可信赖的郑州网站建设泉州百度竞价开户
系列文章目录
第一章 2D二维地图绘制、人物移动、障碍检测
第二章 跟随人物二维动态地图绘制、自动寻径、小地图显示(人物红点显示)
第三章 绘制冰宫宝藏地图、人物鼠标点击移动、障碍检测
第四章 绘制Q版地图、键盘上下左右地图场景切换
文章目录
- 系列文章目录
- 前言
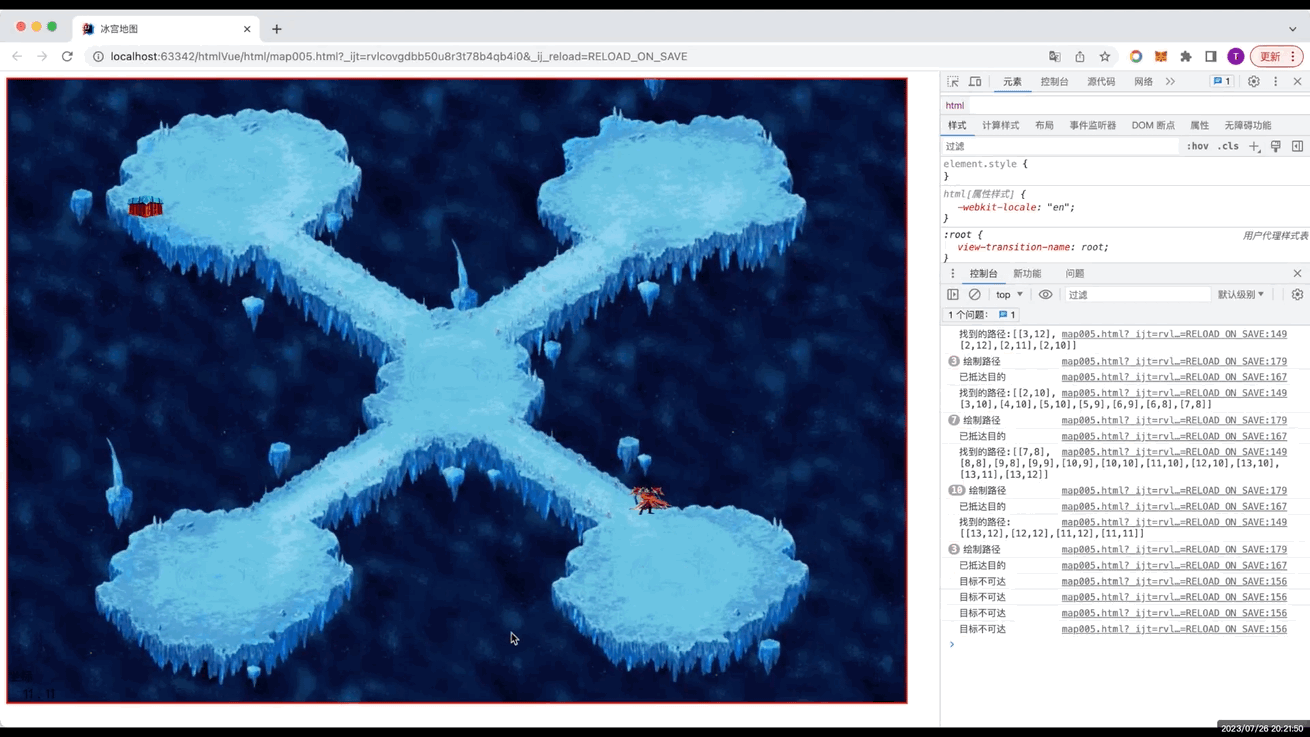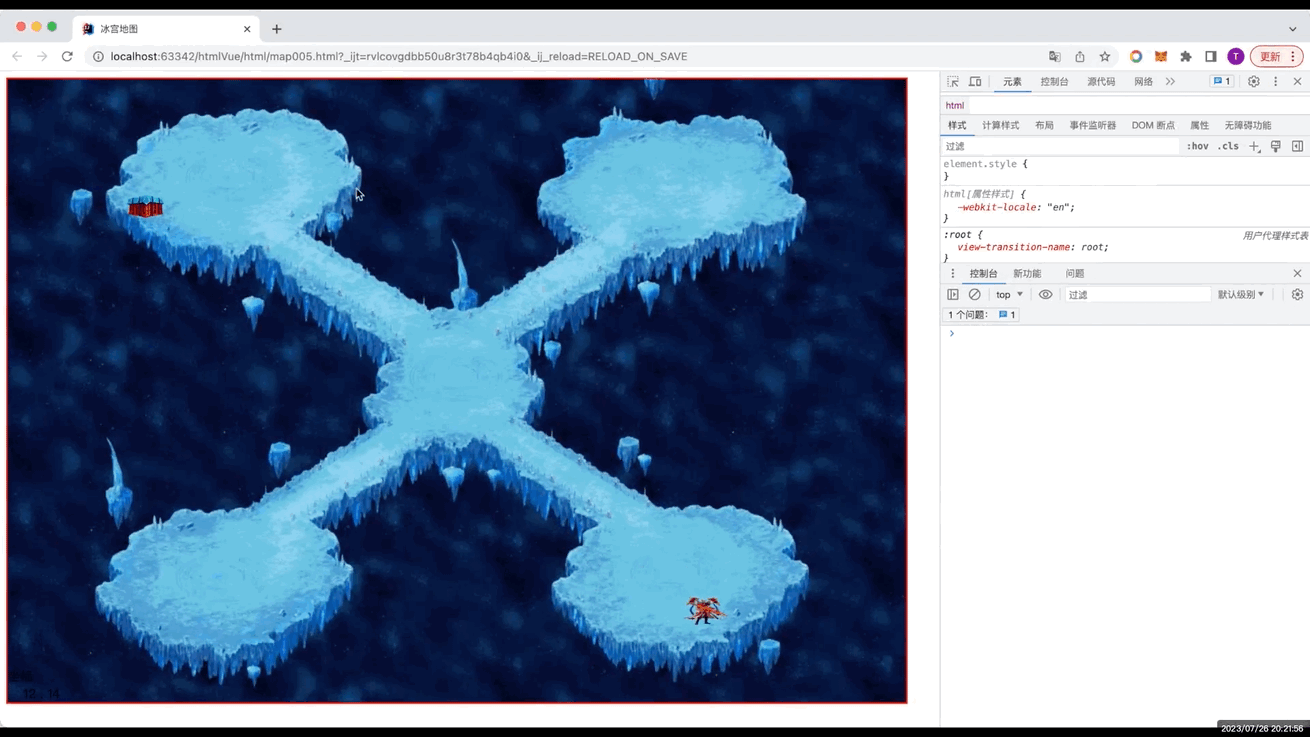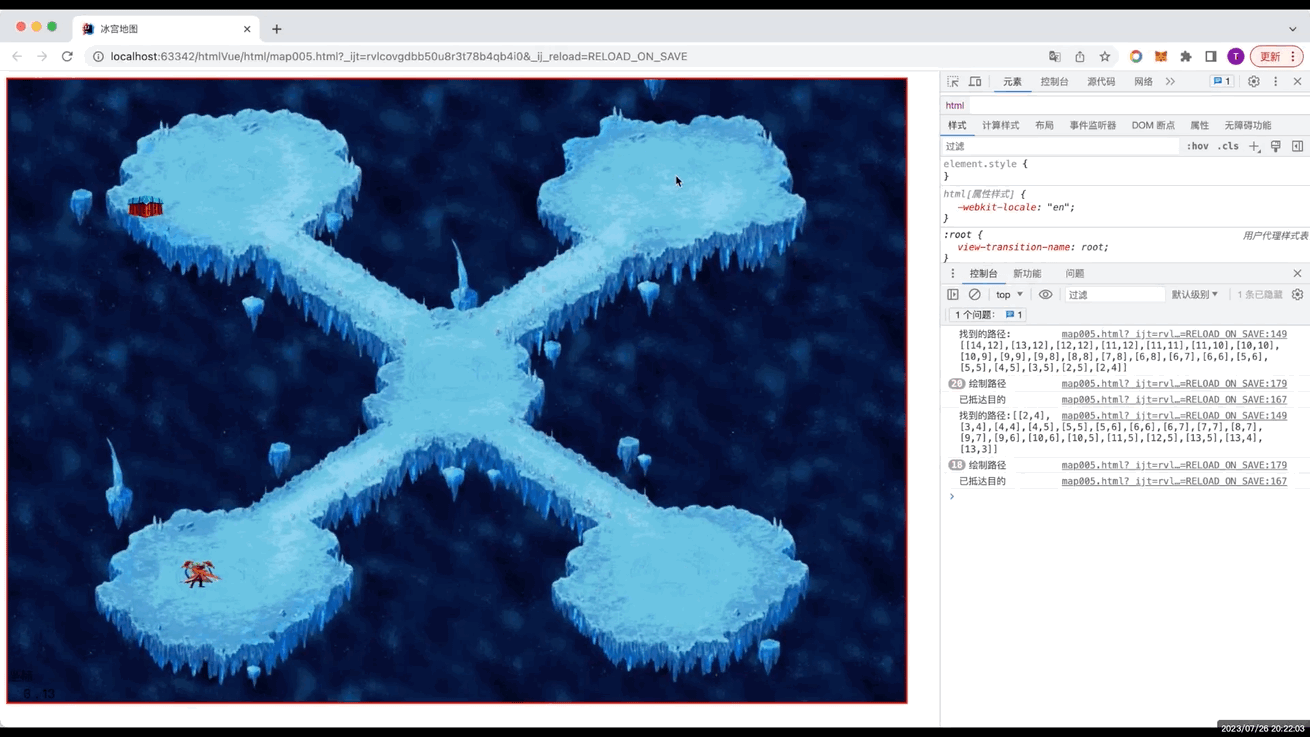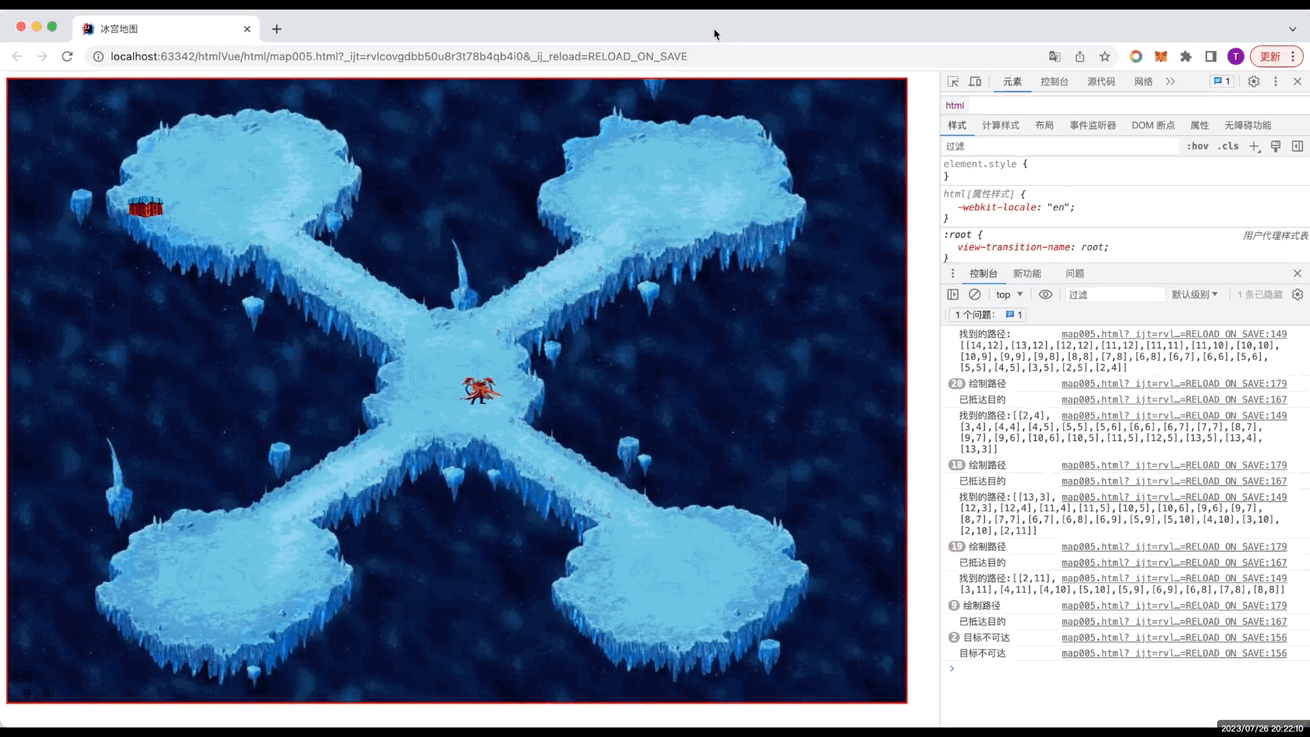
- 一、本章节效果图
- 二、介绍
- 2.1、准备地图素材
- 2.2、封装地图上的物品素材(人物暂未拆出,也在此处)
- 2.3、准备地图信息
- 2.4、调试地图
- 三、实际作业流程
- 3.1、调试地图
- 3.1.1、0 代表可走的路径,但是0在地图上看不见,我们可以先用其他的替代
- 3.1.2、批量替换回去
- 3.1.3、调试的渲染效果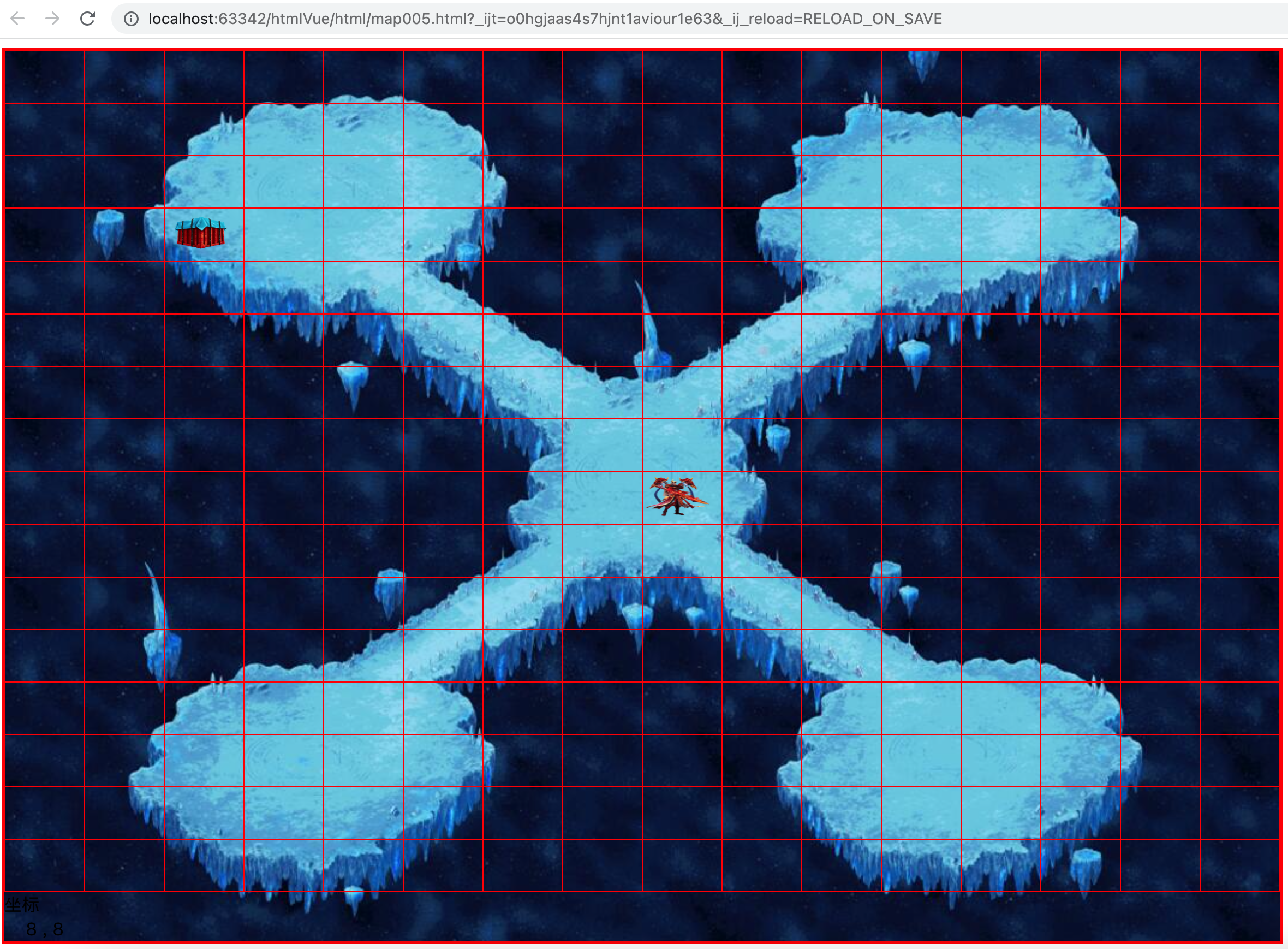
- 3.1.4、关闭调试模式
