最便宜 双网站建设建立网站多少钱
day48
- 121. 买卖股票的最佳时机
- 1.确定dp数组(dp table)以及下标的含义
- 2.确定递推公式
- 3.dp数组如何初始化
- 4.确定遍历顺序
- 5.举例推导dp数组
- 122.买卖股票的最佳时机II
121. 买卖股票的最佳时机
题目链接
解题思路:
动规五部曲分析如下:
1.确定dp数组(dp table)以及下标的含义
dp[i][0] 表示第i天持有股票所得最多现金 ,这里可能有同学疑惑,本题中只能买卖一次,持有股票之后哪还有现金呢?
其实一开始现金是0,那么加入第i天买入股票现金就是 -prices[i], 这是一个负数。
dp[i][1] 表示第i天不持有股票所得最多现金
注意这里说的是“持有”,“持有”不代表就是当天“买入”!也有可能是昨天就买入了,今天保持持有的状态
2.确定递推公式
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:
dp[i - 1][0] - 第i天买入股票,所得现金就是买入今天的股票后所得现金即:
-prices[i]
那么dp[i][0]应该选所得现金最大的,所以dp[i][0] = max(dp[i - 1][0], -prices[i]);
如果第i天不持有股票即dp[i][1], 也可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:
dp[i - 1][1] - 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:
prices[i] + dp[i - 1][0]
同样dp[i][1]取最大的,dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
3.dp数组如何初始化
由递推公式 dp[i][0] = max(dp[i - 1][0], -prices[i]); 和 dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);可以看出
其基础都是要从dp[0][0]和dp[0][1]推导出来。
那么dp[0][0]表示第0天持有股票,此时的持有股票就一定是买入股票了,因为不可能有前一天推出来,所以dp[0][0] -= prices[0];
dp[0][1]表示第0天不持有股票,不持有股票那么现金就是0,所以dp[0][1] = 0;
4.确定遍历顺序
从递推公式可以看出dp[i]都是由dp[i - 1]推导出来的,那么一定是从前向后遍历。
5.举例推导dp数组
以示例1,输入:[7,1,5,3,6,4]为例,dp数组状态如下:
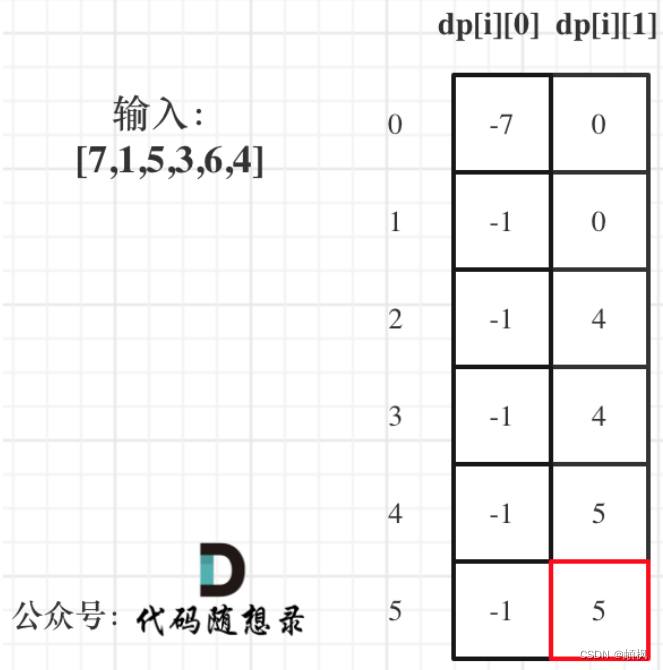
dp[5][1]就是最终结果。
为什么不是dp[5][0]呢?
因为本题中不持有股票状态所得金钱一定比持有股票状态得到的多!
以上分析完毕,C++代码如下:
class Solution {
public:int maxProfit(vector<int>& prices) {int len = prices.size();if (len == 0) return 0;vector<vector<int>> dp(len, vector<int>(2));dp[0][0] -= prices[0];dp[0][1] = 0;for (int i = 1; i < len; i++) {dp[i][0] = max(dp[i - 1][0], -prices[i]);dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);}return dp[len - 1][1];}
};
122.买卖股票的最佳时机II
题目链接
解题思路:
本题和121. 买卖股票的最佳时机 的唯一区别是本题股票可以买卖多次了(注意只有一只股票,所以再次购买前要出售掉之前的股票)
代码如下:
class Solution {
public:int maxProfit(vector<int>& prices) {int len = prices.size();vector<vector<int>> dp(len, vector<int>(2, 0));dp[0][0] -= prices[0];dp[0][1] = 0;for (int i = 1; i < len; i++) {dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]); // 注意这里是和121. 买卖股票的最佳时机唯一不同的地方。dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);}return dp[len - 1][1];}
};大家可以本题和121. 买卖股票的最佳时机的代码几乎一样,唯一的区别在:
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
这正是因为本题的股票可以买卖多次! 所以买入股票的时候,可能会有之前买卖的利润即:dp[i - 1][1],所以dp[i - 1][1] - prices[i]。