淄博网站客户防封电销系统
MidJourney付费失败的原因
MidJourney付费失败的原因可能包括支付方式无效、支付信息错误、网络问题、账户设置问题等。
- 支付方式无效或信息错误:如果用户提供的支付方式(如信用卡)信息不正确,或者支付方式本身不支持该地区的交易,会导致支付失败。例如,用户可能需要检查填入的信用卡信息是否准确,包括卡号、有效期、CVV等。
- 网络问题:网络不稳定或使用的支付节点不适合当前交易,也可能导致支付失败。解决这一问题可能需要更换支付节点或尝试使用不同的网络环境(魔法的问题,这个不详细说明)。
- 账户设置问题:如果用户没有正确设置账户以支持连续订阅,可能会导致续费失败。例如,如果你打算为他人代充,需要确保取消连续订阅设置,以避免连续扣费。
- 地区限制:当前的支付方式可能不支持地区的交易,或者存在地区限制。在这种情况下,需要开通虚拟信用卡或使用其他支付方式来完成支付(比如让国外的朋友帮忙支付)。
MidJourney 付费失败后如何取消或续订
1:登陆 MidJourney 的 Stripe 页面
输入你注册 discord 的邮箱。然后在邮箱里面接收一封 Stripe 的邮箱,点击登录就可以了。