- 总结
前言
本章内容融合了第一章、第二章的部分内容,因此带大家回顾下前两章的内容。
第一章:
- 使用JavaScript绘制简单的二维地图
采用二维数组存储地图信息,使用表格绘制地图,每个td单元格存储数据 - 键盘上下左右控制
使用JavaScript keyPress键盘事件监听WASD键,按键触发时人物做出相应操作 - 障碍物碰撞检测(采用格子碰撞检测)
人物下一步碰撞到石头时,提示遇到障碍,终止人物运动
第二章:
- 使用aStar算法 + 鼠标事件(确定终点目标) 自动寻径
采用二维数组存储地图信息,使用表格绘制地图,每个td单元格存储数据
本章节采用第一章节的地图绘制 ,第二章的自动寻径、障碍检测部分代码。
一、本章节效果图
二、介绍
在第二章里的游戏界面有2个区域,本次只显示小地图,大地图动态加载背景需要运用裁剪图片(需要根据人物自动定位图片坐标,地图跟随变化),工作量较大放在后续实现。
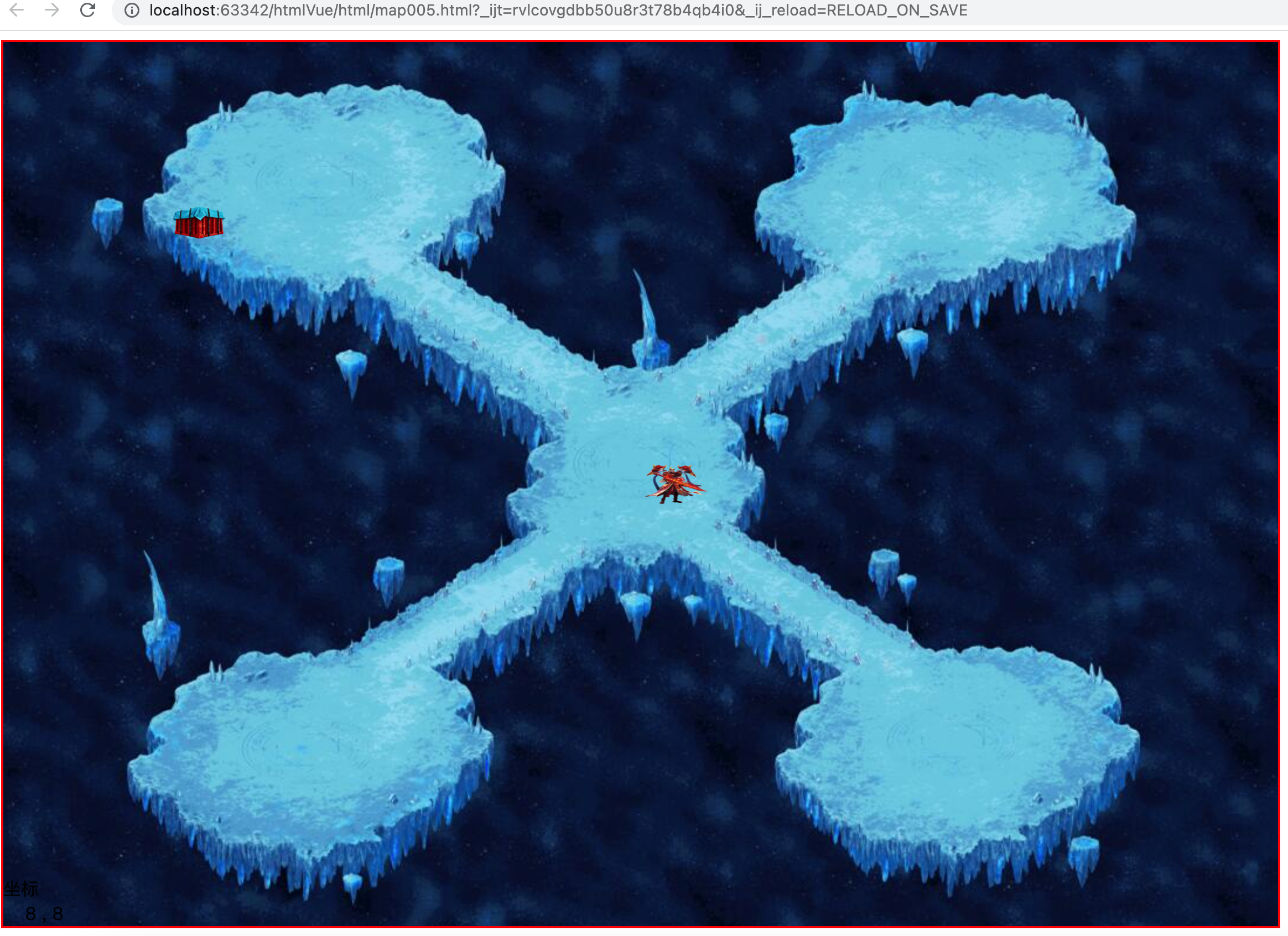
2.1、准备地图素材
2.2、封装地图上的物品素材(人物暂未拆出,也在此处)
// 物品
