淘宝网站建设目标网站维护需要会什么
一、动态链接库劫持原理
1.1、原理
Unix操作系统中,程序运行时会按照一定的规则顺序去查找依赖的动态链接库,当查找到指定的so文件时,动态链接器(/lib/ld-linux.so.X)会将程序所依赖的共享对象进行装载和初始化,而为什么可以使用so文件进行函数的劫持呢?
这与LINUX的特性有关,先加载的so中的全局符号会屏蔽掉后载入的符号,也就是说如果程序先后加载了两个so文件,两个so文件定义了同名函数,程序中调用该函数时,会调用先加载的so中的函数,后加载的将会屏蔽掉;所以要实现劫持,必须要抢得先机,
环境变量LD_PRELOAD以及配置文件/etc/ld.so.preload就可以让我们取得这种先机,它们可以影响程序的运行时的链接(Runtime linker),它允许你定义在程序运行前优先加载的动态链接库,我们只要在通过LD_PRELOAD加载的.so中编写我们需要hook的同名函数,即可实现劫持!
1.2、LD_PRELOAD函数讲解
LD_PRELOAD是一个环境变量,用于在运行时指定要在程序加载时优先加载的共享库(动态链接库)。这个环境变量允许你在程序启动之前将特定的共享库加载到内存中,从而可以在程序执行期间修改或替换系统库中的函数。
二、实例
1.1进入我们之前部署的docker环境(进入bypass绕过实例),这里我们以第1种为例子

1.2
Dockerfile:
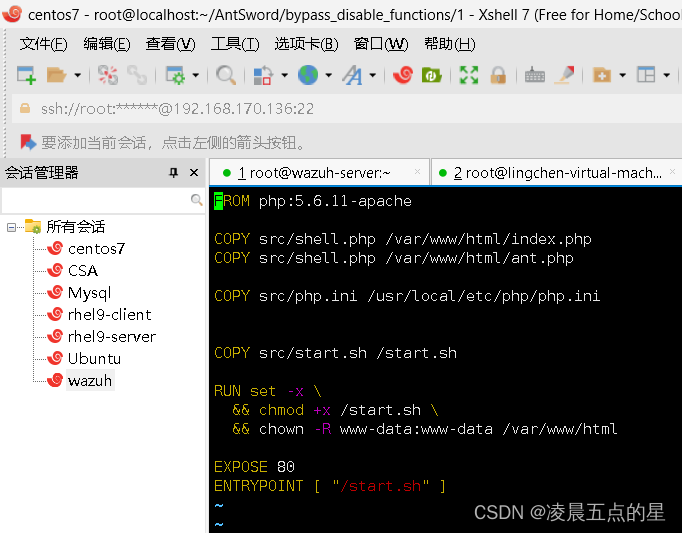
docker-compose.yml:
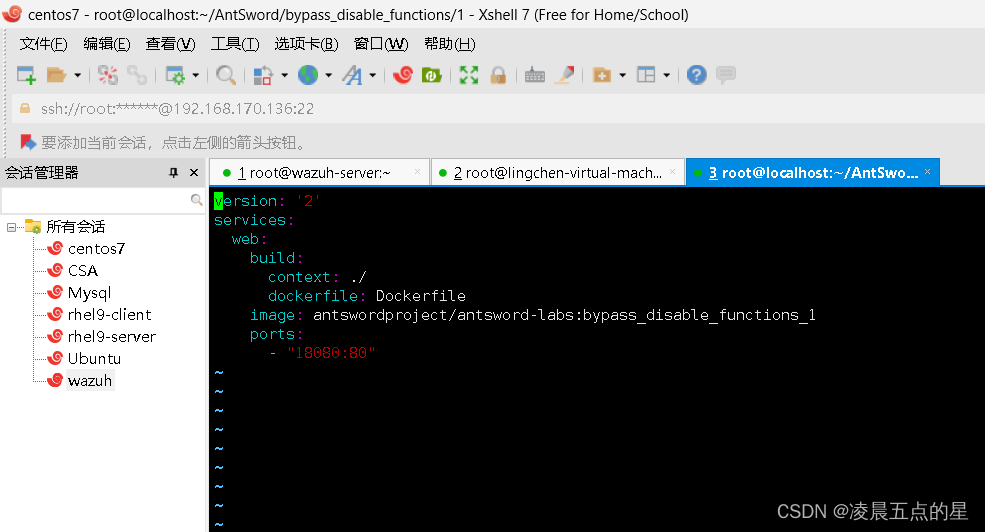
1.3部署docker文件下的环境

