中国空间站拒绝10国名单做网站服务器空间
pwndbg安装(gdb插件)
源地址:https://github.com/pwndbg/pwndbg
手动安装
git clone https://github.com/pwndbg/pwndbg
cd pwndbg
./setup.sh
没啥问题运行gdb的话就可以看到明显的不同了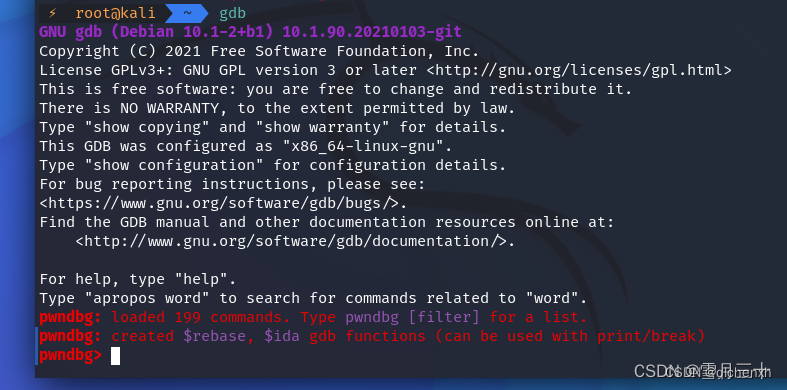
如果安装成功了,但没有生效
如果有问题的话就去检查一下自己的家目录中的.gdbinit配置文件(没有的话需要手动创建)
vim ~/.gdbinit
其中~是/home/登录用户名
ls -a 可以显示隐藏文件
添加上刚才git的文件中的gdbinit.py路径
source /xx/pwndbg/pwndbg-dev/pwndbg-dev/gdbinit.pygdbinit.py文件可以用find找到该文件的位置
然后source一下
source ~/.gdbinit再次运行gdb检查效果

原文链接:https://blog.csdn.net/weixin_49764009/article/details/124918438