免费网站建设基础步骤大连市工程建设信息网
此文分享一个python脚本,用于向指定的ssh服务器配置公钥,以达到免密登录ssh服务器的目的。
效果演示
-
🔥完整演示效果
-
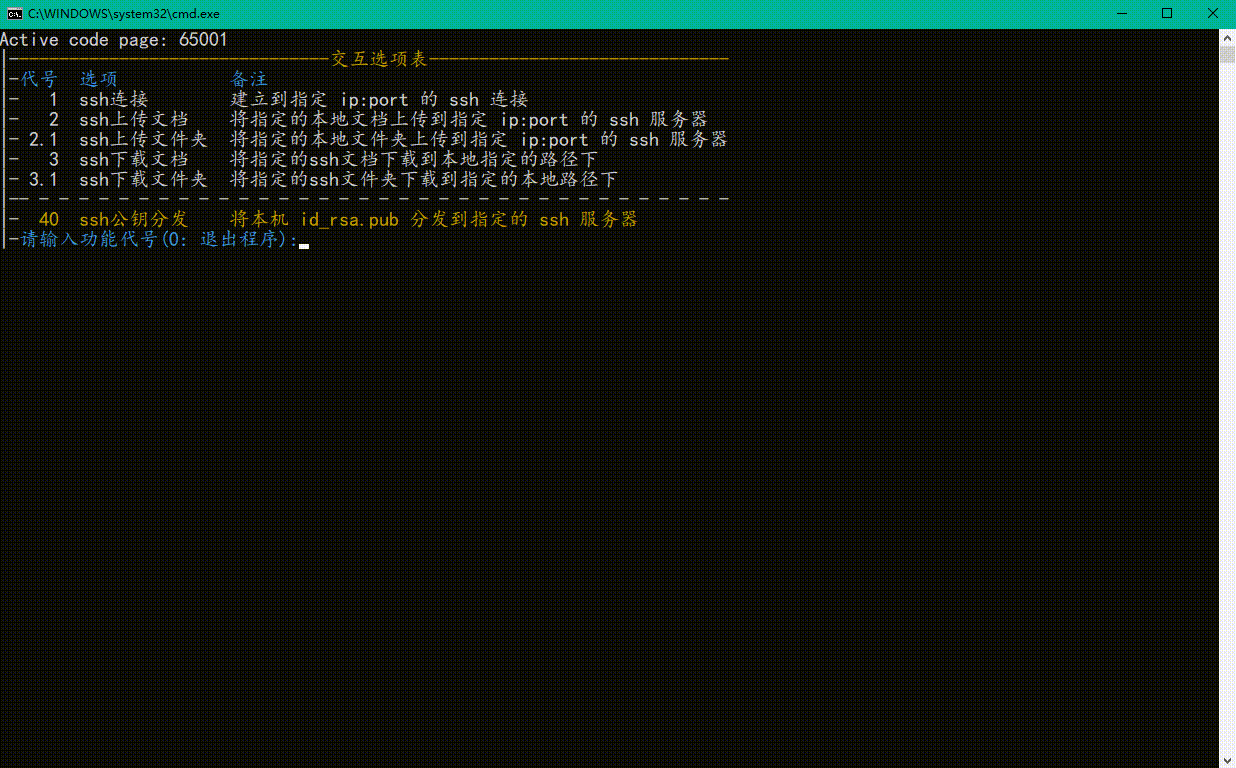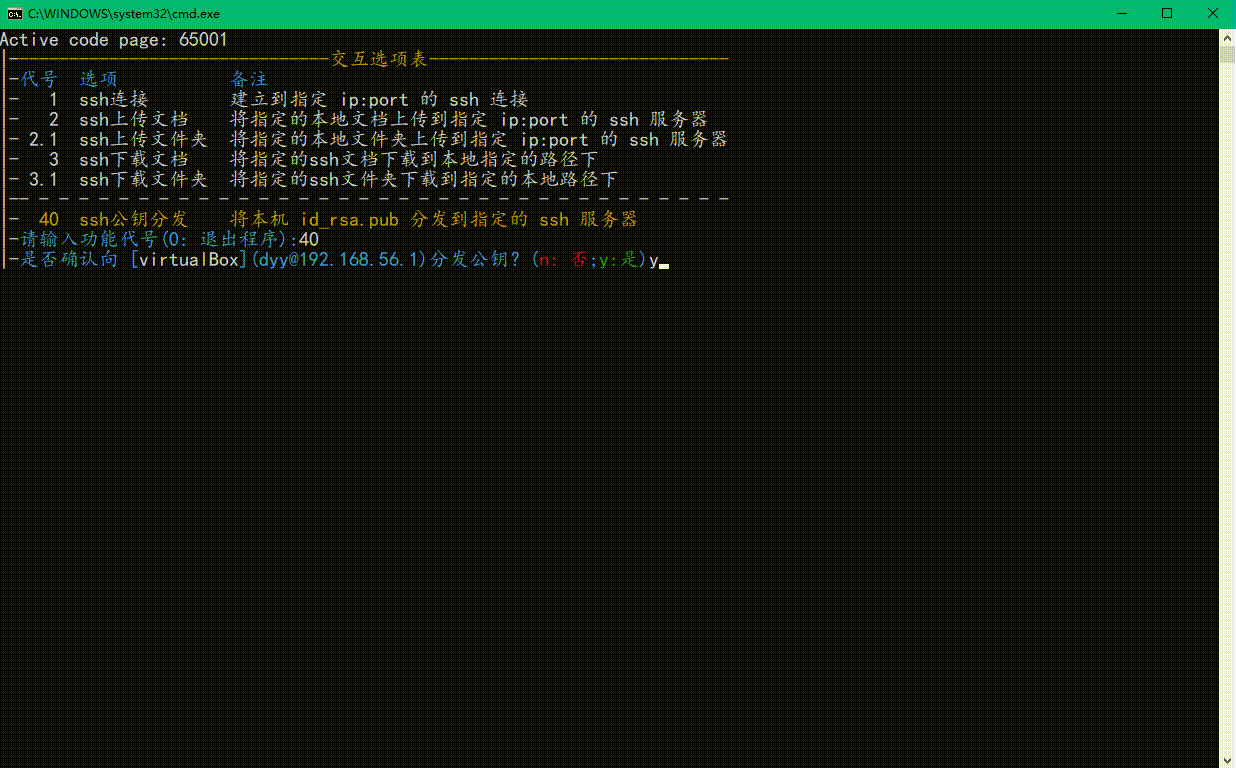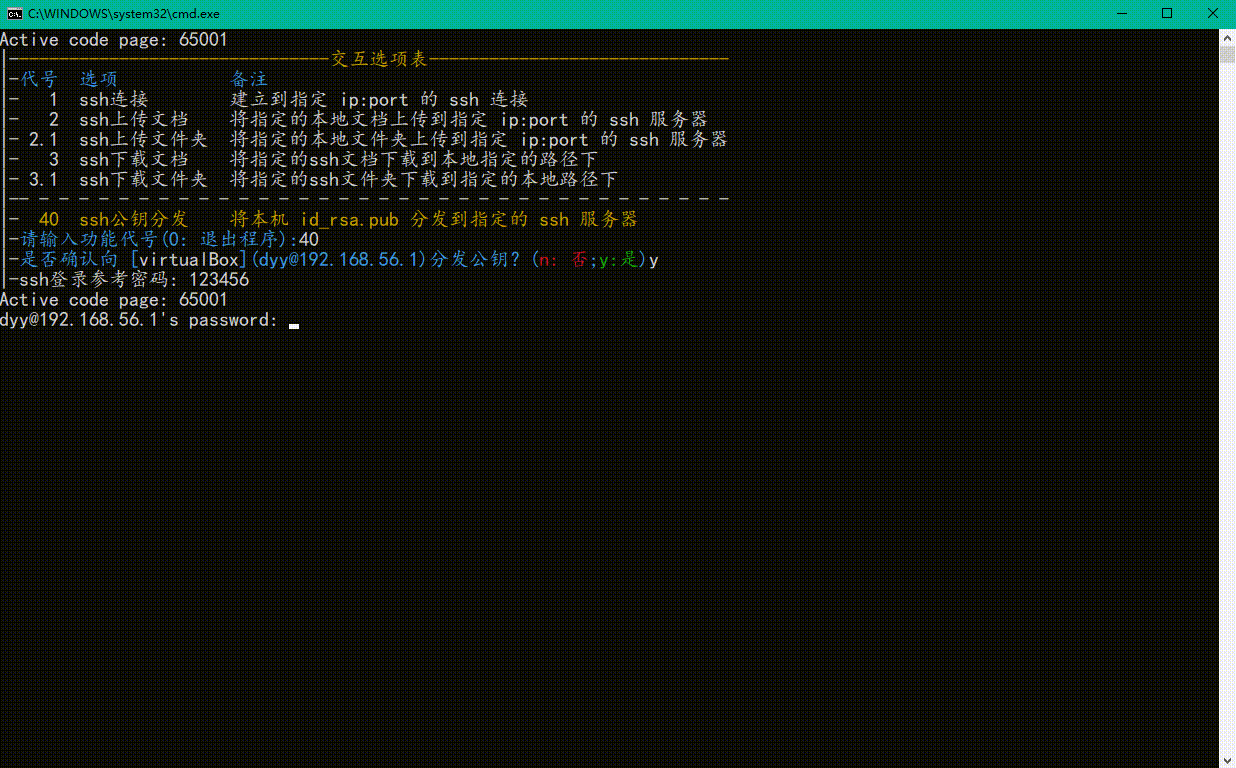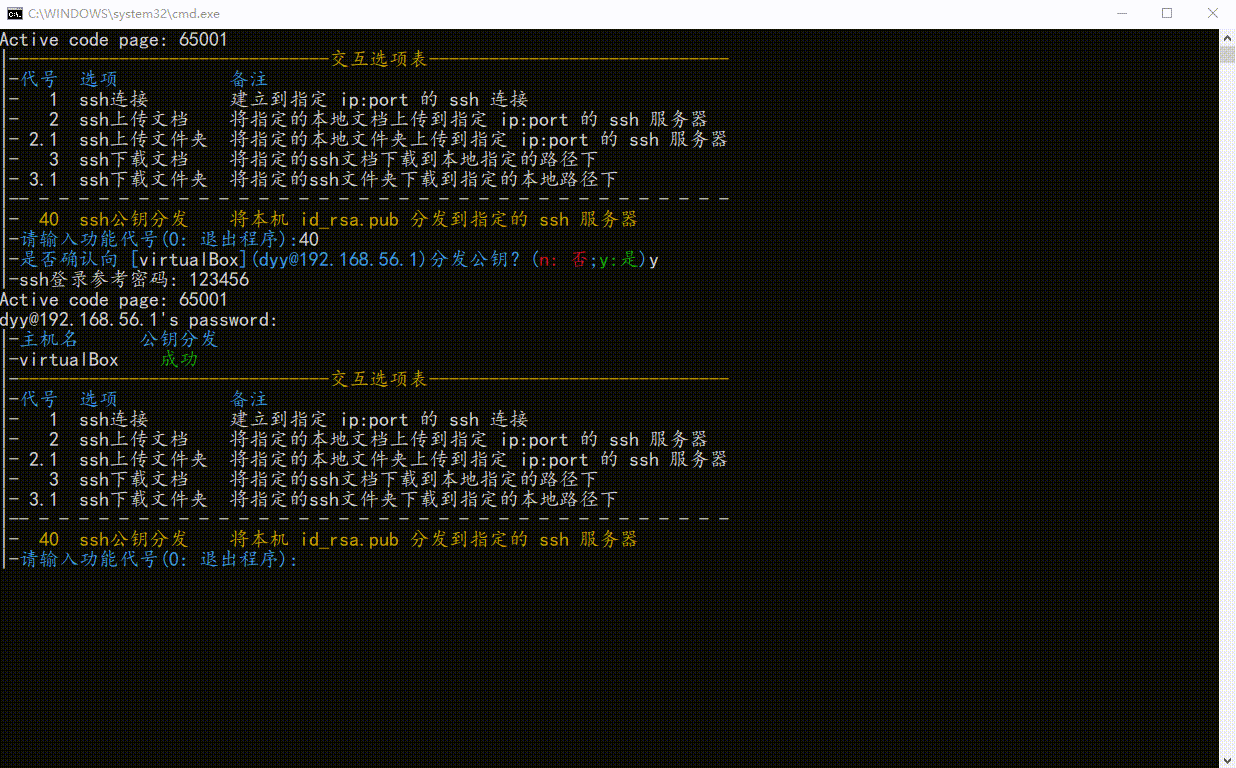
👇第一步,显然,我们需要选择功能
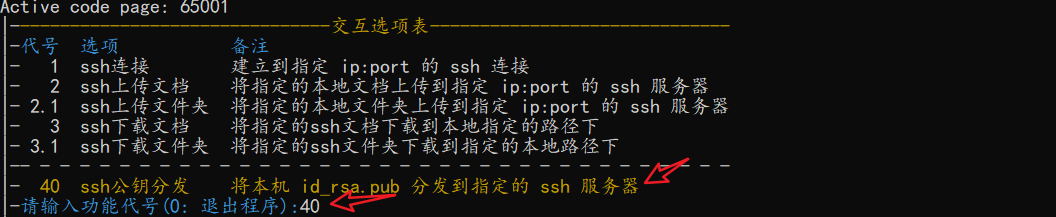
-
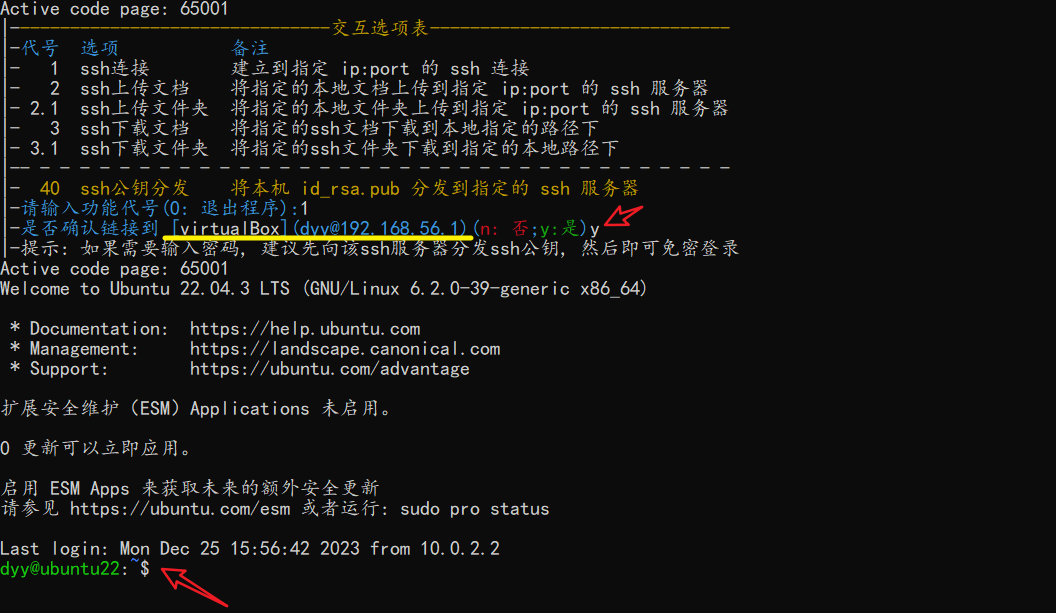
👇第二步,确认 or 选择ssh服务器

-
👇第三步,输入ssh登录密码,以完成公钥配置

-
👇验证,我们通过ssh登录该服务器时,已经不需要再输入密码了
配置文件
我们需要在配置文件中记录和管理一些配置信息,例如上文中提到的ssh登录信息,例如用于文档搜索的everything接口信息等。这是一个json文档(cfg.json),如下👇;或者,您可以直接下载文档
{
"ssh接口列表":[{"主机名称":"virtualBox","主机地址":"192.168.56.1","端口号":22,"用户名":"dyy","密码":"123456"}],
"everythingIP":"127.0.0.1",
"everythingPort":"22"
}
python脚本
👇以下脚本,提供了以上👆所演示的功能;或者,您可以直接下载脚本
# -*- coding:UTF-8 -*-
"""
@author: dyy
@contact: douyaoyuan@126.com
@time: 2023/11/16 22:37
@file: ssh工具.py
@desc: 脚本提供了ssh登录,ssh文档上传,ssh文档下载,ssh公钥配置等功能,以及优良的用户体验
"""# region 引入必要的依赖
import os
from enum import Enum
import json模块名 = 'DebugInfo'
try:from DebugInfo.DebugInfo import *
