大理网站制作公司多推网怎么推广
1.Restful请求
restFul是符合rest架构风格的网络API接口,完全承认Http是用于标识资源。restFul URL是面向资源的,可以唯一标识和定位资源。 对于该URL标识的资源做何种操作是由Http方法决定的。 rest请求方法有4种,包括get,post,put,delete.分别对应获取资源,添加资源,更新资源及删除资源.
RESTful风格就是一种书写URL的要求
现在很多网站都用RESTful风格的URL,为了应对这种URL形式,SpringMVC里有一些注解可以方便获得URL里的值
A、请求参数换成key/value
例如请求URL都这样,抓取的请求报文里没有请求参数,key/value值在url里
其实这就是RESTful风格的写法,请求参数不用key=value,而是key/value,对应这种形式,不可能每个请求写一个Handler方法(控制单元),用下面方法可以一个方法通配多个URL
//在@RequestMapping注解的value属性,可以使用{}作为占位符,占位符的内容随意//再通过@PathVariable注解的value(填占位符变量),// 形参可以获得对应占位符的值@RequestMapping("RESTful/{name}/{id}")public User articleDetail(@PathVariable("name") String username,@PathVariable("id") Integer id) {return new User();}发送URL不管是:http://localhost/RESTful/v/111,还是http://localhost/RESTful/m/55555,可以看到都是同一个Handler方法(控制单元)处理请求,并且形参是部分URL内容

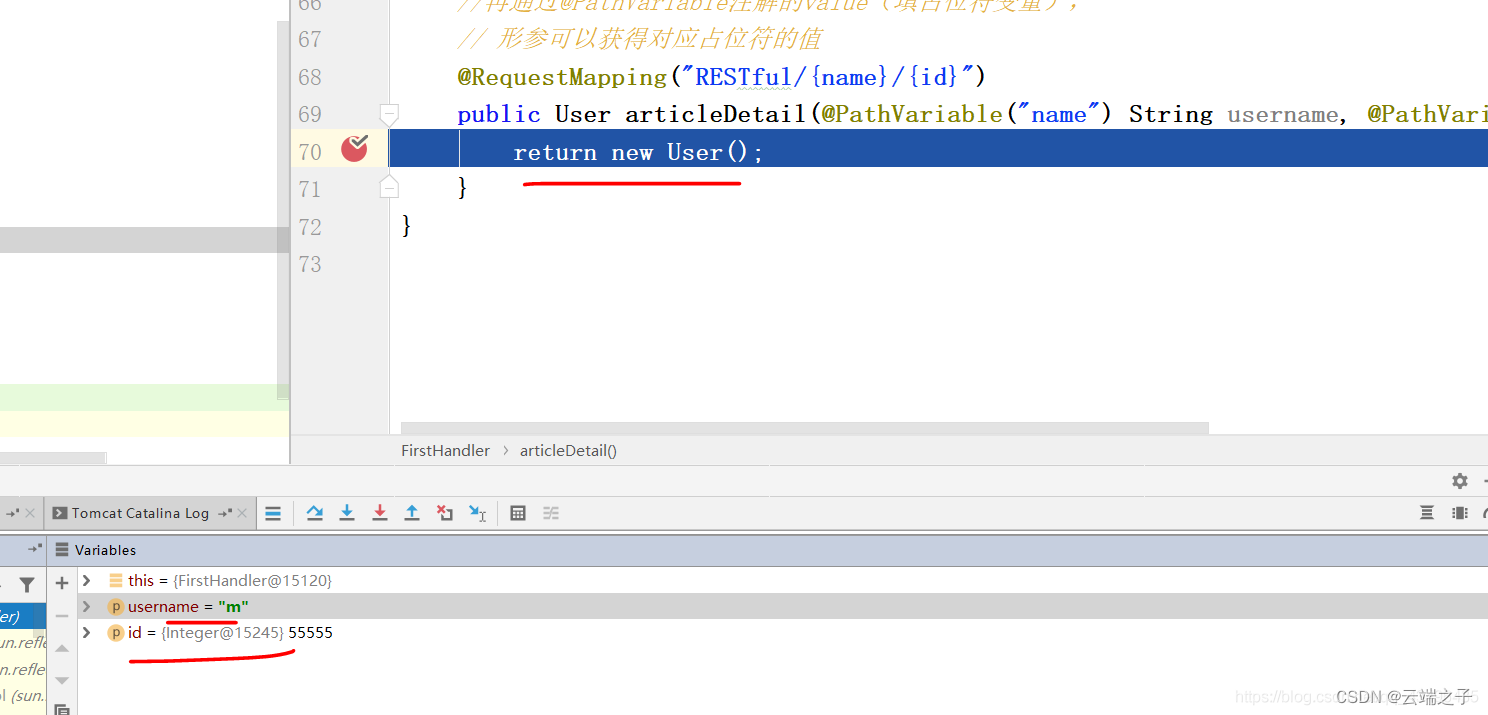
在Java中的使用
在SpringMVC中使用该方式,需要@PathVariable注解(该注解可以接收路径中占位符参数并与控制单元的形参绑定)结合@RequestMapping注解,或者结合以下注解:
@GetMapping("地址"):接收GET请求,一般用在查询方法上。
@DeleteMapping("地址"):接收DELETE请求,一般用在删除方法上。
@PostMapping("地址"):接收POST请求,一般用户在新增上。
@PutMapping("地址"):接收PUT请求,一般用在修改上。
对应的注解接收对应的请求方式:
@Controller
@RequestMapping("user")
public class UserController {@GetMapping("{id}")public String query(@PathVariable int id){System.out.println("restful->查询-> " + id);return "success.jsp";}@DeleteMapping("{id}")public String del(@PathVariable int id){System.out.println("restful->删除-> " + id);return "success.jsp";}@PostMapping("{id}/{name}/{pwd}")public String add(@PathVariable int id, @PathVariable String name, @PathVariable int pwd){System.out.println("restful->添加-> " + id + " " + name + " " + pwd);return "success.jsp";}@PutMapping("{id}/{name}/{pwd}")public String update(@PathVariable int id, @PathVariable String name, @PathVariable int pwd){System.out.println("restful->修改-> " + id + " " + name + " " + pwd);return "success.jsp";}
}2.@ResponseBody注解
该注解可以使用在类上和方法上。被该注解修饰的类和方法表示控制单元方法返回值将不再被视图解析器进行解析|不会使用转发。而是把返回值放入到响应流中进行响应。
注意:
| 1.被该注解修饰的控制单元只能返回String类型的数据。返回其他类型的数据如果没有经过设置,将会出现406状态码,浏览器无法接收。 |
| 2.可以配合@RequestMapping(produces = "text/plain;charset=utf-8")设置响应内容类型及编码格式。 |
| 3.如果引入了Jackson的依赖,控制单元可以返回,JavaBean,数组[JavaBean], List<JavaBean>, Map, List<Map> 等,SpringMVC会自动将这些类型转化为json格式的字符串,同时自动设置响应内容类型为application/json;charset=utf-8。 |
| 4.在Spring MVC中支持把返回值转换为XML文件。如果还是使用jackson-databind依赖,默认只能转换返回值为类类型的控制单元,返回值为List是无法转换为XML的,同时还要求实体类上必须有@XmlRootElement,才能转换。 |
| 5.如果想要自动将返回值转换为XML文件,则需要导入jackson-dataformat-xml依赖。 |
因为Spring MVC默认使用Jackson作为JSON转换工具,所以必须保证项目中存在Jackson的依赖。
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.9.10.8</version>
</dependency>3.@RequestBody注解
@RequestBody主要用来接收客户端传递给服务器的json字符串中的数据(请求体中的数据的),并将其转化为Map、类、List<类>、List<Map>等类型。
注意:
- @RequestBody注解是用来接收请求体中的数据,所以不能使用GET请求。
- 前端如果发送ajax请求,则需要设置contentType属性为application/json或者application/xml。
