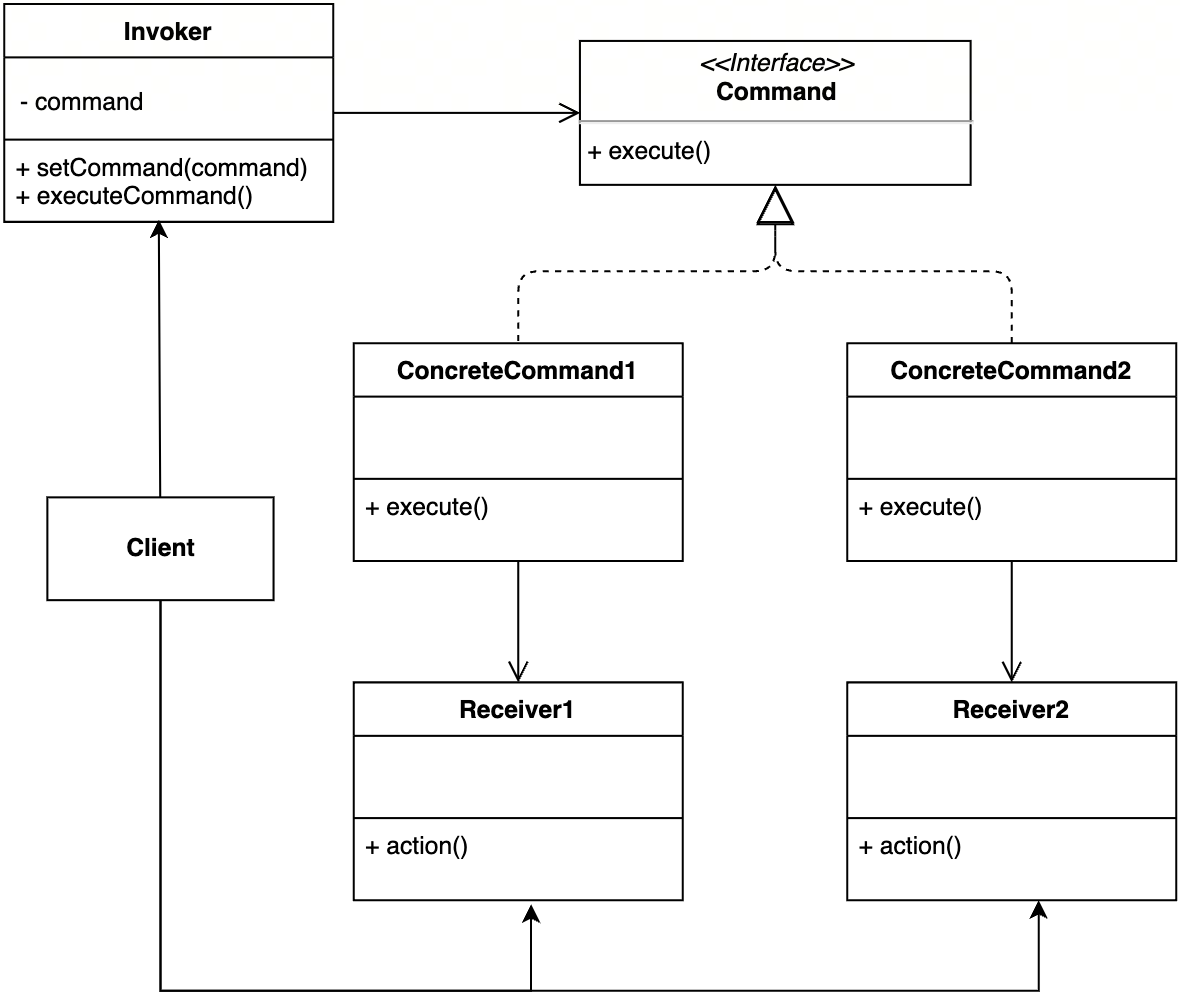
四、案例
家里有很多房间,有卧室和厨房等,用一套灯光管理系统同一管理所有灯的开关。
package mainimport "fmt"type Light interface {On()Off()
}type KitchenLight struct {
}func NewKitchenLight() *KitchenLight {return &KitchenLight{}
}func (*KitchenLight) On() {fmt.Println("Kitchen light is on")
}func (*KitchenLight) Off() {fmt.Println("Kitchen light is off")
}type LivingRoomLight struct {
}func NewLivingRoomLight() *LivingRoomLight {return &LivingRoomLight{}
}func (*LivingRoomLight) On() {fmt.Println("Living room light is on")
}func (*LivingRoomLight) Off() {fmt.Println("Living room light is off")
}type Command interface {Execute()Undo()
}type LightOnCommand struct {Lights []Light
}func NewLightOnCommand(lights []Light) LightOnCommand {return LightOnCommand{Lights: lights}
}func (loc *LightOnCommand) Execute() {for _, light := range loc.Lights {light.On()}
}func (loc *LightOnCommand) Undo() {for _, light := range loc.Lights {light.Off()}
}type LightOffCommand struct {Lights []Light
}func NewLightOffCommand(lights []Light) LightOffCommand {return LightOffCommand{Lights: lights}
}func (loc *LightOffCommand) Execute() {for _, light := range loc.Lights {light.Off()}
}func (loc *LightOffCommand) Undo() {for _, light := range loc.Lights {light.On()}
}func main() {kitchenLight := NewKitchenLight()livingRoomLight := NewLivingRoomLight()lightOnCommand := NewLightOnCommand([]Light{kitchenLight, livingRoomLight})lightOnCommand.Execute()lightOnCommand.Undo()lightOffCommand := NewLightOffCommand([]Light{kitchenLight, livingRoomLight})lightOffCommand.Execute()lightOffCommand.Undo()
}
五、对比
命令模式与策略模式的区别:在策略模式中,不同的策略具有相同的目的、不同的实现、互相之间可以替换。比如,BubbleSort、SelectionSort都是为了实现排序的,只不过一个是用冒泡排序算法来实现的,另一个是用选择排序算法来实现的。而在命令模式中,不同的命令具有不同的目的,对应不同的处理逻辑,并且互相之间不可替换。