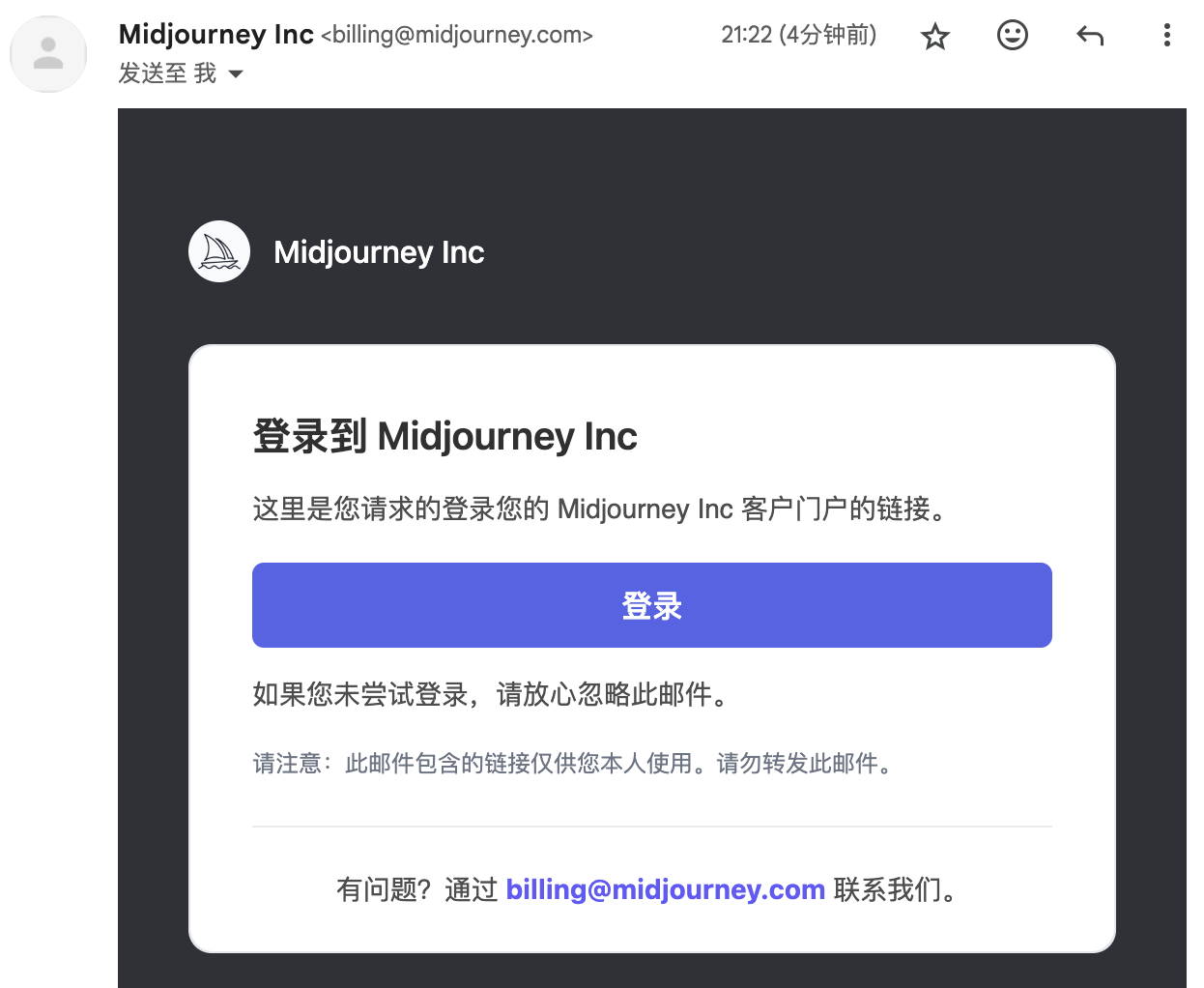
2:进入邮箱点击这封邮件里面的「登录」。
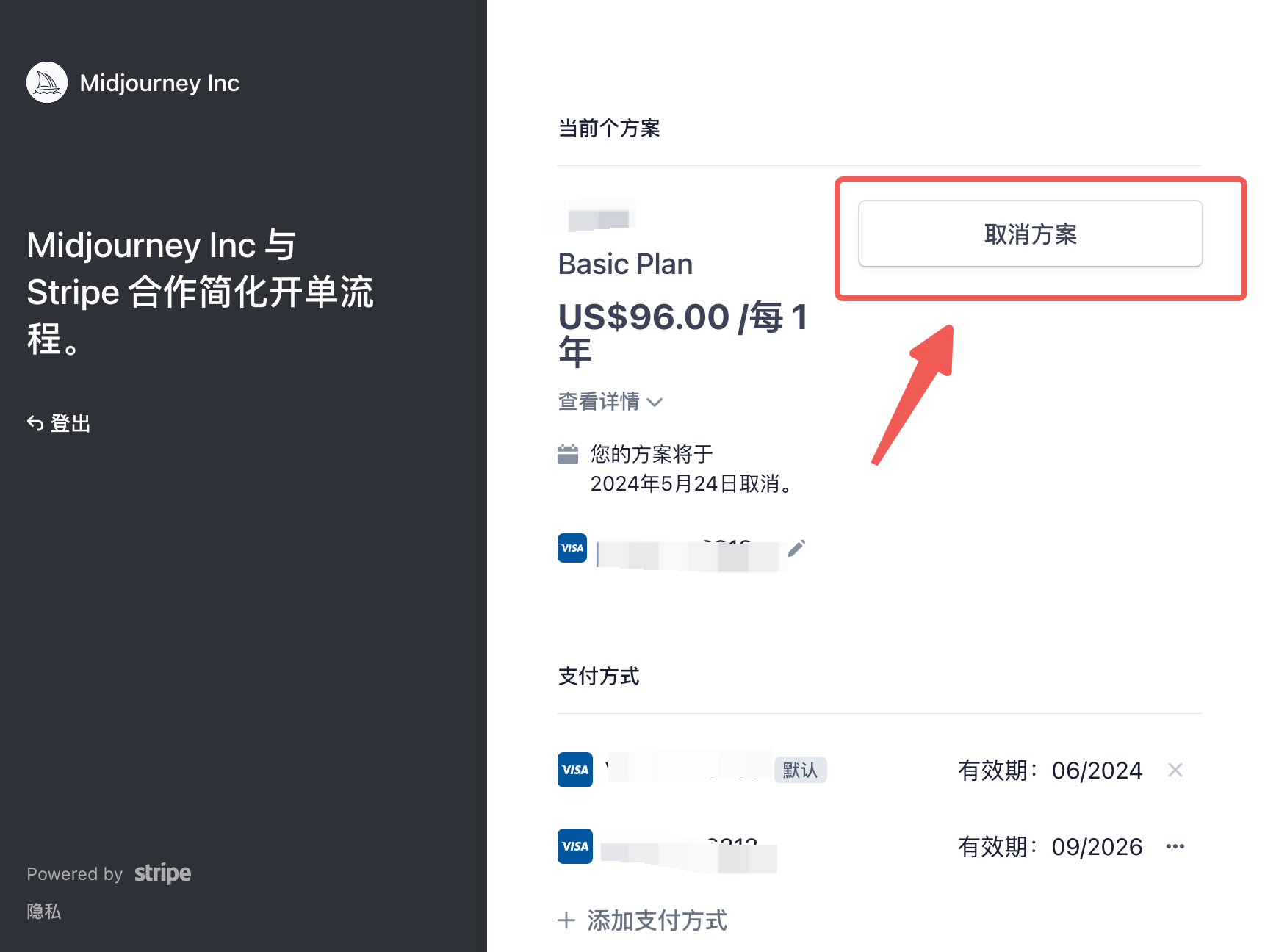
3:取消方案
进入 MidJourney 的 Stripe 页面后,点击「取消方案」可以取消订阅。
4:续订MidJourney
1.如果你是卡被封或失效,在这里把旧日卡删除掉,加入新卡的信息。注册新卡
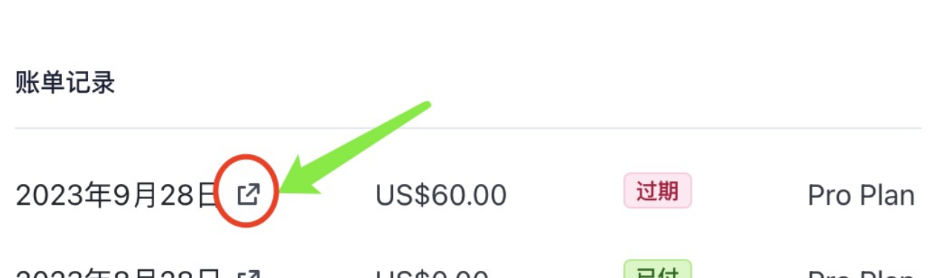
2.如果你是卡里的余额不足,或之前不用故意没续,确保卡里余额充足后,拉到页面底部,找到账单记录(见下图),在最新的一个付款失败的条目左侧,找到那个打开账单的链接按钮,打开新页面,然后支付即可。
总结
解决MidJourney付费失败的问题,可以尝试以下方法:
- 检查并确保支付信息准确无误。
- 尝试更换支付节点或网络环境。
- 确保账户设置正确,特别是如果涉及为他人代充,需要取消连续订阅设置。
- 考虑使用虚拟信用卡或其他支持的支付方式完成支付。
友情链接:MidJourney教程
GPT-4o教程
原文链接:MidJourney 付费失败的原因以及失败后如何取消或续订(文末附 MidJourney,GPT-4o 教程)