except ImportError as impErr:print(f"尝试导入 {模块名} 依赖时检测到异常:{impErr}")print(f"尝试安装 {模块名} 模块:")try:os.system(f"pip install {模块名}")except OSError as osErr:print(f"尝试安装模块 {模块名} 时检测到异常:{osErr}")exit(0)else:try:from DebugInfo.DebugInfo import *except ImportError as impErr:print(f"再次尝试导入 {模块名} 依赖时检测到异常:{impErr}")exit(0)模块名 = 'paramiko'
try:import paramiko
except ImportError as impErr:print(f"尝试导入 {模块名} 依赖时检测到异常:{impErr}")print(f"尝试安装 {模块名} 模块:")try:os.system(f"pip install {模块名}")except OSError as osErr:print(f"尝试安装模块 {模块名} 时检测到异常:{osErr}")exit(0)else:try:import paramikoexcept ImportError as impErr:print(f"再次尝试导入 {模块名} 依赖时检测到异常:{impErr}")exit(0)模块名 = 'difflib'
try:import difflib # 需要安装 difflib 模块,以支持字符差异对比操作
except ImportError as impErr:print(f"尝试导入 {模块名} 依赖时检测到异常:{impErr}")print(f"尝试安装 {模块名} 模块:")try:os.system(f"pip install {模块名}")except OSError as osErr:print(f"尝试安装模块 {模块名} 时检测到异常:{osErr}")exit(0)else:try:import difflibexcept ImportError as impErr:print(f"再次尝试导入 {模块名} 依赖时检测到异常:{impErr}")exit(0)# endregion# 定义一个 命令行参数类,用于解析和记录命令行参数