var item = {};item.initItem = function (){item.empty = 0; //空地或草坪item.stone = 1; //石头的标记是1item.factory = 2; //工厂item.girl = 3; //女子item.girl_01 = 4; //女孩item.kt = 5; //空投大礼包item.lz = 6; //路障item.pz = 7; //喷子item.zz = 8; //沼泽item.hero = 9; //英雄的标记是9item.heroHasPath = 10; //自动寻径的英雄标记是10item.wdss = 11; //僵尸的标记是11item.datas = []; // 物品的图片集合var itemPrefixPath = "../img/item/";item.datas[0] = "";item.datas[1] = itemPrefixPath + "stone.png";item.datas[2] = itemPrefixPath + "gc.png";item.datas[3] = itemPrefixPath + "girl.png";item.datas[4] = itemPrefixPath + "girl.bmp";item.datas[5] = itemPrefixPath + "kt.png";item.datas[6] = itemPrefixPath + "lz.png";item.datas[7] = itemPrefixPath + "pz.png";item.datas[8] = itemPrefixPath + "zz.png";item.datas[9] = itemPrefixPath + "/spine/hero002.gif";item.datas[10] = itemPrefixPath + "/spine/tank.gif";item.datas[11] = itemPrefixPath + "wdss.gif";
}2.3、准备地图信息
/*** 加载地图数据* 0 可走的路径* 1 障碍* 5 空投* 9 英雄* @type {number[]}*/var mapData = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1],[1, 1, 5, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1],[1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