扁平化颜色网站wordpress登陆后台总是跳转首页
微信云托管
🚨推荐:微信云托管:基本使用指南
确实是个好平台,部署个项目很简易,免去了很多运维上的事情。
一、微信云托管 github 流水线配置 和 端口号
- 首先,这里的
主体(宿主机),指的就是你的代码本身,可以理解为有一个服务器拉取了你的代码。
- 例如:Dockerfile文件中,指令:
COPY src /demo-server/src中的src目录,就是代码路径中的src目录。
- 编写Dockerfile文件(根据Dockerfile,创建镜像,启动容器)
- 例如:如何写一个Dockerfile文件?
# 选择构建用基础镜像。如需更换,请到[dockerhub官方仓库](https://hub.docker.com/_/java?tab=tags)自行选择后替换。
FROM maven:3.6.0-jdk-8-slim as build
# 指定构建过程中的工作目录
WORKDIR /demo-server
# 将src目录下所有文件,拷贝到工作目录中src目录下(.gitignore/.dockerignore中文件除外)
COPY src /demo-server/src
# 将pom.xml文件和settings.xml文件,拷贝到工作目录下
COPY settings.xml pom.xml /demo-server/
# 自定义settings.xml, 选用国内镜像源以提高下载速度
RUN mvn -s /demo-server/settings.xml -f /demo-server/pom.xml clean package# 基础镜像
FROM openjdk:8-jre
# 作者
MAINTAINER holmes
# 设置工作目录
WORKDIR /demo-server
# 复制jar包
COPY --from=build /demo-server/target/*.jar .
# 暴露端口
EXPOSE 80
# 启动程序
CMD ["java","-jar","demo-server-1.0-SNAPSHOT.jar"]
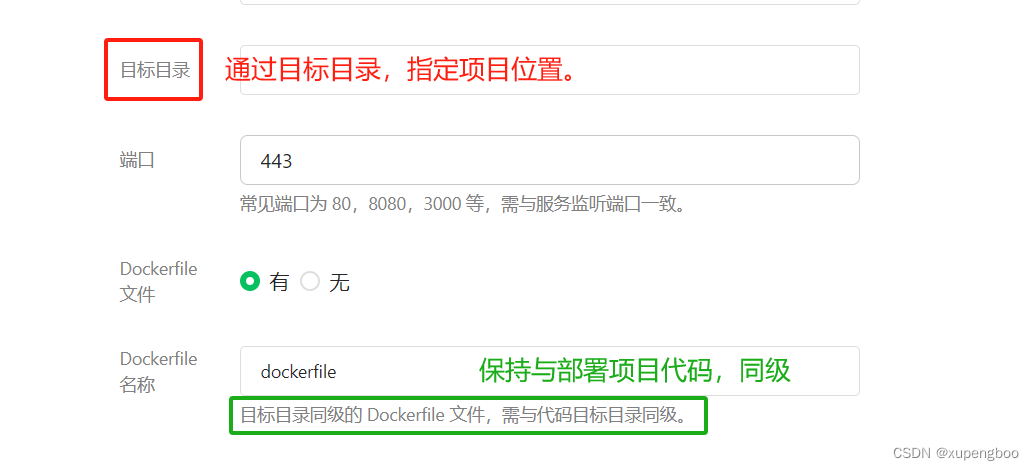
- 明白项目,采用哪个端口号。
- 微信云托管-流水线配置、Dockerfile、服务配置都会有端口号,要明确配置的端口号是哪个。
- http 80 和 https 443 ,这两个协议默认的端口,大家都知道,但是也很容易忽略!
- Dockerfile文件和要部署的项目目录,同级目录才可。(可以通过 目标目录 来锁定目录位置。)
🎈参考官方:https://github.com/WeixinCloud/wxcloudrun-springboot
二、如何使用服务 基础信息-环境变量 ?