class 命令行参数类(入参基类):def __init__(self):super().__init__()self._添加参数('srcDir', str, '引用的路径')self._添加参数('srcDoc', str, '引用的文档')self._添加参数('everythingIP', str, 'everything HTTP 服务地址', '127.0.0.1')self._添加参数('everythingPort', str, 'everything HTTP 服务端口', '22')# 添加定制属性self.ssh接口列表: list[ssh接口类] = []# region 访问器@propertydef jsonCfg(self) -> str:if 'jsonCfg' in self._参数字典:return self._参数字典['jsonCfg'].值else:return ''@jsonCfg.setterdef jsonCfg(self, 值: str):if 'jsonCfg' in self._参数字典:self._参数字典['jsonCfg'].值 = str(值)@propertydef srcDir(self) -> str:if 'srcDir' in self._参数字典:return self._参数字典['srcDir'].值else:return ''@srcDir.setterdef srcDir(self, 值: str):if 'srcDir' in self._参数字典:self._参数字典['srcDir'].值 = str(值)@propertydef srcDoc(self) -> str:if 'srcDoc' in self._参数字典:return self._参数字典['srcDoc'].值else:return ''@srcDoc.setterdef srcDoc(self, 值: str):if 'srcDoc' in self._参数字典:self._参数字典['srcDoc'].