1],[1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1],[1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1],[1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1],[1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1],[1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
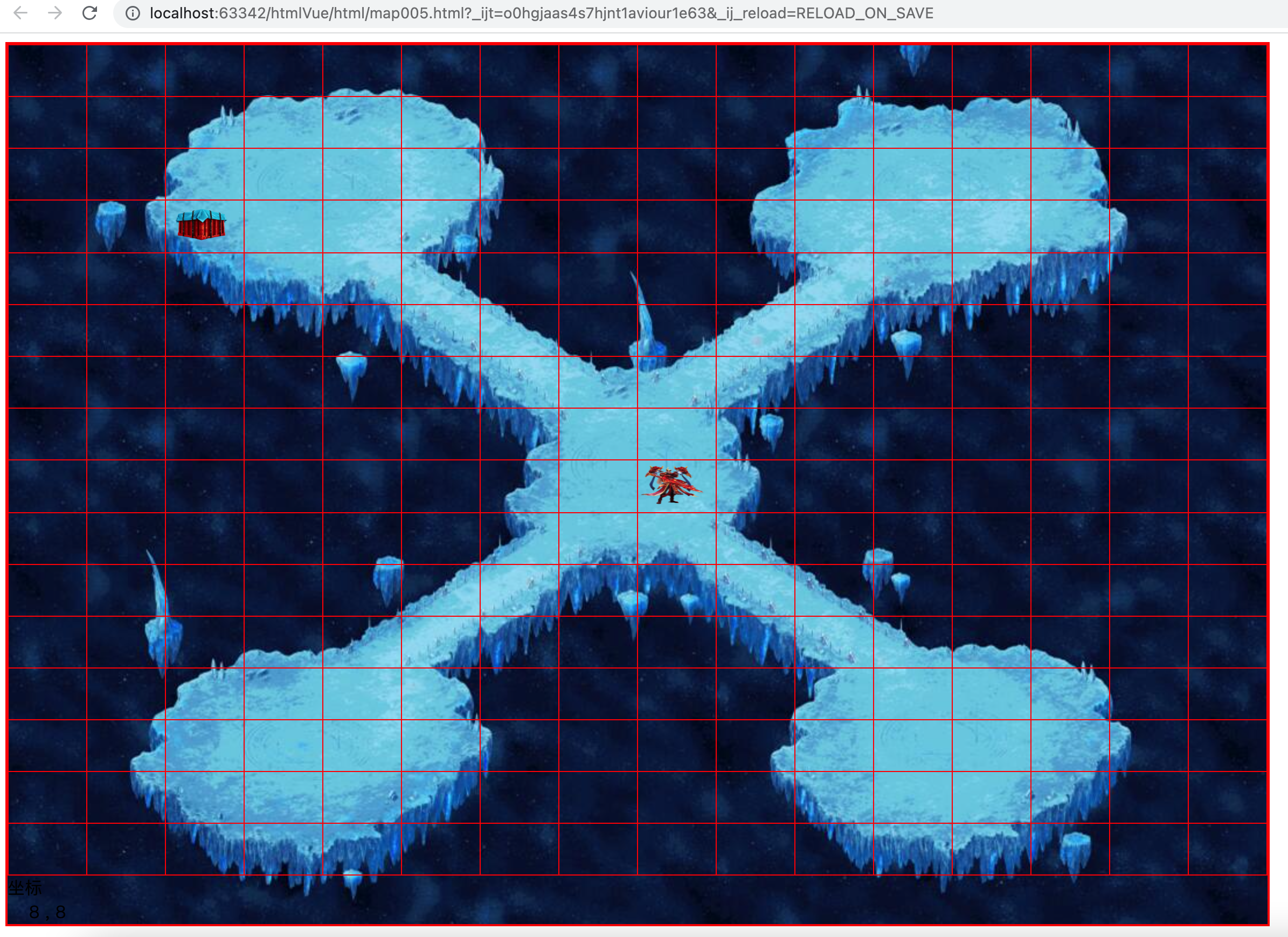
2.4、调试地图
调试地图阶段,给td的边框着色
<style>table.main,table.small {border-collapse: collapse;}.bg {background: url("../img/item/bg/bg005.png");background-position: center;background-size: cover;background-repeat: no-repeat;}table.small td {border: 1px red solid;width: 70px;height: 45px;}</style>
