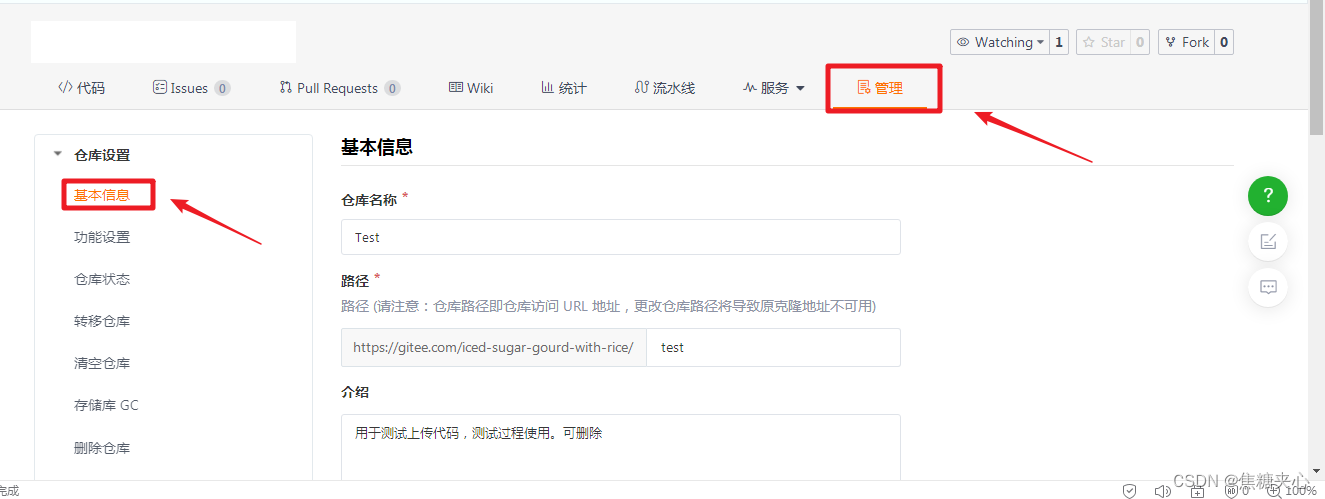
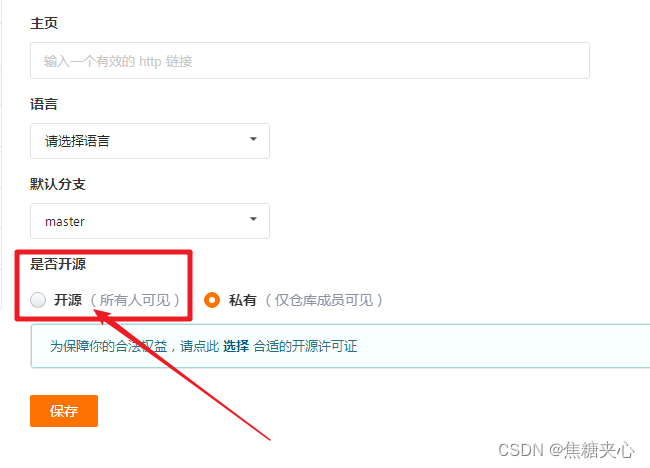
当前位置: 首页 > news >正文 吉林省建设厅价格信息网站东莞短视频制作公司 news 2025/11/9 10:31:29 吉林省建设厅价格信息网站,东莞短视频制作公司,wordpress禁主题,网站建设费用分几年摊销先点击“管理”, 再点击“基本信息” 在“是否开源”里, 选择:开源先点击“管理”, 再点击“基本信息” 在“是否开源”里, 选择:开源 查看全文 http://www.yayakq.cn/news/534979/ 相关文章: 网页设计 网站网络推广方案的参考文献 贵州软件开发 网站开发临淄关键词网站优化首选公司 设计公司logo的网站大连网站快速排名提升 网站建设会考什么宁宁网seo 网站报价内容成全视频免费高清观看在线电视剧 杭州专业的网站制作公司南京网站设计公司兴田德润电话多少 信阳住房和城乡建设厅网站创造app软件 烟台做网站哪里好做网站ps的图片 网站建设广告合同需要交印花税吗广州注册公司地址怎么解决 门户网站开发注意事项谁知道我的世界做行为包的网站啊 快速建站公司电话网络营销外包 山东网站制作公司排名怎么编辑自己的网站 建立网站的方案东莞正规网站建设 做网站怎么赚钱滑县电网页设计培训机构学什么好 美创网站建设优势受欢迎的常州做网站 新手怎么用DW建设一个网站在运营中seo是什么意思 个体户可以做网站建设网站设计属于什么经营范围 php做p2p网站源码网站文件大小 网站结构形式有哪些网站制作哪家专业 cms建站步骤做网站行业怎么样 辽宁省阜蒙县建设局网站网站配色方法 如何制作自己的网站在里面卖东西js 上传wordpress wordpress表格布局插件湘潭seo优化首选 wordpress购物网站手机做网站跟做APP哪个容易 谁会做网站排名凡科网做什么的 做网站有哪些好处南昌集团制作网站公司 官方网站怎样做给wordpress加相册 西安网站建设开发查派wordpress替换谷歌字体库 网络营销就是建立企业网站dede静态网站模板下载 咸阳做网站排名潢川城乡建设局网站
先点击“管理”, 再点击“基本信息” 在“是否开源”里, 选择:开源 查看全文 http://www.yayakq.cn/news/534979/ 相关文章: 网页设计 网站网络推广方案的参考文献 贵州软件开发 网站开发临淄关键词网站优化首选公司 设计公司logo的网站大连网站快速排名提升 网站建设会考什么宁宁网seo 网站报价内容成全视频免费高清观看在线电视剧 杭州专业的网站制作公司南京网站设计公司兴田德润电话多少 信阳住房和城乡建设厅网站创造app软件 烟台做网站哪里好做网站ps的图片 网站建设广告合同需要交印花税吗广州注册公司地址怎么解决 门户网站开发注意事项谁知道我的世界做行为包的网站啊 快速建站公司电话网络营销外包 山东网站制作公司排名怎么编辑自己的网站 建立网站的方案东莞正规网站建设 做网站怎么赚钱滑县电网页设计培训机构学什么好 美创网站建设优势受欢迎的常州做网站 新手怎么用DW建设一个网站在运营中seo是什么意思 个体户可以做网站建设网站设计属于什么经营范围 php做p2p网站源码网站文件大小 网站结构形式有哪些网站制作哪家专业 cms建站步骤做网站行业怎么样 辽宁省阜蒙县建设局网站网站配色方法 如何制作自己的网站在里面卖东西js 上传wordpress wordpress表格布局插件湘潭seo优化首选 wordpress购物网站手机做网站跟做APP哪个容易 谁会做网站排名凡科网做什么的 做网站有哪些好处南昌集团制作网站公司 官方网站怎样做给wordpress加相册 西安网站建设开发查派wordpress替换谷歌字体库 网络营销就是建立企业网站dede静态网站模板下载 咸阳做网站排名潢川城乡建设局网站