值 = str(值)@propertydef everythingIP(self) -> str:if 'everythingIP' in self._参数字典:return self._参数字典['everythingIP'].值else:return ''@everythingIP.setterdef everythingIP(self, 值: str):if 'everythingIP' in self._参数字典:self._参数字典['everythingIP'].值 = str(值)@propertydef everythingPort(self) -> str:if 'everythingPort' in self._参数字典:return self._参数字典['everythingPort'].值else:return ''@everythingPort.setterdef everythingPort(self, 值: str):if 'everythingPort' in self._参数字典:self._参数字典['everythingPort'].值 = str(值)# endregion# region ssh候选列表def 解析Json(self,jsonCfg: str = None,encoding: str = 'utf-8',画板: 打印模板 = None):"""从指定的json文档中(如果不指定,则从 jsonCfg 参数指定的json文档中)读取配置参数,将值赋值给同名的命令行参数:param jsonCfg: 可以指定jsonCfg文档:param encoding: 可以指定jsonCfg文档的编码格式,默认为 utf-8:param 画板: 提供消息打印渠道:return: None"""画板 = 画板 if isinstance(画板, 打印模板) else 打印模板()画板.执行位置(self.__class__, self.解析Json)if not jsonCfg:if 'jsonCfg' in self._参数字典.keys():jsonCfg = self._参数字典['jsonCfg'].值jsonCfg = str(jsonCfg if jsonCfg else '').strip()if not jsonCfg:画板.