临清网站建设临清网站突然暴增流量
文章目录
- 什么是ArrayList
- ArrayList相关说明
- ArrayList使用
- ArrayList的构造
- 无参构造
- 指定顺序表初始容量
- 利用其他 Collection 构建 ArrayList
- ArrayList常见操作
- 获取list有效元素个数
- 获取和设置index位置上的元素
- 在list的index位置插入指定元素
- 删除指定元素
- 删除list中index位置上的元素
- 检测list中是否包含指定元素
- 查找指定元素第一次出现的位置
- 截取部分 list
- ArrayList的遍历
- for循环+下标
- foreach
- 使用迭代器
- 注意事项
- ArrayList的扩容机制
- 小结
- ArrayList的具体使用
- 杨辉三角
- 题目描述
- 题目解释:
- 解法思路:
- 代码实现:
- 简单的洗牌算法
- Card类
- 买牌(初始化)
- 洗牌
- 摸牌
- 效果展示:
- 完整代码:
- 总结
什么是ArrayList
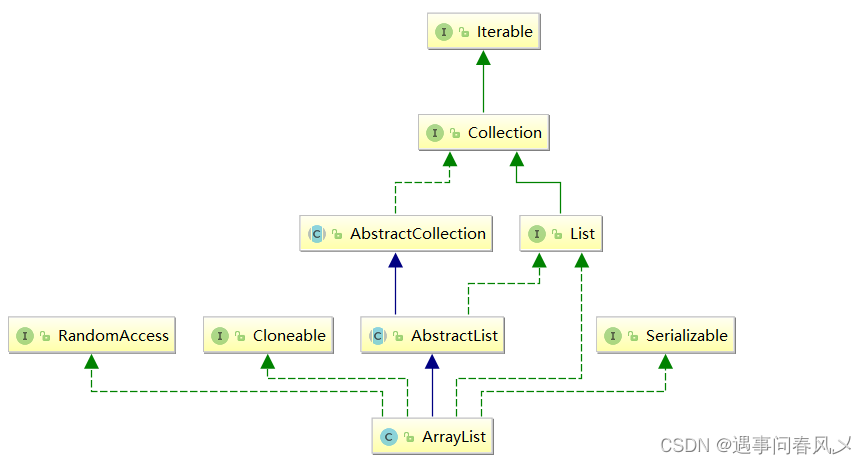
在集合框架中,ArrayList是一个普通的类,实现了List接口,具体框架图如下
ArrayList相关说明
-
ArrayList是以泛型方式实现的,使用时必须要先实例化
-
ArrayList实现了RandomAccess接口,表明ArrayList支持随机访问
-
ArrayList实现了Cloneable接口,表明ArrayList是可以clone的
-
ArrayList实现了Serializable接口,表明ArrayList是支持序列化的
-
和Vector不同,ArrayList不是线程安全的,在单线程下可以使用,在多线程中可以选择Vector或者CopyOnWriteArrayList
-
ArrayList底层是一段连续的空间,并且可以动态扩容,是一个动态类型的顺序表
ArrayList使用
ArrayList的构造
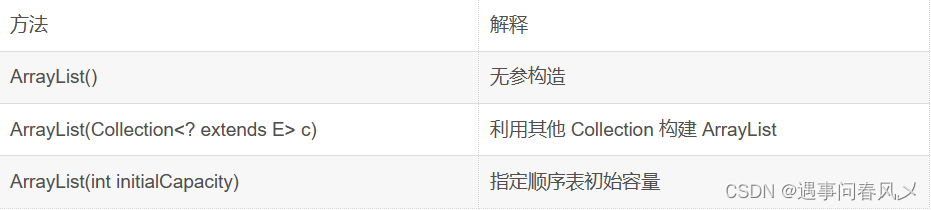
ArrayList的构造有三种
无参构造
ArrayList创建,推荐写法
// 构造一个空的列表
List<Integer> list1 = new ArrayList<>();
指定顺序表初始容量
// 构造一个具有10个容量的列表
List<Integer> list2 = new ArrayList<>(10);
list2.add(1);
list2.add(2);
list2.add(3);
利用其他 Collection 构建 ArrayList
// list3构造好之后,与list2中的元素一致
ArrayList<Integer> list3 = new ArrayList<>(list2);
ArrayList常见操作
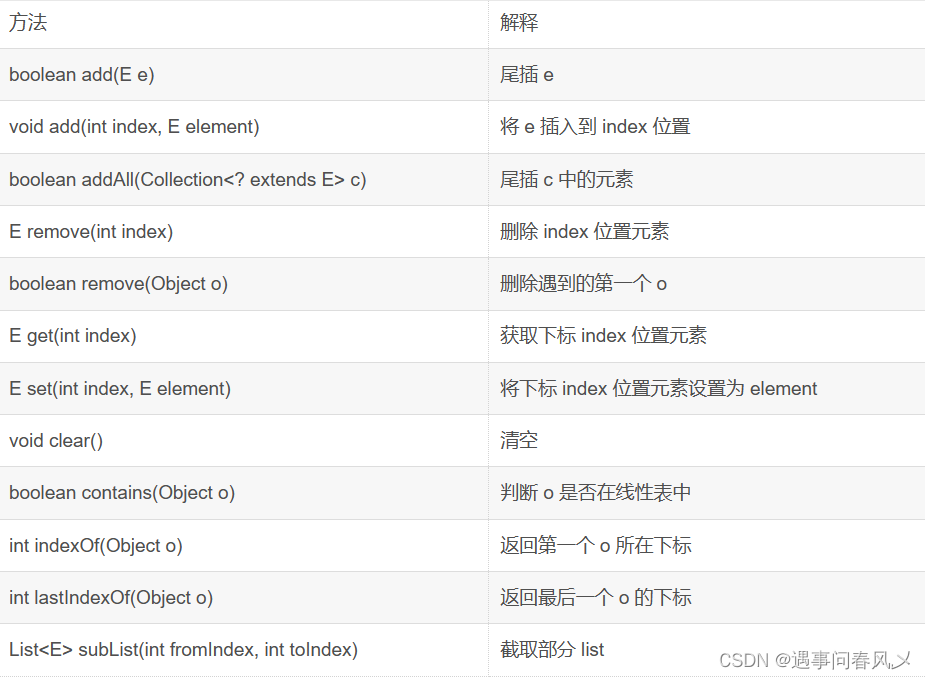
ArrayList虽然提供的方法比较多,但是常用方法如下所示
例如我们有以下代码
List<String> list = new ArrayList<>();
list.add("JavaSE");
list.add("JavaWeb");
list.add("JavaEE");
list.add("遇事问春风乄");
list.add("数据结构");
获取list有效元素个数
// 获取list中有效元素个数
System.out.println(list.size());
获取和设置index位置上的元素
注意:index必须介于[0, size)间
System.out.println(list.get(1));//获取
list.set(1, "JavaWEB");//设置
在list的index位置插入指定元素
