邵阳网站建设制作网站建设 10万元
自第九届世界渲染大赛开放投稿以来,已经过去了10天。在这段时间里,众多CG爱好者已经完成了他们的动画创作。然而,许多参赛者对于如何提交他们的作品仍然感到困惑。接下来,让我们一起了解具体的投稿流程和入口,确保每位选手都能顺利参与这场盛大的赛事。

第9届渲染大赛作品提交流程
官网获取百度搜索:“2024世界渲染大赛官网"即可找到。
1、移步第九届世界渲染大赛网站,如果用户访问速度较慢,建议使用工具来提高网络访问速度。
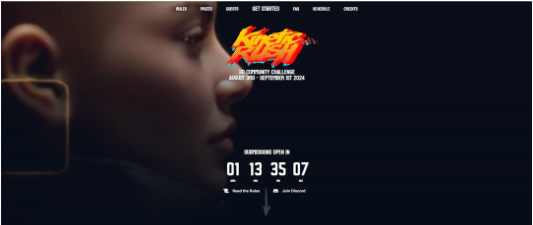
2、进入官网后,请滚动至页面底部查找赛事的日程安排,这里会详细列出关键日期,如作品提交截止时间、评审期以及前100名入围作品的公布时间等重要节点。
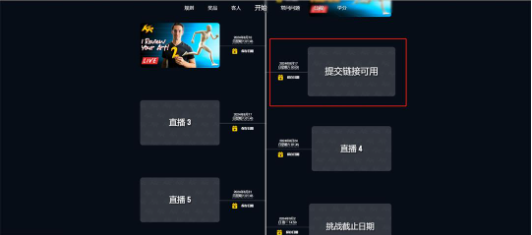
3、根据日程安排,第九届大赛的作品提交入口将会在2024年8月16日正式开放。
提交作品问题:
Q:我可以触摸相机吗?
你可以添加相机抖动、景深和运动模糊效果。
Q:提交链接在哪里?
提交链接将在8月16日星期五挑战进行到一半时提供。
Q:我可以多次提交或更新我的提交内容吗?
不可以,每个人只接受一次提交。
Q:多个人可以共同完成同一个提交吗?
不可以。这是一项每人只能提交一次的比赛。由多位艺术家共同创作的作品将被取消资格。
Q:我的提交迟到了,我的作品还会在“所有渲染蒙太奇”中展示吗?
任何在截止日期后收到的提交都不能保证会包含在“所有渲染蒙太奇”中。
如果您在参与世界渲染大赛时遇到了动画渲染的问题,比如渲染速度慢或者软件不稳定导致的闪退,可以考虑使用“Renderbus瑞云渲染农场”来帮助解决这些问题。瑞云渲染农场拥有大量的高端服务器和强大的计算能力,能够帮助影视动画企业和个人工作室更高效地完成渲染任务。注册瑞云动画账号填【GSZI】还可领 10元渲染劵,完成首充 1元可再得 100无门槛渲染劵。