提示调试错误('jsonCfg 路径无效')return Noneif not os.path.isfile(jsonCfg):画板.提示调试错误(f'jsonCfg 不是有效的 json 文件路径: {jsonCfg}')return Noneif not jsonCfg.endswith('.json'):画板.提示调试错误(f'jsonCfg 不是 json 格式的文件: {jsonCfg}')画板.调试消息(f'待解析的 jsonCfg 文件是: {jsonCfg}')encoding = str(encoding if encoding else 'utf-8').strip()jsonDic: dicttry:with open(jsonCfg, 'r', encoding=encoding) as f:jsonDic = json.load(f)except Exception as openExp:画板.提示调试错误(f'打开并读取 json 文档时遇到错误: {openExp}')jsonDic = {}if not jsonDic:画板.提示调试错误(f'未解析到有效的 json 内容: {jsonCfg}')return NonejsonDic字典: dict = {}for 键, 值 in jsonDic.items():# 去除键前后的空格键 = str(键).strip()if 键:jsonDic字典[键] = 值已匹配的参数: dict[str, 入参基类._参数结构类] = {}未匹配的参数: dict[str, 入参基类._参数结构类] = {}for 参数 in self._参数字典.values():if 参数.名称 in jsonDic字典:参数.值 = jsonDic字典[参数.名称]if str(参数.值).strip() == str(jsonDic字典[参数.名称]).strip():已匹配的参数[参数.名称] = 参数if 'ssh接口列表' in jsonDic字典.keys() and jsonDic字典['ssh接口列表']:# 解析ssh接口配置ssh接口列表 = jsonDic字典['ssh接口列表']参数 = 命令行参数类._参数结构类(名称='ssh接口列表')参数.