门户网站开发教程网站建设dyfwzx
《捕鱼_ue4-5输出带技能的透明通道素材到AE步骤》
2022-05-17 11:06
先看下带透明的特效素材效果
1、首先在项目设置里搜索alpha,在后期处理标签设置最后一项allow through tonemapper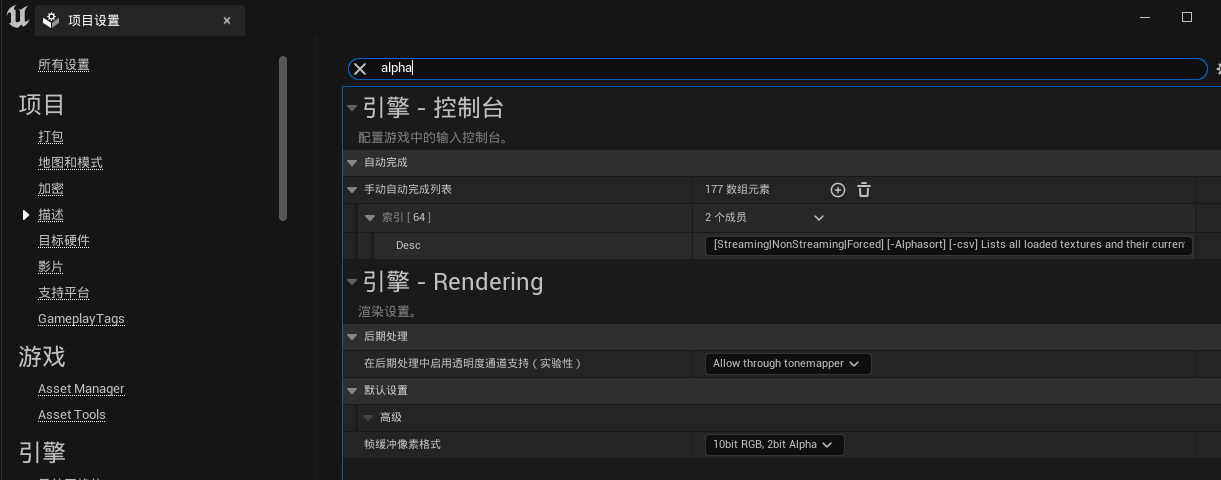
2、在插件管理器中,搜索movie render ,加载movie render queue新型序列帧导出工具。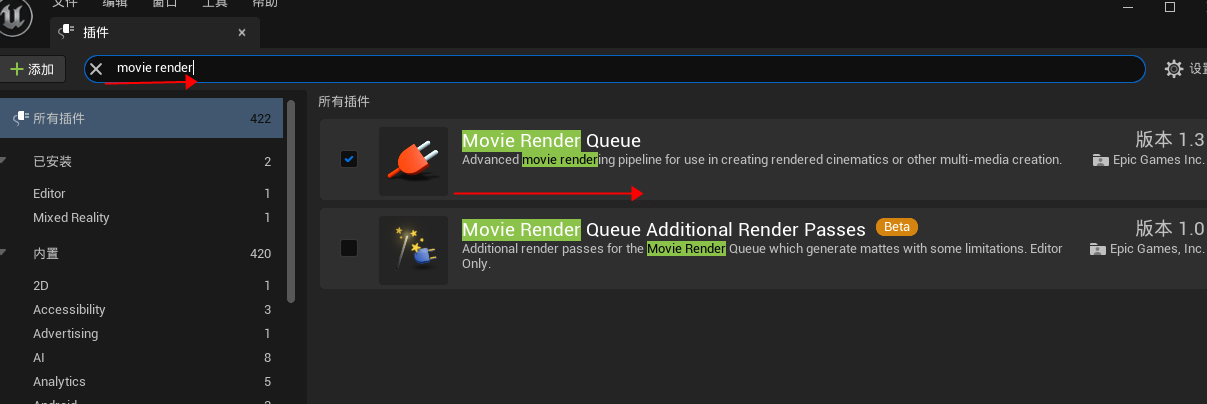
3、然后重启ue4,或者ue5. 等待它重新编译引擎。需要比较漫长时间。编译好后进入引擎。
4、然后再在ue5定序器里找到新的插件,ue4在窗口菜单第一个命令过长动画,找到影片渲染队列 movie render queue
ue4里这样找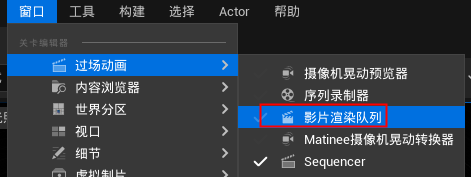
ue5里这样找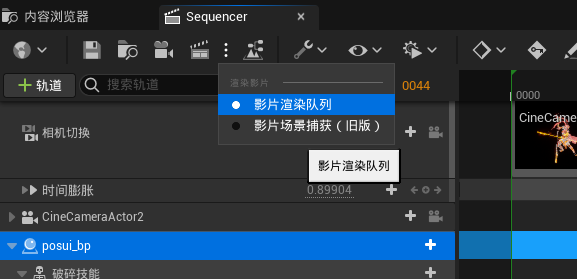
5、点击左边的场记板图标加载场景和定序器到影片渲染队列 movie render queue。点设置,删除jpg序列,添加png序列,和抗锯齿。
在渲染,延迟渲染里勾选accumulator include alpha 。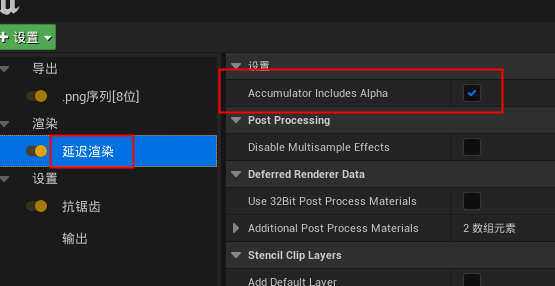
抗锯齿里勾选override anti aliasing 重写抗锯齿。选择其中一项抗锯齿。比如多重采样抗锯齿
