wordpress搬站换空间细谈电商网站外链建设的策略
本文摘要
Maven作为Java后端使用频率非常高的一款依赖管理工具,在此咱们由浅入深,分三篇文章(Maven基础、Maven进阶、私服搭建)来深入学习Maven,此篇为开篇主要介绍Maven进阶知识,包含坐标、依赖、仓库、生命周期、插件、继承
文章目录
- 本文摘要
- 1. 坐标
- 1.1 坐标含义
- 2. 依赖
- 2.1 依赖范围
- 1. classpath
- 2. scope
- 2.2 依赖传递
- 2.3 依赖冲突
- 2.4 依赖阻断
- 3. 仓库
- 3.1 仓库配置
- 3.1.1 本地仓库
- 3.1.2 中央仓库-阿里云仓库配置
- 4. 生命周期
- 5. 插件
- 6. 继承
- 6.2 可继承的pom元素
- 6.3 dependencyManagement
- 6.4 porperties
1. 坐标
坐标是构件的唯一标识,Maven 坐标的元素包括groupId、artifactId、version、packaging、classifier。上述5个元素中,groupId、artifactId、version 是必须定义的,packaging 是可选的 ( 默认为 jar )
1.1 坐标含义
<groupId>org.example</groupId>
<artifactId>study-maven</artifactId>
<version>1.0-SNAPSHOT</version>
| 坐标元素 | 含义 | 举例 |
|---|---|---|
| groupId | 组织标识,一般为:公司网址反写+项目名 | org.example |
| artifactId | 项目名称,一般为:项目名-模块名 | study-maven |
| version | 版本号0.0.1-SNAPSHOPT 第一个0表示大版本号 第二个0表示分支版本号 第三个0表示小版本号 SNAPSHOT:快照 ALPHA:内测版本 BETA:公测版本 RELEASE:稳定版本 GA:正式版本 | study-maven |
| packaging | 打包方式 | pom jar maven-plugin ejb war … |
| clissifier | 用来帮助定义构件输出的一些附属构件,通常不用 |
2. 依赖
2.1 依赖范围
1. classpath
Maven项目在开发工程中有三套classpath
- 主代码:main下面的都是主代码在编译的时候的依赖
- 测试代码:test下是测试代码编译的时候的依赖
- 运行时:main代码在运行的时候对包的依赖
依赖范围的使用,通过在引用第三方依赖时的标签进行设置,例如:
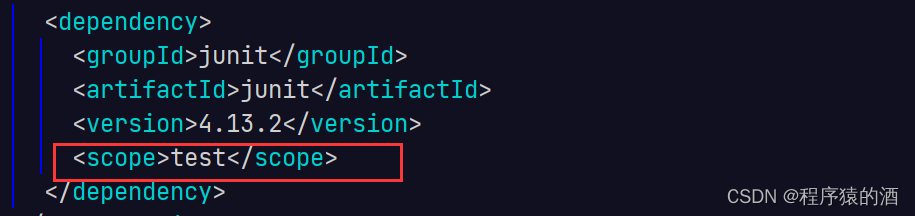
2. scope
Maven中共 6 种 scope,包括:compile、provided、runtime、test、system、import,但实际生产中用得最多的也就标红的四种
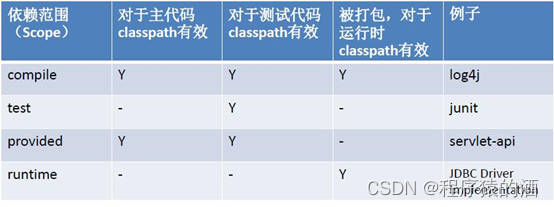
- compile:在编译、测试、打包时都会将jar包打进项目中
- test:只在运行测试classpath里边的代码才会生效
- provided:只能测试、main的classpath代码生效,runtime的classpath无效
- runtime:只有在runtime的classpath环境下生效
2.2 依赖传递
依赖传递指:A项目依赖了B项目,B项目依赖了C项目,则A项目中也会引入C项目,其中A依赖B被称为第一传递依赖,B依赖C被称为第二传递依赖

依赖传递原则
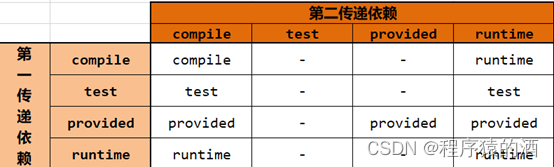
2.3 依赖冲突
依赖冲突指:A项目依赖B项目,B项目依赖C项目的1.0版本,同时A项目依赖D项目的1.1版本,根据依赖传递则A项目中同时具有D项目的1.0、1.1版本,此时就存在依赖冲突
冲突解决
- 谁先声明,谁有效,如下1.0版本先声明,故a项目中使用的是c项目的1.0版本
<!-- b项目依赖c项目1.0版本 --><dependency><groupId>org.example</groupId><artifactId>maven-b</artifactId><version>1.0-SNAPSHOT</version></dependency><!-- b项目依赖c项目1.1版本 --><dependency><groupId>org.example</groupId><artifactId>maven-b</artifactId><version>1.1-SNAPSHOT</version></dependency>
- 直接引入比依赖传递更具优先性,如下a项目直接引入c项目,故a项目中c项目的1.1版本生效
<!-- b项目依赖c项目1.0版本 --><dependency><groupId>org.example</groupId><artifactId>maven-b</artifactId><version>1.0-SNAPSHOT</version></dependency><!-- a目直接项依赖c项目1.1版本 --><dependency><groupId>org.example</groupId><artifactId>maven-c</artifactId><version>1.1-SNAPSHOT</version></dependency>
- 排除依赖,直接排除b项目中的c依赖,故而a项目使用c项目的1.1版本
<!-- b项目依赖c项目1.0版本 -->
<dependency><groupId>org.example</groupId><artifactId>maven-b</artifactId><version>1.0-SNAPSHOT</version><exclusions><exclusion><groupId>org.example</groupId><artifactId>maven-b</artifactId></exclusion></exclusions>
</dependency><!-- b项目依赖c项目1.1版本 -->