1.4使用蚁剑连接
查看木马连接成功:


1.5 所有的命令无法执行: (shell废除)
限制所有执行函数:


三、问题解决
函数被禁用????无法劫持怎么办??
3.1方法:
第一:php需要启动一个新的进程
第二:控制环境变量

3.2出现子进程
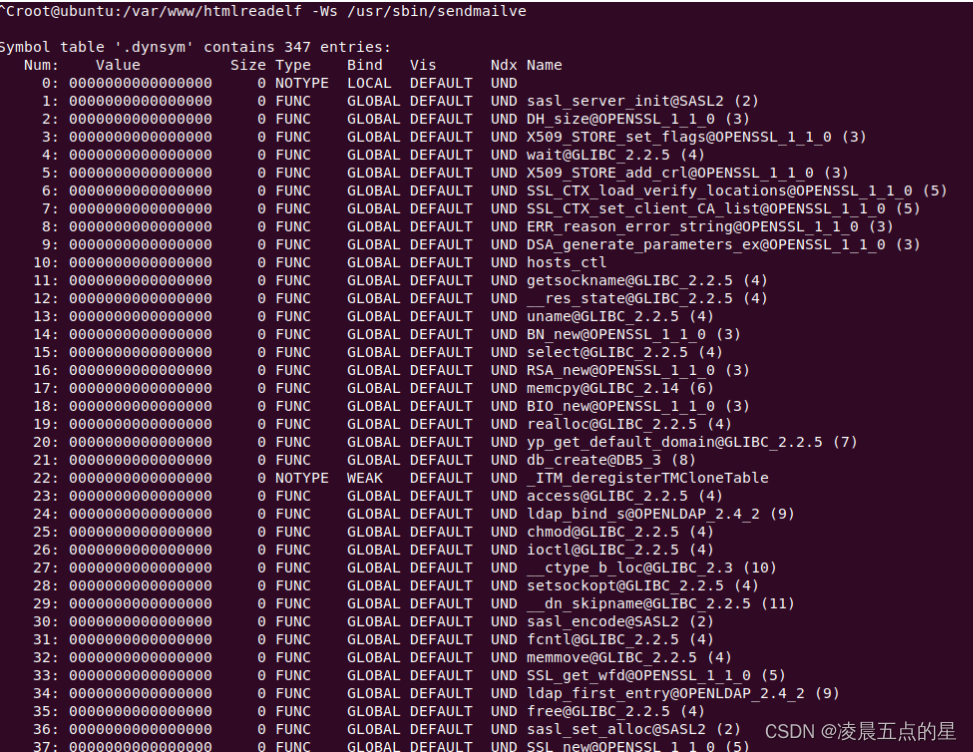
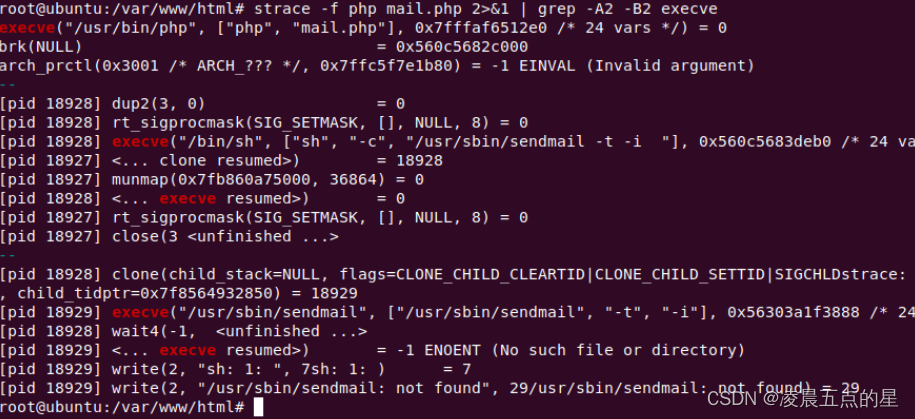 3.3实现
3.3实现
四、总结
第一步:编写php文件--》查看哪一个php函数可以执行进程---》使用strace追踪php函数---》找到最容易写的函数劫持,利用php重新设置其环境变量