如何制作网站app上海做推
一、概述
PBR(Policy-Based Routing,策略路由):PBR使得网络设备不仅能够基于报文的目的IP地址进行数据转发,更能基于其他元素进行数据转发,例如源IP地址、源MAC地址、目的MAC地址、源端口号、目的端口号、VLAN-ID等等。
PBR的分类
- 接口PBR
- 接口PBR只对转发的报文起作用,对本地始发的报文无效。
- 接口PBR调用在接口下,对接口的入方向报文生效。缺省情况下,设备按照路由表的下一跳进行报文转发,如果配置了接口PBR,则设备按照接口PBR指定的下一跳进行转发。
- 本地PBR
- 本地PBR对本地始发的流量生效,如:本地始发的ICMP报文。
- 本地PBR在系统视图调用
实验目的
- 熟悉PBR的应用场景
- 掌握PBR的配置方法
想要华为数通配套实验拓扑和配置笔记的朋友们点赞+关注,评论区留下邮箱发给你!
二、实验配置
实验目的
- 熟悉PBR的应用场景
- 掌握PBR的配置方法
2. 实验拓扑
PBR实验拓扑如图所示:

3. 实验步骤
(1) IP地址的配置
R1的配置
<Huawei>system-view
Enter system view, return user view with Ctrl+Z.
[Huawei]undo info-center enable
[Huawei]sysname R1
[R1]interface g0/0/0
[R1-GigabitEthernet0/0/0]ip address 13.1.1.1 24
[R1-GigabitEthernet0/0/0]quit
[R1]interface g0/0/1
[R1-GigabitEthernet0/0/1]ip address 14.1.1.1 24
[R1-GigabitEthernet0/0/1]quit
R2的配置
<Huawei>system-view
Enter system view, return user view with Ctrl+Z.
[Huawei]sysname R2
[R2]undo info-center enable
Info: Information center is disabled.
[R2]interface g0/0/0
[R2-GigabitEthernet0/0/0]ip address 24.1.1.2 24
[R2-GigabitEthernet0/0/0]quit
[R2]int
[R2]interface g0/0/1
[R2-GigabitEthernet0/0/1]ip address 23.1.1.2 24
[R2-GigabitEthernet0/0/1]quit
