贵阳市住房城乡建设局八大员网站dw免费网站模板
1、任务与中断的优先级
(1)相同优先级任务轮流执行。
(2)高优先级任务打断低优先级任务。
(3)中断可以打断所有优先级的任务。
2、任务优先级
(1)优先级的取值范围是:0~(configMAX_PRIORITIES – 1),数值越大优先级越高。
(2)FreeRTOS会确保最高优先级的、可运行的任务,马上就能执行;对于相同优先级的、可运行的任务,轮流执行。
(3)FreeRTOS的调度器可以使用2种方法来快速找出优先级最高的、可以运行的任务。使用不同的方法时,configMAX_PRIORITIES 的取值有所不同。
(4)通用方法
- 使用C函数实现,对所有的架构都是同样的代码。
- 对configMAX_PRIORITIES的取值没有限制。但是configMAX_PRIORITIES的取值还是尽量小,因为取值越大越浪费内存,也浪费时间。
- configUSE_PORT_OPTIMISED_TASK_SELECTION被定义为0、或者未定义时,使用此方法。
(4)架构相关的优化的方法
- 使用这种方法时,configMAX_PRIORITIES的取值不能超过32。
- 架构相关的汇编指令,可以从一个32位的数里快速地找出为1的最高位。使用这些指令,可以快速找出优先级最高的、可以运行的任务。
- configUSE_PORT_OPTIMISED_TASK_SELECTION被定义为1时,使用此方法。
3、Tick
(1)对于同优先级的任务,它们“轮流”执行。怎么轮流?你执行一会,我执行一会。"一会"怎么定义?人有心跳,心跳间隔基本恒定。FreeRTOS中也有心跳,它使用定时器产生固定间隔的中断。这叫Tick、滴答,比如每10ms发生一次时钟中断。
(2)举例:
- 假设t1、t2、t3发生时钟中断
- 两次中断之间的时间被称为时间片(time slice、tick period)
- 时间片的长度由configTICK_RATE_HZ 决定,假设configTICK_RATE_HZ为100,那么时间片长度就是10ms。(1/100hHZ = 10ms)

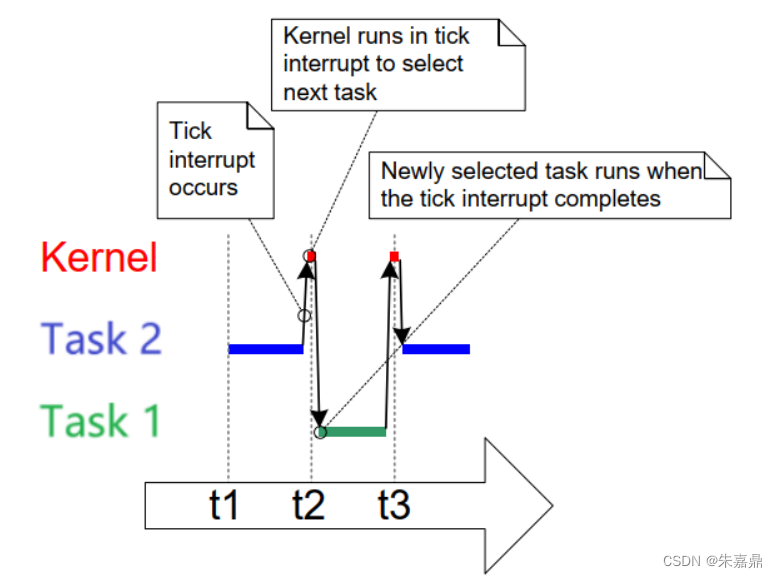
(3)相同优先级的任务切换
- 任务2从t1执行到t2。
- 在t2发生tick中断,进入tick中断处理函数:选择下一个要运行的任务;执行完中断处理函数后,切换到新的任务:任务1。
- 任务1从t2执行到t3。
4、使用Tick衡量时间
(1)使用方法
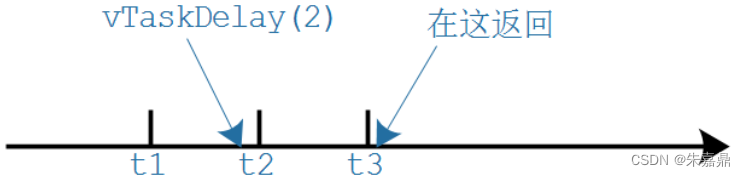
// 等待2个Tick,假设configTICK_RATE_HZ=100, Tick周期时10ms, 等待20ms
vTaskDelay(2); // 还可以使用pdMS_TO_TICKS宏把ms转换为tick,等待100ms
vTaskDelay(pdMS_TO_TICKS(100)); (2)注意,基于Tick实现的延时并不精确,比如 vTaskDelay(2) 的本意是延迟2个Tick周期,有可能经过1个Tick多一点就返回了。(产生两个Tick中断就返回了)
(3)使用vTaskDelay函数时,建议以ms为单位,使用pdMS_TO_TICKS把时间转换为Tick。这样的代码就与configTICK_RATE_HZ无关,即使配置项configTICK_RATE_HZ改变了,我们也不用去修
改代码。