movie render queue>seting>anti-aliasing>render settings>
spatial sample count=3 (值太高了会导致粒子不同步,出问题)
temporal sample count=3 (值太高了会导致粒子不同步,出问题)
anti aliasing Method 设置为多重采样抗锯齿 MSAA
另外post后期后期里要设置运动模糊为0.5默认值,不然会报错
另外后期iToo many temporal samples for the given shutter angle/tick rate combination.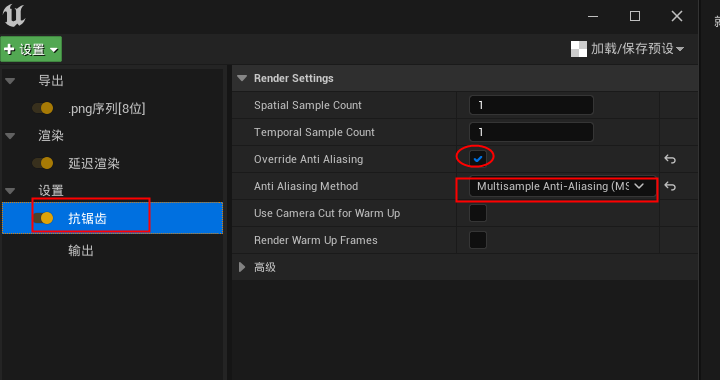
输出设置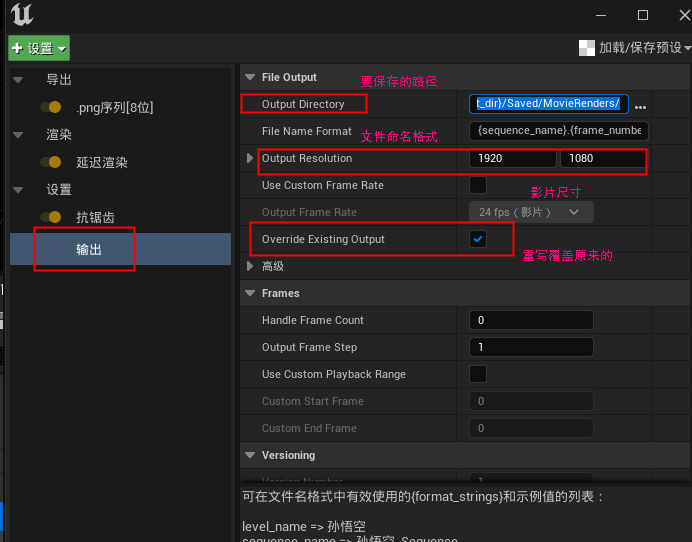
输出完的序列帧是这样的:模型部分是带完整透明的alpha通道,但特效部分(addtive叠加材质)却是丢失!
8、再在 movie render queue里,在渲染,延迟渲染里取消accumulator include alpha 。输出一批黑底的特效素材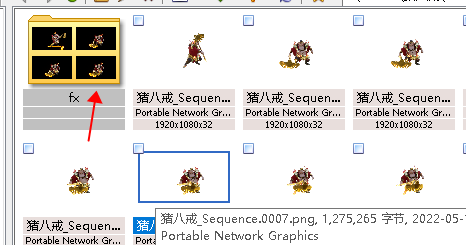
9、在ae里导入这两个队列的素材。一个带透明的模型(带有叠加在它身上的特效)。还有一个是不透明的完整特效和模型。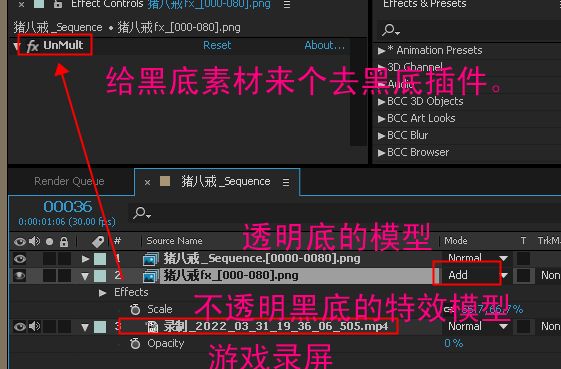
叠出来的透明模型和透明特效效果。
透明12_最终给到审核的带游戏录屏背景合成人物技能及装备特效的mp4录像
评论(0)