<dependency><groupId>org.example</groupId><artifactId>maven-b</artifactId><version>1.1-SNAPSHOT</version>
</dependency>
2.4 依赖阻断
- 当项目b被其它项目引用时,不传递c依赖
<dependency><groupId>org.example</groupId><artifactId>maven-c</artifactId><version>1.0-SNAPSHOT</version><optional>true</optional></dependency>
3. 仓库
仓库分类:仓库分为本地仓库、中央仓库、远程仓库,其中本地仓库即个人配置的本地仓库、远程仓库即公司配置的私服仓库、中央仓库即为apache或阿里配置的仓库
3.1 仓库配置
3.1.1 本地仓库
<localRepository>D:\repo</localRepository>
3.1.2 中央仓库-阿里云仓库配置
<mirrors><mirror><id>alimaven</id><mirrorOf>central</mirrorOf><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url></mirror>
</mirrors>
4. 生命周期
生命周期:maven有三种生命周期,clean、default、site,每个生命周期又包含不同的阶段,后一阶段的执行都必须先执行前一阶段指令后才执行下一阶段指令
| 生命周期 | clean | default | site |
| 阶段(phase),执行顺序由上至下 | pre-clean | validate | pre-site |
| clean | initialize | site | |
| post-clean | generate-sources | post-site | |
| process-sources | site-deploy | ||
| generate-resources | |||
| process-resources | |||
| compile | |||
| process-classes | |||
| generate-test-sources | |||
| generate-test-resources | |||
| process-test-resources | |||
| test-compile | |||
| process-test-classes | |||
| test | |||
| prepare-package | |||
| package | |||
| pre-integration-test | |||
| integration-test | |||
| post-integration-test | |||
| verify | |||
| install | |||
| deploy |
5. 插件
maven插件的执行实际就是从中央仓库拉取插件jar包,然后通过执行对应命令方式来执行插件,因此当我们在执行插件时,卡着不动,可以考虑将阿里云中央仓库给注释掉,直接从apache中央仓库拉取
<build><plugins><!--配置编译插件,通常自带编译插件版本较老,因而我们需要重新配置 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><!-- Javaweb项目我们可以通过配置tomcat插件来运行项目 --><plugin><groupId>org.apache.tomcat.maven</groupId><artifactId>tomcat7-maven-plugin</artifactId><version>2.2</version><configuration><!--端口控制--><port>8080</port><!--项目路径控制意味着http://localhost:8080/abc--><path>/abc</path><!--编码--><uriEncoding>UTF-8</uriEncoding></configuration></plugin></plugins>
</build>
6. 继承
- 父工程pom
- packaging为pom
- modules中包含了子工程坐标
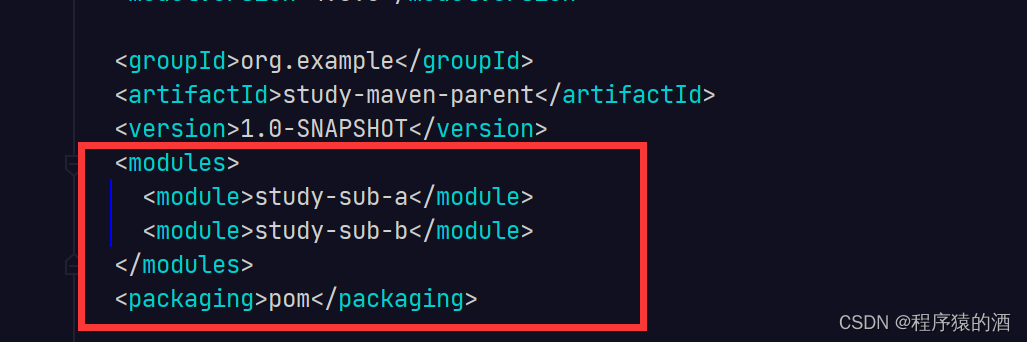
- 子工程

6.2 可继承的pom元素
- groupId:项目组 ID ,项目坐标的核心元素;
- version:项目版本,项目坐标的核心元素;
- properties:自定义的 Maven 属性;
- dependencies:项目的依赖配置;
- dependencyManagement:醒目的依赖管理配置;
6.3 dependencyManagement
父类通过dependencyManagement来控制所要引入的依赖和对应版本,子类根据选择,只需要引入对应坐标即可,无需重新定义版本号,从而来控制依赖版本,此时依赖只做依赖定义,并未进行依赖引入
<dependencyManagement><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.83</version></dependency></dependencies></dependencyManagement>
<dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency></dependencies>
6.4 porperties
properties用于定义统一版本
<!-- 通过properties定义,通过${}方式使用 -->
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><fastjson>1.2.83</fastjson>
</properties><dependencyManagement><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson}</version></dependency></dependencies>
</dependencyManagement>