在微信云托管中,通过配置环境变量,你可以向容器传递需要的配置信息。这类似于在 Docker 中使用 -e 或 --env 选项来设置环境变量,注意此处是类似,并不是等同于!。
微信云托管中的环境变量配置可能类似于以下 Docker 命令:
docker run -e KEY1=value1 -e KEY2=value2 -e ANOTHER_KEY=another_value my_image
上述命令中,-e 选项用于设置容器中的环境变量,KEY1、KEY2 和 ANOTHER_KEY 是环境变量的名称,而 value1、value2 和 another_value 则是相应环境变量的值。
提醒一下,不同服务获取环境变量的语法不同,例如:
SpringBoot 环境变量配置:
- SpringBoot 环境变量替换格式为:${xxx}
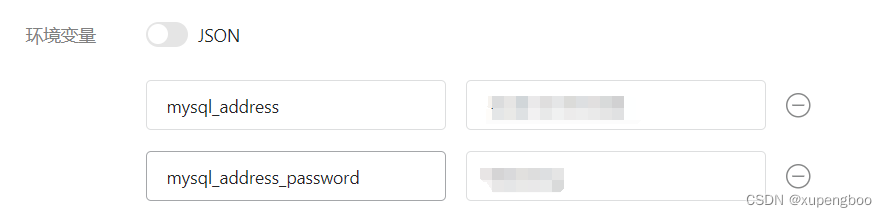
# 开发环境配置
spring:# 数据源配置datasource:type: com.alibaba.druid.pool.DruidDataSourcedriverClassName: com.mysql.cj.jdbc.Driverdruid:# 主库数据源master:url: jdbc:mysql://${mysql_address}/holmes-center?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8username: rootpassword: ${mysql_address_password}
node 环境变量配置:
# 暂未实践
const serverAddress = process.env.SERVER_ADDRESS;
三、如何 配置ngxin.conf 文件?
特意强调一下nginx,nginx.conf是无法动态获取微信云托管的环境变量配置!微信云托管设置的这些环境变量可以在应用程序中读取,不能再nginx配置文件读取,同样其他的一些中间件也是一样!
Nginx.conf中的$xxx,获取的是容器内部的系统环境变量,如下:
location /prod-api/ {rewrite ^/prod-api(/.*)$ $1 break;# $host是容器系统的环境变量proxy_pass $host;
}
一开始我就以为微信云托管服务配置的环境变量就和 docker -env 参数一样是的,给系统添加环境变量,就能给nginx.conf动态配置了,操作了半天也不管用。咨询了半天总结出来就是:不同的工具和平台而有所差异,微信云托管的环境变量 和 docker -env参数环境变量 ,在效果上,只能说是类似,不能说完全相同!
所以,微信云托管要是配置nginx服务,目前总结出两种方式:
- 直接在nginx.conf或者Dockerfile文件中写死就行,一般内网域名啥的不会变化,也不用担心暴露。
- 通过写脚本,先将云托管的环境变量读取到脚本中,再写入到nginx.conf文件。
#!/bin/bash
# 读取微信云托管的环境变量
SERVER_ADDRESS=$SERVER_ADDRESS# 动态生成 Nginx 配置文件
echo "server {listen 80;server_name $SERVER_ADDRESS;# 其他配置...}" > /etc/nginx/conf.d/my_custom_config.conf# 启动 Nginx
nginx -g 'daemon off;'
四、Webshell 使用
因为,经常碰到两个服务之间调不通,所以用好Webshell很方便。
五、内网地址
服务的内网地址,要根据声明暴露的端口号来,并且不是https协议,而是http协议!

举个例子:
假如,内网地址为dlnmpwnf.holmes-center-server.hahsntqc.ie54110f.com,并且暴露的端口是8080端口,那么正确代理配置应该如下:
# 生产环境
location /prod-api/ {rewrite ^/prod-api(/.*)$ $1 break;# 根据 微信云托管后台服务内网 配置proxy_pass http://dlnmpwnf.holmes-center-server.hahsntqc.ie54110f.com:8080/;
}
而不是直接代理到 “https://dlnmpwnf.holmes-center-server.hahsntqc.ie54110f.com” ,此处协议不是https,并且端口也不是443,应该是8080 。
一般内网地址不会是https协议的,其次,端口与暴露的端口一致,并不是直接通过域名映射到指定的ip:端口的!
mpwnf.holmes-center-server.hahsntqc.ie54110f.com" ,此处协议不是https,并且端口也不是443,应该是8080 。
一般内网地址不会是https协议的,其次,端口与暴露的端口一致,并不是直接通过域名映射到指定的ip:端口的!