我们一般使用 PuTTY 等 SSH 客户端来远程管理 Linux 服务器。但是,一般的密码方式登录,容易有密码被暴力破解的问题。所以,一般我们会将 SSH 的端口设置为默认的 22 以外的端口,或者禁用 root 账户登录。其实,有一个更好的办法来保证安全,而且让你可以放心地用 root 账户从远程登录——那就是通过密钥方式登录。
密钥形式登录的原理是:利用密钥生成器制作一对密钥——一只公钥和一只私钥。将公钥添加到服务器的某个账户上,然后在客户端利用私钥即可完成认证并登录。这样一来,没有私钥,任何人都无法通过 SSH 暴力破解你的密码来远程登录到系统。此外,如果将公钥复制到其他账户甚至主机,利用私钥也可以登录。
下面来讲解如何在 Linux 服务器上制作密钥对,将公钥添加给账户,设置 SSH,最后通过客户端登录。
1、制作密匙对
[root@brace ~] # ssh-keygen <== 建立密钥对
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): <== 按 Enter
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase): <== 输入密钥锁码,或直接按 Enter 留空
Enter same passphrase again: <== 再输入一遍密钥锁码
Your identification has been saved in /root/.ssh/id_rsa. <== 私钥
Your public key has been saved in /root/.ssh/id_rsa.pub. <== 公钥
The key fingerprint is:
SHA256:vfMD691TW5bF9tZHZYPsuQMWAoswwcz377glhXrov8w root@brace
The key's randomart image is:
+---[RSA 2048]----+
| ++. .. . . |
| +o.. .. . o .o|
| .... . o .oo|
| ... o o =|
| .S.o . .o=|
| o .... o .O|
| o oo.oo .++|
| . +.o..+.... |
| ..Eo.. o... |
+----[SHA256]-----+
密钥锁码在使用私钥时必须输入,这样就可以保护私钥不被盗用。当然,也可以留空,实现无密码登录。
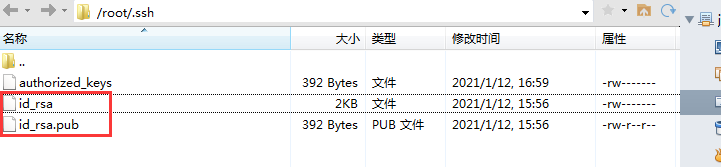
现在,在 root 用户的家目录中生成了一个 .ssh 的隐藏目录,内含两个密钥文件。id_rsa 为私钥,id_rsa.pub 为公钥。
2. 在服务器上安装公钥
键入以下命令,在服务器上安装公钥:
[root@brace ~]# cd .ssh
[root@brace .ssh]# ls
id_rsa id_rsa.pub
[root@brace .ssh]# cat id_rsa.pub >> authorized_keys
如此便完成了公钥的安装。为了确保连接成功,请保证以下文件权限正确:
[root@brace .ssh]# chmod 600 authorized_keys
[root@brace .ssh]# chmod 700 ~/.ssh
3. 设置 SSH,打开密钥登录功能
编辑 /etc/ssh/sshd_config 文件,进行如下设置:
RSAAuthentication yes
PubkeyAuthentication yes另外,请留意 root 用户能否通过 SSH 登录:
PermitRootLogin yes当你完成全部设置,并以密钥方式登录成功后,再禁用密码登录:
PasswordAuthentication no最后,重启 SSH 服务。再次重启服务器或者连接SSH将使用密钥登录。
4. 将私钥下载到桌面
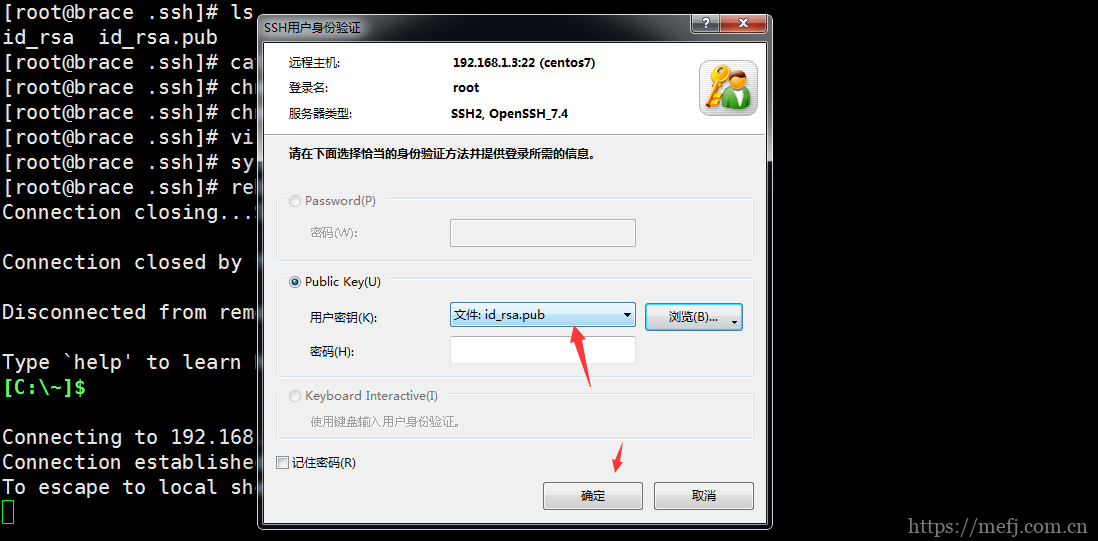
使用xshell直接打开密钥登录
PuTTY需要转换为 PuTTY 能使用的格式
使用 WinSCP、SFTP 等工具将私钥文件 id_rsa 下载到客户端机器上。然后打开 PuTTYGen,单击 Actions 中的 Load 按钮,载入你刚才下载到的私钥文件。如果你刚才设置了密钥锁码,这时则需要输入。
载入成功后,PuTTYGen 会显示密钥相关的信息。在 Key comment 中键入对密钥的说明信息,然后单击 Save private key 按钮即可将私钥文件存放为 PuTTY 能使用的格式。
今后,当你使用 PuTTY 登录时,可以在左侧的 Connection -> SSH -> Auth 中的 Private key file for authentication: 处选择你的私钥文件,然后即可登录了,过程中只需输入密钥锁码即可。