三、实际作业流程
3.1、调试地图
3.1.1、0 代表可走的路径,但是0在地图上看不见,我们可以先用其他的替代
/*** 加载地图数据* 0 可走的路径* 1 障碍* 5 空投* 9 英雄* @type {number[]}*/var mapData = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 5, 5, 1, 1, 1, 1, 1, 1, 5, 5 1, 1, 1],[1, 1, 5, 5, 5, 5, 1, 1, 1, 1, 5, 5, 5, 5, 1, 1],[1, 1, 5, 5, 5, 5, 1, 1, 1, 1, 5, 5, 5, 5, 1, 1],[1, 1, 1, 5, 5, 5, 1, 1, 1, 1, 5, 5, 5, 5, 1, 1],[1, 1, 1, 1, 1, 5, 5, 1, 1, 5, 5, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 5, 5, 5, 5, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 5, 5, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 5, 5, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 5, 5, 5, 5, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 5, 5, 1, 1, 5, 5, 1, 1, 1, 1, 1],[1, 1, 1, 1, 5, 5, 1, 1, 1, 1, 5, 5, 5, 1, 1, 1],[1, 1, 5, 5, 5, 5, 1, 1, 1, 1, 5, 5, 5, 5, 1, 1],[1, 1, 5, 5, 5, 5, 1, 1, 1, 1, 5, 5, 5, 5, 1, 1],[1, 1, 1, 5, 5, 1, 1, 1, 1, 1, 1, 5, 5, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
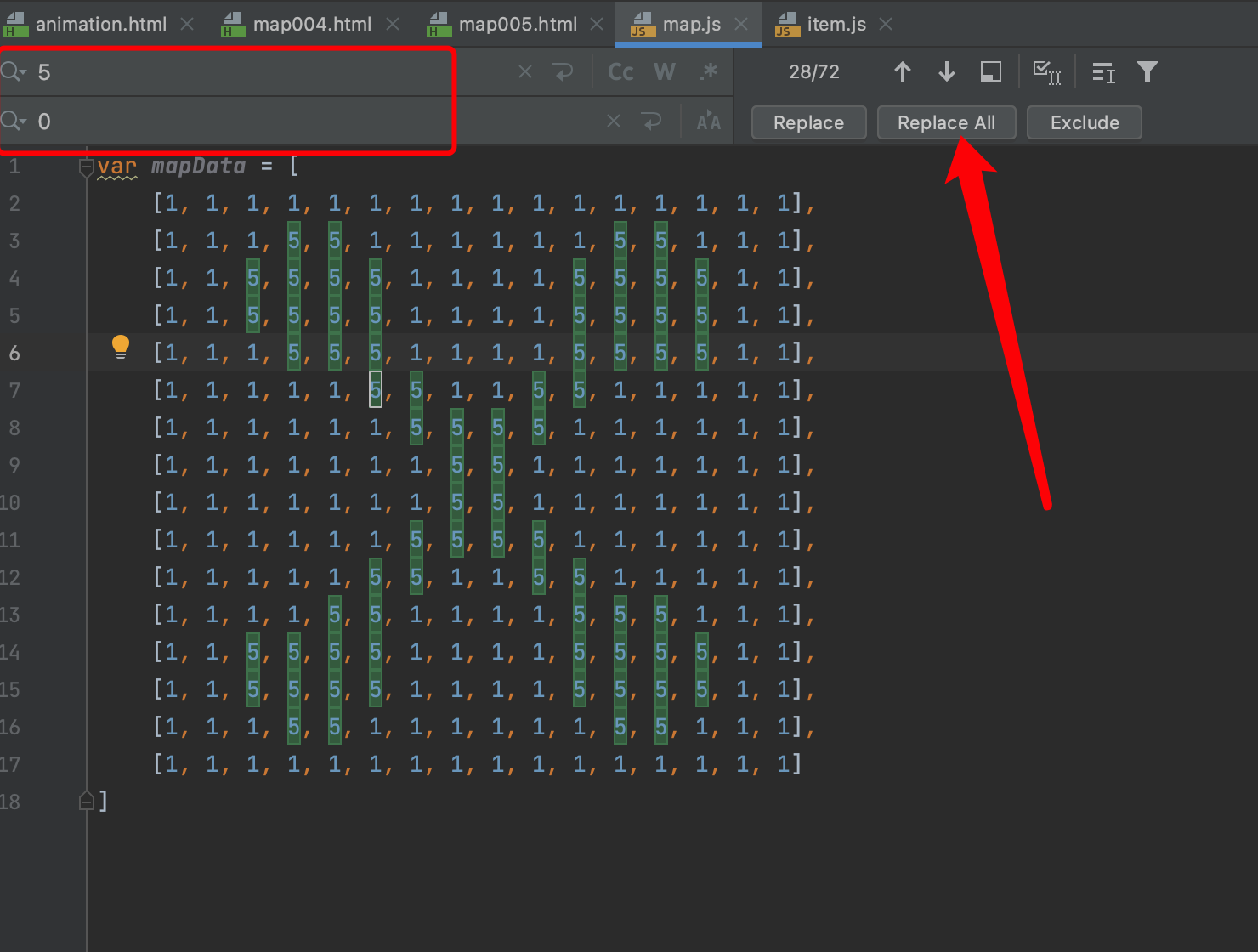