在list的index位置插入指定元素后,index及后续的元素统一往后搬移一个位置
list.add(1, "Java数据结构");
删除指定元素
删除指定元素,找到了就删除,该元素之后的元素统一往前搬移一个位置
list.remove("JavaEE")
删除list中index位置上的元素
注意:index不要超过list中有效元素个数,否则会抛出下标越界异常
list.remove(list.size()-1)
检测list中是否包含指定元素
包含返回true,否则返回false
if(list.contains("遇事问春风乄")){list.add("遇事问春风乄");
}
查找指定元素第一次出现的位置
indexOf从前往后找,lastIndexOf从后往前找
//从前往后
System.out.println(list.indexOf("JavaSE"));
//从后往前
System.out.println(list.lastIndexOf("JavaSE"));
截取部分 list
使用list中[0, 4)之间的元素构成一个新的SubList返回,但是和ArrayList共用一个elementData数组
List<String> ret = list.subList(0, 4);
ArrayList的遍历
ArrayList 可以使用三方方式遍历:for循环+下标、foreach、使用迭代器
for循环+下标
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
// 使用下标+for遍历
for (int i = 0; i < list.size(); i++) {System.out.print(list.get(i) + " ");
}
foreach
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
// 借助foreach遍历
for (Integer integer : list) {System.out.print(integer + " ");
}
使用迭代器
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Iterator<Integer> it = list.listIterator();
while(it.hasNext()){System.out.print(it.next() + " ");
}
注意事项
- ArrayList最长使用的遍历方式是:for循环+下标 以及 foreach
- 迭代器是设计模式的一种
ArrayList的扩容机制
ArrayList是一个动态类型的顺序表,即:在插入元素的过程中会自动扩容。
以下是ArrayList源码中扩容方式
Object[] elementData; // 存放元素的空间private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; // 默认空间private static final int DEFAULT_CAPACITY = 10; // 默认容量大小public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}private void ensureCapacityInternal(int minCapacity) {ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static int calculateCapacity(Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {return Math.max(DEFAULT_CAPACITY, minCapacity);}return minCapacity;}private void ensureExplicitCapacity(int minCapacity) {modCount++;