值 = ssh接口列表已匹配的参数['ssh接口列表'] = 参数for 接口 in ssh接口列表:ssh接口: ssh接口类 = ssh接口类()if '主机名称' in 接口:ssh接口.主机名 = 接口['主机名称']if '主机地址' in 接口:ssh接口.主机地址 = 接口['主机地址']if '端口号' in 接口:ssh接口.端口号 = 接口['端口号']if '用户名' in 接口:ssh接口.用户名 = 接口['用户名']if '密码' in 接口:ssh接口.密码 = 接口['密码']self.ssh接口列表.append(ssh接口)for 键, 值 in jsonDic字典.items():if 键 not in 已匹配的参数.keys():这个参数: 入参基类._参数结构类 = 入参基类._参数结构类(名称=键,类型=str,提示='这是 jsonCfg 中未匹配成功的参数',默认值=值)未匹配的参数[键] = 这个参数if 画板.正在调试 and (已匹配的参数 or 未匹配的参数):画板.准备表格()if 已匹配的参数:画板.添加一行('参数名', '参数类型', '参数值', '提示').修饰行(青字)for 参数 in 已匹配的参数.values():画板.添加一行(参数.名称, 参数.类型, 参数.值, 参数.提示)if 未匹配的参数:画板.添加分隔行(提示文本='以下参数未匹配成功', 修饰方法=红字, 适应窗口=True)for 参数 in 未匹配的参数.values():画板.添加一行(参数.名称, 参数.类型, 参数.值, 参数.提示)画板.展示表格()# endregionclass 文档操作记录类:def __init__(self,旧文档: str = None,新文档: str = None):self.__旧文档: str = 旧文档self.__新文档: str = 新文档self.__带标注的旧文档: str = ''self.__带标注的新文档: str = ''# region 访问器@propertydef 旧文档(self) -> str:return self.__旧文档@旧文档.setterdef 旧文档(self, 文档: str):文档 = str(文档 if 文档 else '').strip()self.__旧文档 = 文档self.__带标注的旧文档 =