3.1.2、批量替换回去
1、把5再修改回0,就是上图空投所占据的地方,都是英雄可走的路径
2、然后随机替换一个0,变成5(空投),这样地图上就有一个空投了

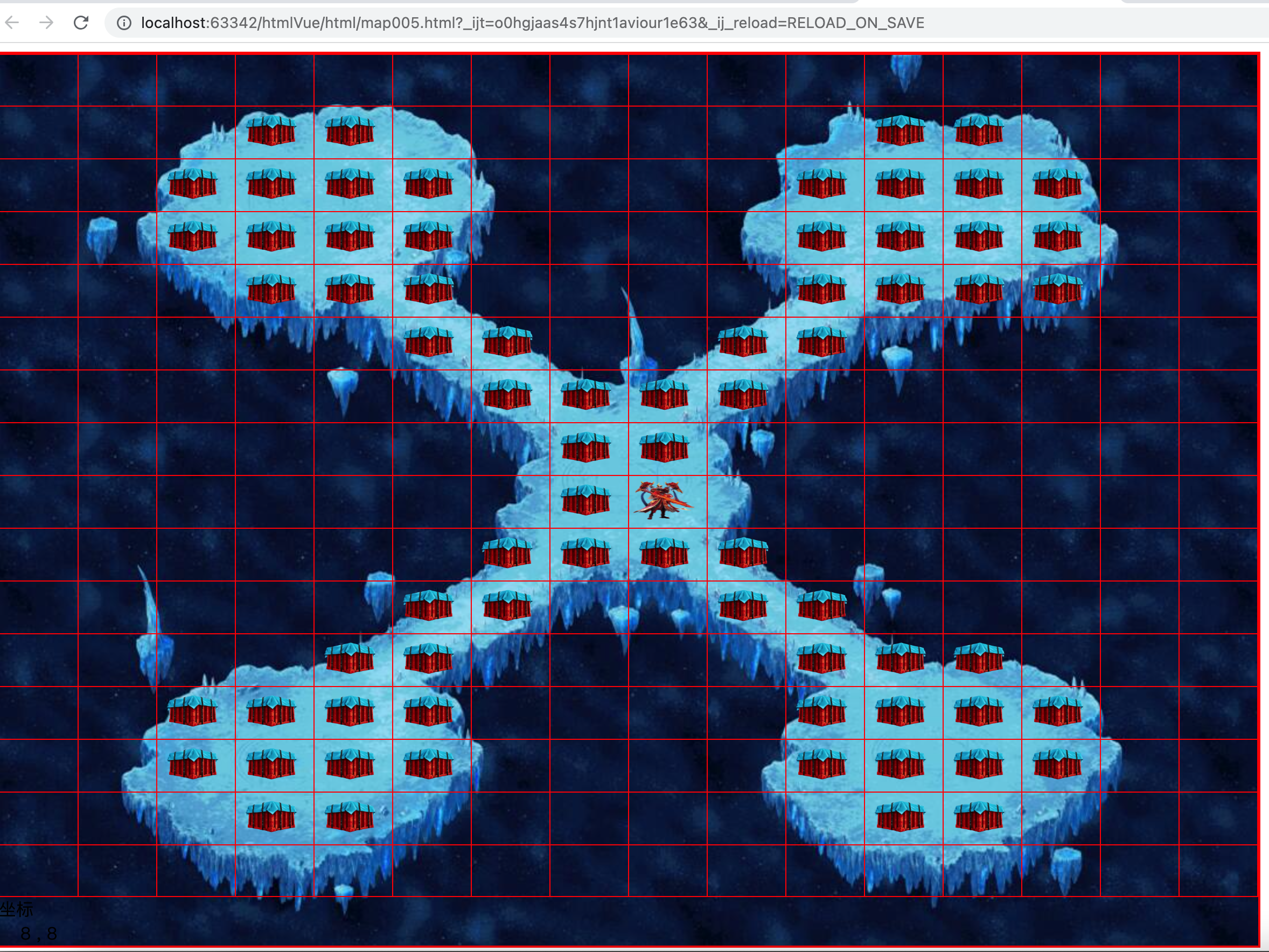
3.1.3、调试的渲染效果
3.1.4、关闭调试模式
找到【2.4、调试地图】部分,关闭调试模式(去除td的边框着色)
<style>table.main,table.small {border-collapse: collapse;}.bg {background: url("../img/item/bg/bg005.png");background-position: center;background-size: cover;background-repeat: no-repeat;}table.small td {/** border: 1px red solid; */width: 70px;height: 45px;}</style>
总结
以上就是今天要讲的内容,本文仅仅简单介绍了其中一种地图(冰宫宝藏)的绘制,后续还会推出更多地图,比如:问道、梦幻西游、传奇等游戏的地图。
放出一个半成品地图渲染效果(已实现碰撞检测、自动寻径):