// overflow-conscious codeif (minCapacity - elementData.length > 0)grow(minCapacity);}private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;private void grow(int minCapacity) {
// 获取旧空间大小int oldCapacity = elementData.length;
// 预计按照1.5倍方式扩容int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果用户需要扩容大小 超过 原空间1.5倍,按照用户所需大小扩容if (newCapacity - minCapacity < 0)newCapacity = minCapacity;
// 如果需要扩容大小超过MAX_ARRAY_SIZE,重新计算容量大小if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);
// 调用copyOf扩容elementData = Arrays.copyOf(elementData, newCapacity);}private static int hugeCapacity(int minCapacity) {
// 如果minCapacity小于0,抛出OutOfMemoryError异常if (minCapacity < 0)throw new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;}
小结
-
检测是否真正需要扩容,如果是调用grow准备扩容
-
预估需要库容的大小
初步预估按照1.5倍大小扩容
如果用户所需大小超过预估1.5倍大小,则按照用户所需大小扩容
真正扩容之前检测是否能扩容成功,防止太大导致扩容失败 -
使用copyOf进行扩容
ArrayList的具体使用
杨辉三角
题目描述
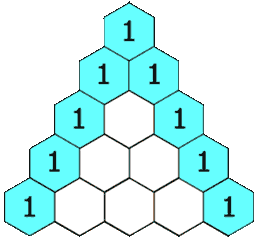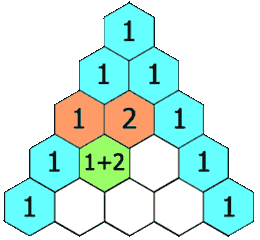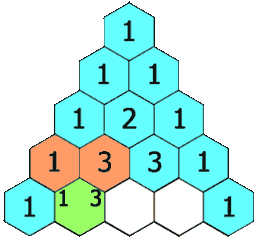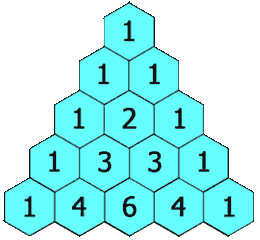
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
题目解释:
题中返回值为 List<List< Integer > >,意思为返回一个List,这个List里面的每一个元素也为List
解法思路:
List里面放List可以类似与我们的二维数组,而我们的杨辉三角也可以看成一个二维数组
比如我们现在有一个List实例为ret,ret里面存放的是List类型的元素;ret的每一个List元素里存放的是杨辉三角每一行的所有元素
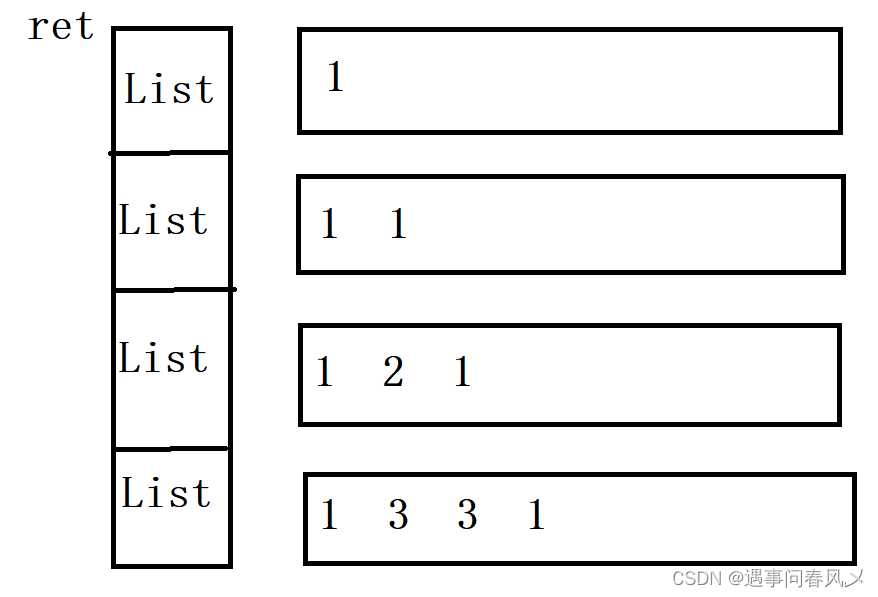
通过观察我们发现,杨辉三角的第一位总是1,并且每一行的最后一个与第一个都为1;其余的等于上面一行的两个数相加
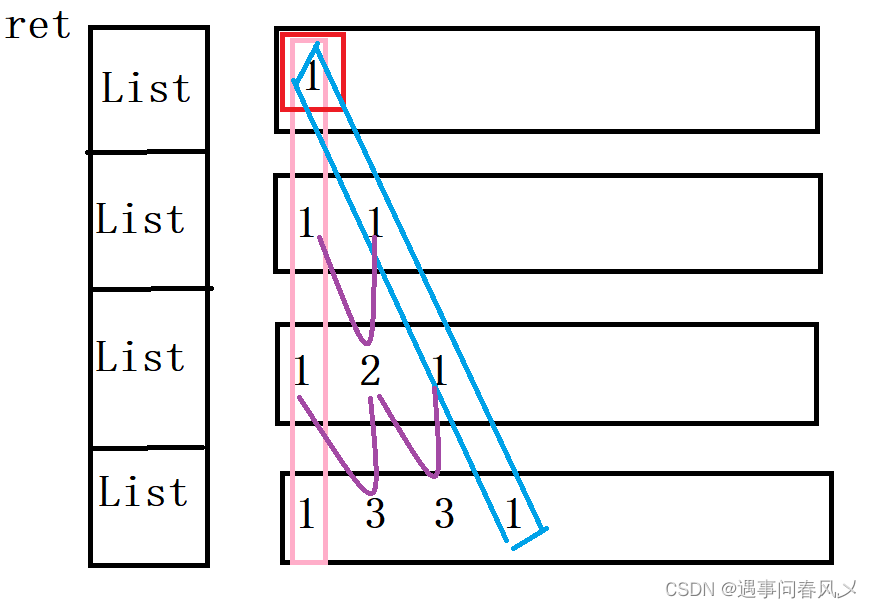
代码实现:
class Solution {public List<List<Integer>> generate(int numRows) {List<List<Integer>> ret = new ArrayList<>();List<Integer> row = new ArrayList<>();ret.add(row);row.add(1);for(int i = 1;i < numRows;i++) {List<Integer> row1 = ret.get(i-1);List<Integer> row2 = new ArrayList<>(i);ret.add(row2);row2.add(1);for(int j = 1;j < i;j++){int h = row1.get(j) + row1.get(j-1);row2.add(h);}row2.add(1);}return ret;}
}
简单的洗牌算法

比如我们现在需要实现一个简单的炸金花
Card类
那么我们首先第一步,我们得了解一下扑克,我们除开大小王,就剩下52张牌。每张牌都有相应的面额和花色

那么我们便可以建立一个Card类用于描述我们的扑克
class Card {public int rank; // 牌面值public String suit; // 花色@Overridepublic String toString() {return String.format("[%s %d]", suit, rank);}
}
买牌(初始化)
接下来我们需要买一副牌,其实也就是对我们的牌进行初始化
一共四个花色,每一种花色对应13张牌
public static final String[] SUITS = {"♠", "♥", "♣", "♦"};// 买一副牌private static List<Card> buyDeck() {List<Card> deck = new ArrayList<>(52);for (int i = 0; i < 4; i++) {for (int j = 1; j <= 13; j++) {String suit = SUITS[i];int rank = j;Card card = new Card();card.rank = rank;card.suit = suit;deck.add(card);}}return deck;}
洗牌
买回来的牌肯定不能直接完,所以我们要进行洗牌
在洗牌环节我们会对一张张牌进行遍历,然后让该牌于随机的一张牌进行交换
这里为了随机数产生方便,我们选择从后往前遍历
private static void swap(List<Card> deck, int i, int j) {Card t = deck.get(i);deck.set(i, deck.get(j));deck.set(j, t);}private static void shuffle(List<Card> deck) {Random random = new Random();//随机数for (int i = deck.size() - 1; i > 0; i--) {int r = random.nextInt(i);swap(deck, i, r);}}
摸牌
三个人轮流摸牌,我闷这里采用二维数组的思想来实现,也就是List里面的元素是List
摸一张牌,排队里就少一张牌,这里操作起来非常简单,我们只需要将牌堆deck的0下标进行删除就好
使用E remove(int index)删除当前下标的元素,并返回该元素,将该元素添加到每一位玩家的手中
List<List<Card>> hands = new ArrayList<>();hands.add(new ArrayList<>());hands.add(new ArrayList<>());hands.add(new ArrayList<>());for (int i = 0; i < 3; i++) {for (int j = 0; j < 3; j++) {hands.get(j).add(deck.remove(0));}}