R3的配置
<Huawei>system-view
Enter system view, return user view with Ctrl+Z.
[Huawei]undo info-center enable
Info: Information center is disabled.
[Huawei]sysname R3
[R3]interface g0/0/0
[R3-GigabitEthernet0/0/0]ip address 23.1.1.3 24
[R3-GigabitEthernet0/0/0]quit
[R3]interface g0/0/1
[R3-GigabitEthernet0/0/1]ip address 13.1.1.3 24
[R3-GigabitEthernet0/0/1]quit
[R3]interface g0/0/2
[R3-GigabitEthernet0/0/2]ip address 10.1.1.3 24
[R3-GigabitEthernet0/0/2]quit
R4的配置
<Huawei>system-view
Enter system view, return user view with Ctrl+Z.
[Huawei]undo info-center enable
[Huawei]sysname R4
[R4]interface g0/0/0
[R4-GigabitEthernet0/0/0]ip address 14.1.1.4 24
[R4-GigabitEthernet0/0/0]quit
[R4]interface g0/0/1
[R4-GigabitEthernet0/0/1]ip address 24.1.1.4 24
[R4-GigabitEthernet0/0/1]quit
[R4]interface s0/0/1
[R4-Serial0/0/1]ip address 45.1.1.4 24
[R4-Serial0/0/1]quit
[R4]interface LoopBack 0
[R4-LoopBack0]ip ad
[R4-LoopBack0]ip address 4.4.4.4 24
[R4-LoopBack0]quit
R5的配置
[R5]interface s0/0/0
[R5-Serial0/0/0]ip adderss 45.1.1.5 24
[R5-Serial0/0/0]quit
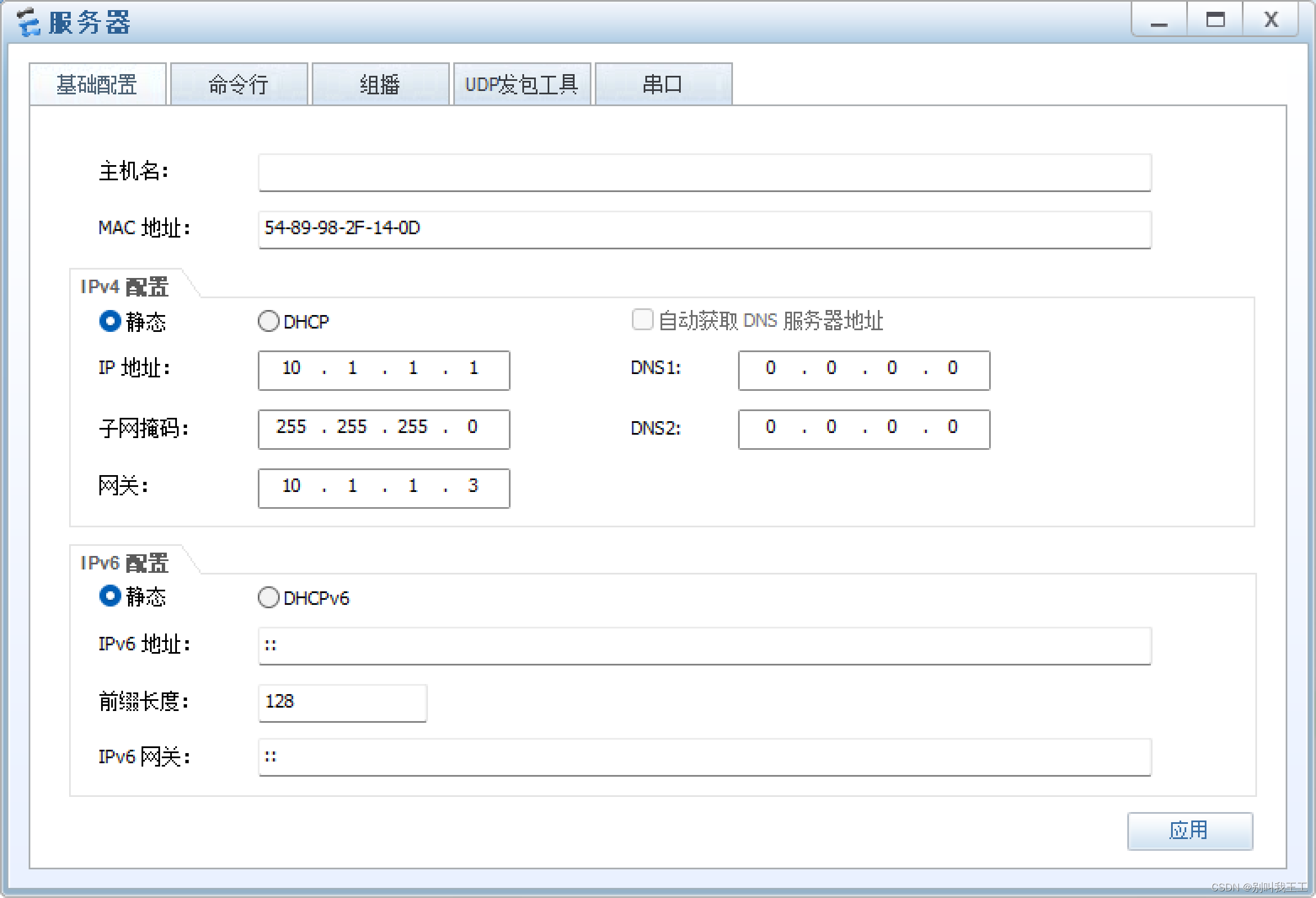
服务器的配置
服务器的配置如图所示:
想要华为数通配套实验拓扑和配置笔记的朋友们点赞+关注,评论区留下邮箱发给你!
