烟台市建设工程质量检测网站养殖网站源码
1.确认当前为家庭中文版

2.用管理员权限打开cmd窗口
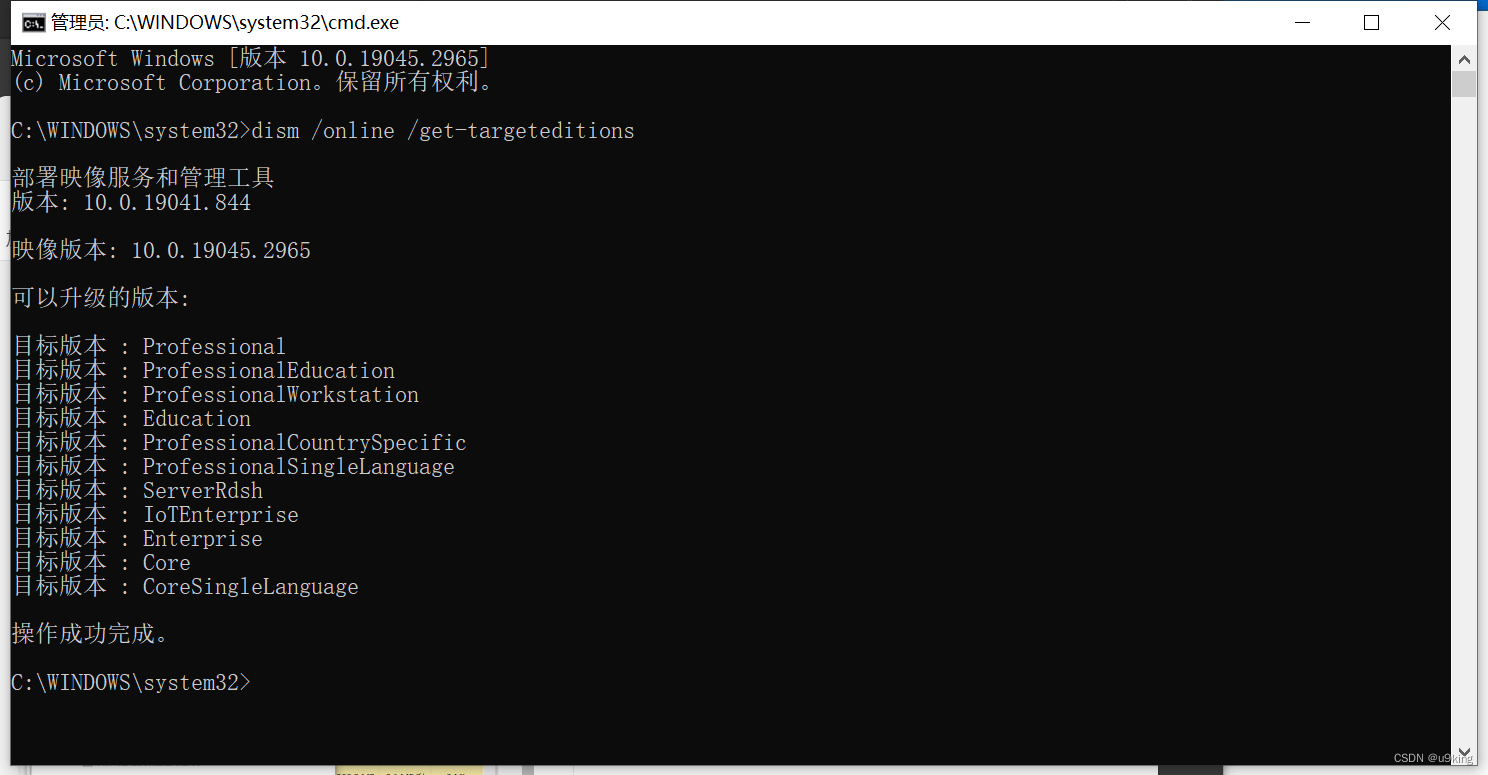
3.输入 dism /online /get-targeteditions ,查询当前支持的升级的版本
4.专业版密钥:VK7JG-NPHTM-C97JM-9MPGT-3V66T
5.changepk.exe /productkey VK7JG-NPHTM-C97JM-9MPGT-3V66T
1.确认当前为家庭中文版
2.用管理员权限打开cmd窗口
3.输入 dism /online /get-targeteditions ,查询当前支持的升级的版本
4.专业版密钥:VK7JG-NPHTM-C97JM-9MPGT-3V66T
5.changepk.exe /productkey VK7JG-NPHTM-C97JM-9MPGT-3V66T