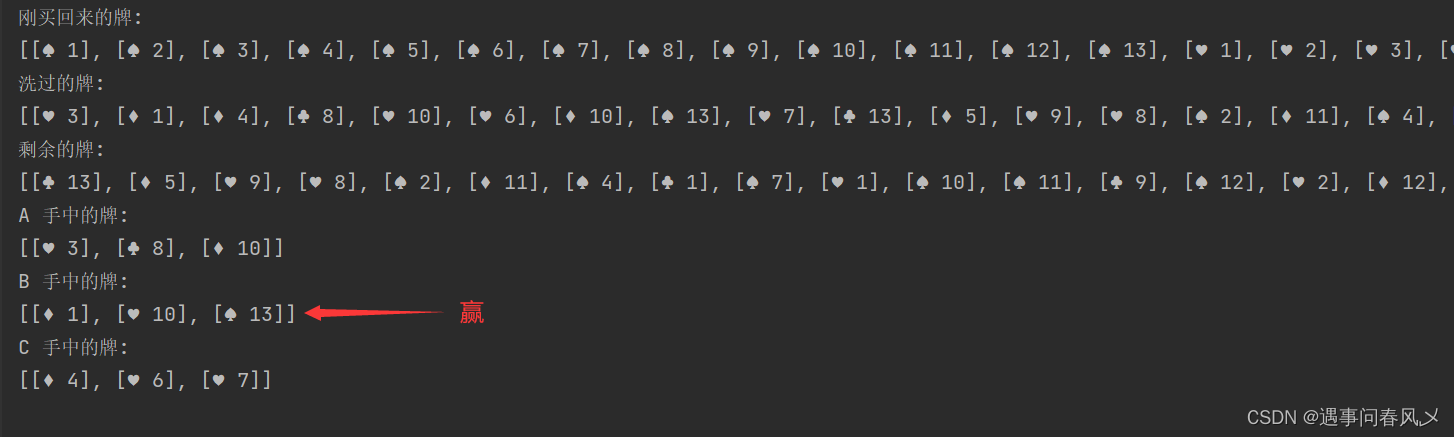
效果展示:
完整代码:
import java.util.ArrayList;
import java.util.List;
import java.util.Random;class Card {public int rank; // 牌面值public String suit; // 花色@Overridepublic String toString() {return String.format("[%s %d]", suit, rank);}
}public class CardDemo {public static final String[] SUITS = {"♠", "♥", "♣", "♦"};// 买一副牌private static List<Card> buyDeck() {List<Card> deck = new ArrayList<>(52);for (int i = 0; i < 4; i++) {for (int j = 1; j <= 13; j++) {String suit = SUITS[i];int rank = j;Card card = new Card();card.rank = rank;card.suit = suit;deck.add(card);}}return deck;}private static void swap(List<Card> deck, int i, int j) {Card t = deck.get(i);deck.set(i, deck.get(j));deck.set(j, t);}private static void shuffle(List<Card> deck) {Random random = new Random();for (int i = deck.size() - 1; i > 0; i--) {int r = random.nextInt(i);swap(deck, i, r);}}public static void main(String[] args) {List<Card> deck = buyDeck();System.out.println("刚买回来的牌:");System.out.println(deck);shuffle(deck);System.out.println("洗过的牌:");System.out.println(deck);
// 三个人,每个人轮流抓 5 张牌List<List<Card>> hands = new ArrayList<>();hands.add(new ArrayList<>());hands.add(new ArrayList<>());hands.add(new ArrayList<>());for (int i = 0; i < 3; i++) {for (int j = 0; j < 3; j++) {hands.get(j).add(deck.remove(0));}}System.out.println("剩余的牌:");System.out.println(deck);System.out.println("A 手中的牌:");System.out.println(hands.get(0));System.out.println("B 手中的牌:");System.out.println(hands.get(1));System.out.println("C 手中的牌:");System.out.println(hands.get(2));}
}总结
关于《【数据结构】 ArrayList简介与实战》就讲解到这儿,感谢大家的支持,欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下!