(2) 配置OSPF
R1的配置
[R1]ospf router-id 1.1.1.1
[R1-ospf-1]area 0
[R1-ospf-1-area-0.0.0.0]network 13.1.1.0 0.0.0.255
[R1-ospf-1-area-0.0.0.0]network 14.1.1.0 0.0.0.255
[R1-ospf-1-area-0.0.0.0]quit
R2的配置
[R2]ospf router-id 2.2.2.2
[R2-ospf-1]area 0
[R2-ospf-1-area-0.0.0.0]network 24.1.1.0 0.0.0.255
[R2-ospf-1-area-0.0.0.0]network 23.1.1.0 0.0.0.255
[R2-ospf-1-area-0.0.0.0]quit
R3的配置
[R3]ospf router-id 3.3.3.3
[R3-ospf-1]area 0
[R3-ospf-1-area-0.0.0.0]network 13.1.1.0 0.0.0.255
[R3-ospf-1-area-0.0.0.0]network 23.1.1.0 0.0.0.255
[R3-ospf-1-area-0.0.0.0]network 10.1.1.0 0.0.0.255
[R3-ospf-1-area-0.0.0.0]quit
R4的配置
[R4]ospf router-id 4.4.4.4
[R4-ospf-1]area 0
[R4-ospf-1-area-0.0.0.0]network 14.1.1.0 0.0.0.255
[R4-ospf-1-area-0.0.0.0]network 24.1.1.0 0.0.0.255
[R4-ospf-1-area-0.0.0.0]network 45.1.1.0 0.0.0.255
[R4-ospf-1-area-0.0.0.0]network 4.4.4.0 0.0.0.255
[R4-ospf-1-area-0.0.0.0]quit
R5的配置
[R5]ip route-static 0.0.0.0 0.0.0.0 45.1.1.4
(3)修改R4的g0/0/0的COST
[R4]interface g0/0/0
[R4-GigabitEthernet0/0/0]ospf cost 40
[R4-GigabitEthernet0/0/0]quit
(4)在R5上tracert 10.1.1.1
[R5]tracert 10.1.1.1
traceroute to 10.1.1.1(10.1.1.1), max hops: 30 ,packet length: 40,press CTRL_C to break
1 45.1.1.4 40 ms 70 ms 30 ms
2 24.1.1.2 120 ms 110 ms 100 ms
3 23.1.1.3 150 ms 140 ms 130 ms
4 10.1.1.1 150 ms 180 ms 150 ms
通过以上输出 可以看到R5访问服务器的路径为R5-R4-R2-R3-服务器
(5)设置PBR让R5访问服务器走R5-R4-R1-R3-服务器
第一步:匹配流量
[R4]acl 3000
[R4-acl-adv-3000]rule 10 permit ip source 45.1.1.0 0.0.0.255 destination 10.1.1.1 0
[R4-acl-adv-3000]quit
第二步:创建PBR
[R4]policy-based-route hcip permit node 10
[R4-policy-based-route-hcip-10]if-match acl 3000
[R4-policy-based-route-hcip-10]apply ip-address next-hop 14.1.1.1
[R4-policy-based-route-hcip-10]quit
第三步:接口下调用PBR
[R4]interface s0/0/1
[R4-Serial0/0/1]ip policy-based-route hcip
[R4-Serial0/0/1]quit
4. 实验调试
(1)在R5上tracert10.1.1.1
<R5>tracert 10.1.1.1
traceroute to 10.1.1.1(10.1.1.1), max hops: 30 ,packet length: 40,press CTRL_C to break
1 45.1.1.4 60 ms 60 ms 60 ms
2 14.1.1.1 130 ms 80 ms 90 ms
3 13.1.1.3 130 ms 100 ms 160 ms
4 10.1.1.1 160 ms 180 ms 160 ms
通过以上输出可以看到R5访问服务器的路径改成了R5-R4-R1-R3-服务器
(2)查看R4的环回口4.4.4.4访问服务器
<R4>tracert 10.1.1.1
traceroute to 10.1.1.1(10.1.1.1), max hops: 30 ,packet length: 40,press CTRL_C to break
1 24.1.1.2 60 ms 60 ms 60 ms
2 23.1.1.3 80 ms 100 ms 90 ms
3 10.1.1.1 110 ms 90 ms 80 ms
通过以上输出可以看到R4的本地流量还是走R4-R2-服务器
【技术要点】
PBR在接口下应用,只对通过的流量起作用,对本地产生的流量不起作用
(3)让R4产生的流量也走PBR
第一步:抓取流量
[R4]acl 3000
[R4-acl-adv-3000]rule 20 permit ip source 4.4.4.0 0.0.0.255 destination 10.1.1.1 0
第二步:全局调用
[R4]ip local policy-based-route hcip
(4)查看
[R4]tracert -a 4.4.4.4 10.1.1.1
traceroute to 10.1.1.1(10.1.1.1), max hops: 30 ,packet length: 40,press CTRL_C to break
1 14.1.1.1 70 ms 30 ms 30 ms
2 13.1.1.3 120 ms 110 ms 130 ms
3 10.1.1.1 120 ms 140 ms 160 ms
通过以上输出可以看到,R4本地的流量走的是R4-R3-服务器。