- 该注解可以与@RequestParam注解一起使用。一起使用时,@RequestParam注解接收的是key-value形式的参数,而@RequestBody注解接收的的请求体中的参数。
4.文件上传与下载
使用SpringMVC的文件上传与下载需要引入commons-fileupload依赖和commons-io依赖,由于commons-fileupload已经依赖了commons-io依赖了。所以根据依赖的传递性只需要添加commons-fileupload依赖就行了。
<dependency><groupId>commons-fileupload</groupId><artifactId>commons-fileupload</artifactId><version>1.4</version>
</dependency>文件上传:
前端要求:
请求方式为post请求,使用请求体完成文件的传输。
enctype:multipart/form-data
后端要求:
配置文件解析器,MultipartResovler(接口),常用的实现类为CommonsMultipartResovler
引入Commons-Fileupload依赖,CommonsMultipartResovler对Commons-Fileupload进行了封装。
客户端传递的请求参数经过 文件解析器 的解析,解析出普通表单数据,上传的文件对象,
普通表单数据 -》正常接收
文件对象 -》MultipartFile
MultipartFile中的方法transferTo()完成上传
ajax上传:
FormData data = new FormData(form表单dom对象);
processData:false -》ajax不序列化表单中参数
contentType:false -》不指定类型
enctype:multipart/form-data
文件下载:
设置响应头的"Content-Disposition",属性值为"attachment;filename=文件名" ;
使用IOUtils类中的copy(输入流对象, 输出流对象)方法,传入文件的输入流对象,获取响应的输出流对象,传入即可。
上传:
@ResponseBody@RequestMapping("upload")public String upload(Integer id, String name, Integer age, MultipartFile photo, MultipartFile resume, HttpServletRequest request, HttpServletResponse response) throws IOException {System.out.println(id);System.out.println(name);System.out.println(age);System.out.println(photo);System.out.println(resume);//文件上传服务器String originalFilename = photo.getOriginalFilename();System.out.println(originalFilename);String path = request.getServletContext().getRealPath("upload/image");File file = new File(path);if (!file.exists()){file.mkdirs();}photo.transferTo(new File(path,originalFilename));String originalFilename1 = resume.getOriginalFilename();System.out.println(originalFilename1);String path1 = request.getServletContext().getRealPath("upload/txt");File file1 = new File(path1);if (!file1.exists()){file1.mkdirs();}resume.transferTo(new File(path1,originalFilename1));//文件保存在服务器的位置传到数据库People people = new People(id, name, age, originalFilename, originalFilename1);int i = peopleService.insert(people);return "ok";}
下载:
@RequestMapping("download")@ResponseBodypublic String download(HttpServletRequest request,HttpServletResponse response ,String filename) throws IOException {//解决文件名中文乱码问题String fileNewName = new String(filename.getBytes(), "iso8859-1");//设置响应头(文件直接下载而不是打开)response.setHeader("Content-Disposition","attachment;filename="+ fileNewName);//获得文件所在绝对路径String realPath = request.getServletContext().getRealPath("upload/image");//指定该路径为文件操作路劲File file = new File(realPath);//去该操作路径获取输入流 ,去读取该路径下的文件 fileNewNameFileInputStream fis = new FileInputStream(file + "/" + fileNewName);//读取之后,通过响应对象获得输出流ServletOutputStream outputStream = response.getOutputStream();//通过文件上传和下载的依赖中封装的函数 传入输入流和输出流即可IOUtils.copy(fis, outputStream);outputStream.close();fis.close();return "ok";}