男通网站哪个好用网站设计主题有哪些
DBA AI助手:以自然语言与Oracle数据库互动
- 0. 引言
- 1. AI赋能Oracle DBA的优势
- 2. AI如何与Oracle数据库交互
- 3. 自然语言查询的一些示例
- 4. 未来展望
0. 引言
传统的Oracle数据库管理 (DBA) 依赖于人工操作,包括编写复杂的SQL语句、分析性能指标和解决各种数据库问题。
这不仅需要大量的专业知识和经验,而且工作效率低下,容易出现人为错误。
近年来,人工智能 (AI) 技术的快速发展为DBA带来了新的机遇。通过自然语言处理 (NLP) 技术,AI可以理解和生成人类语言,并将其应用于数据库管理的各个方面。
1. AI赋能Oracle DBA的优势
- 提高工作效率: AI可以自动执行许多繁琐的手动操作,例如:
- 编写SQL语句
- 分析性能指标
- 诊断和解决数据库问题
- 降低运维成本: AI可以帮助DBA减少工作量,降低人力成本。
- 提高数据库性能: AI可以持续分析数据库运行状况,并自动进行优化调整。
- 提升数据库安全性: AI可以帮助DBA识别潜在的安全威胁,并及时采取措施进行防护。
2. AI如何与Oracle数据库交互
AI可以通过以下方式与Oracle数据库交互:
- 自然语言查询: DBA可以使用自然语言向AI提问,例如:
- “数据库的整体运行状况如何?”
- “哪个表空间的空间使用率最高?”
- “如何解决ORA-00600错误?”
- 智能诊断和修复: AI可以自动分析数据库运行状况,并识别潜在的问题。AI还可以根据问题的原因,自动生成修复建议或执行修复操作。
- 自动化运维: AI可以自动执行日常的数据库运维工作,例如:
- 备份和恢复数据库
- 进行性能优化
- 应用安全补丁
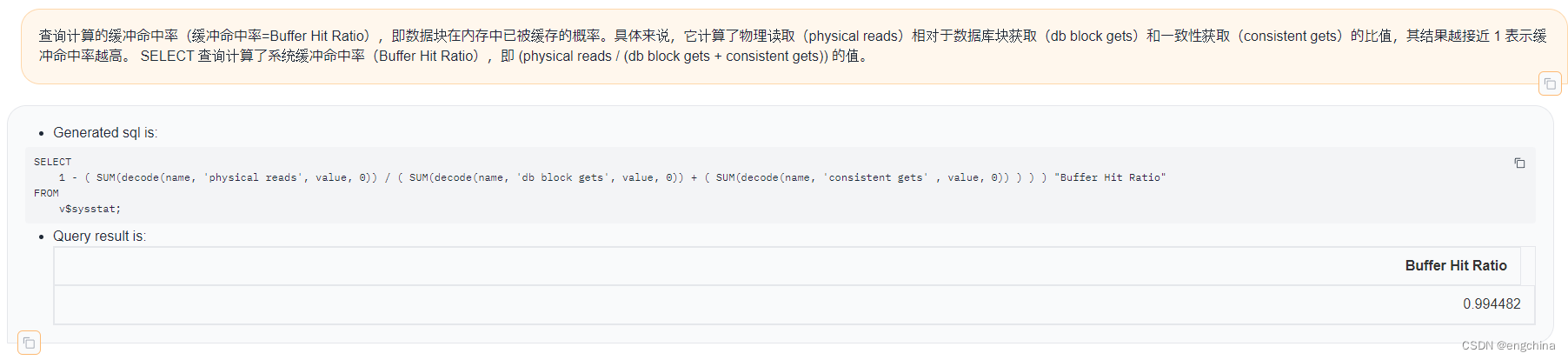
3. 自然语言查询的一些示例
下面展示一些使用自然语言查询Oracle数据的示例,



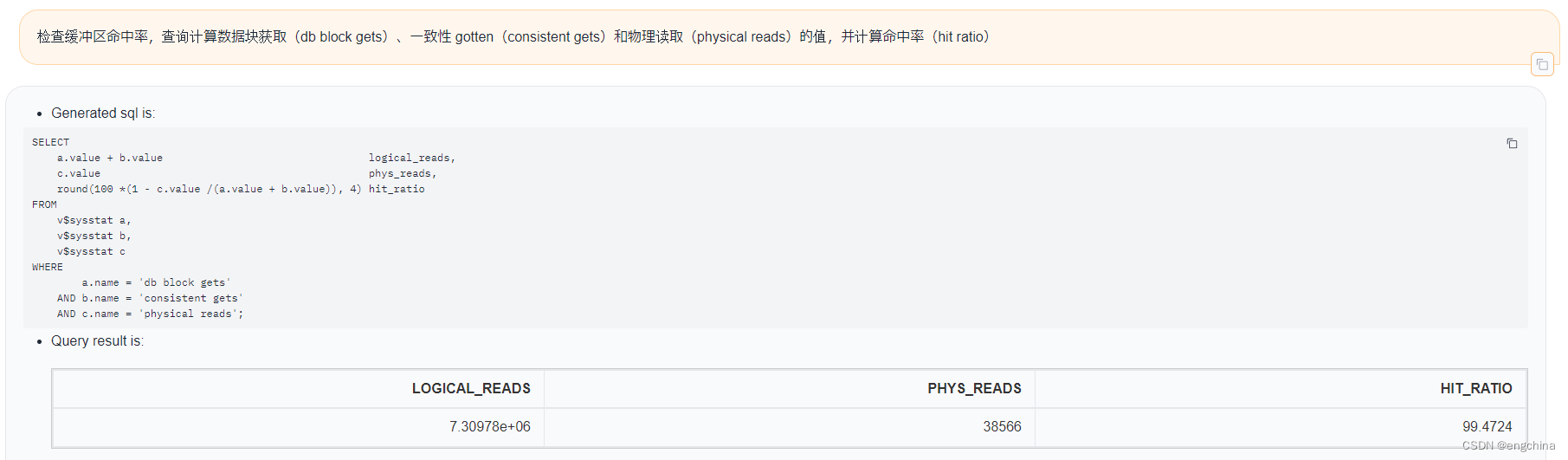

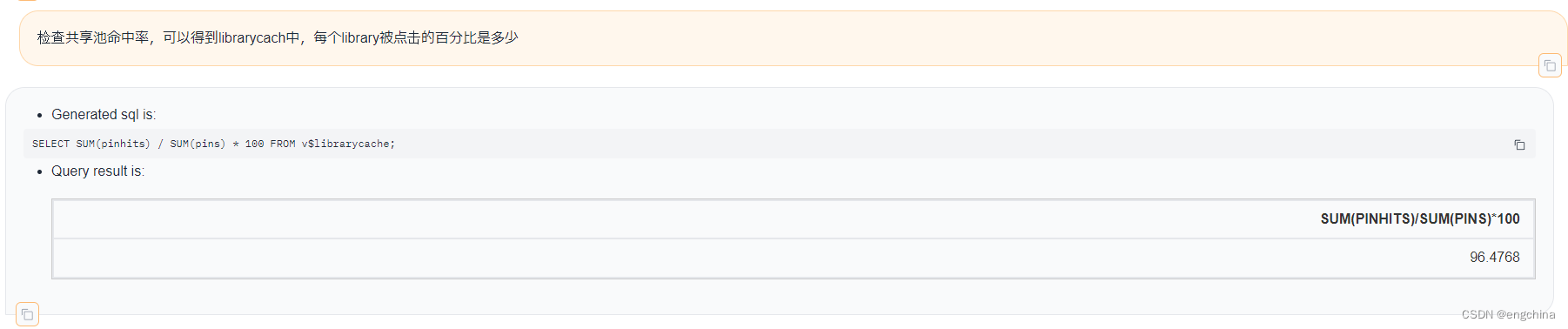
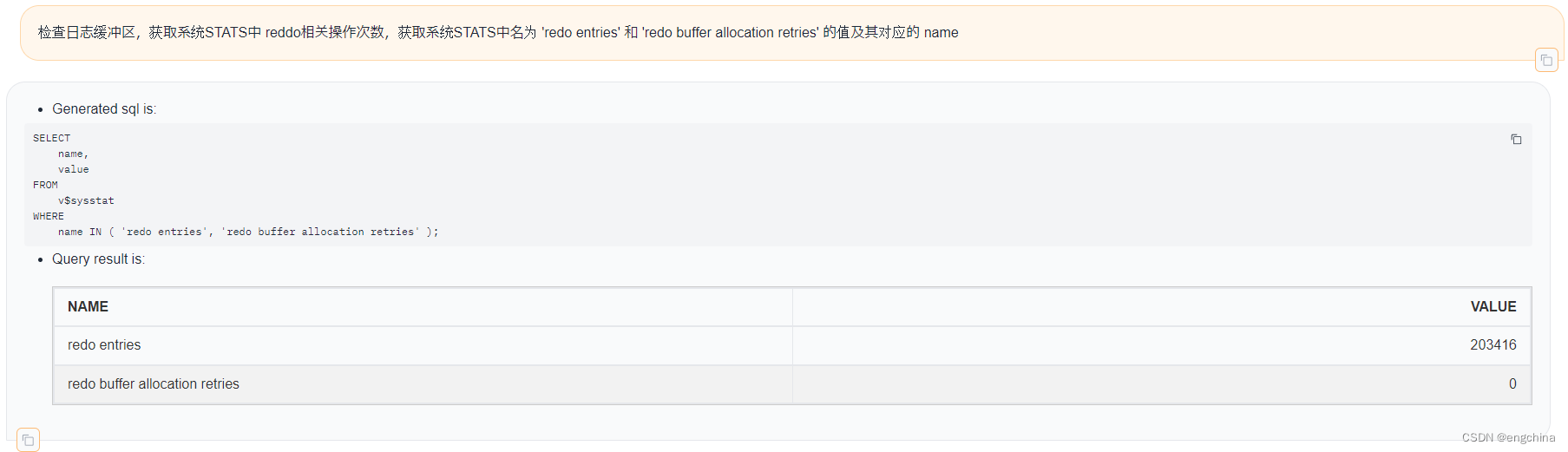
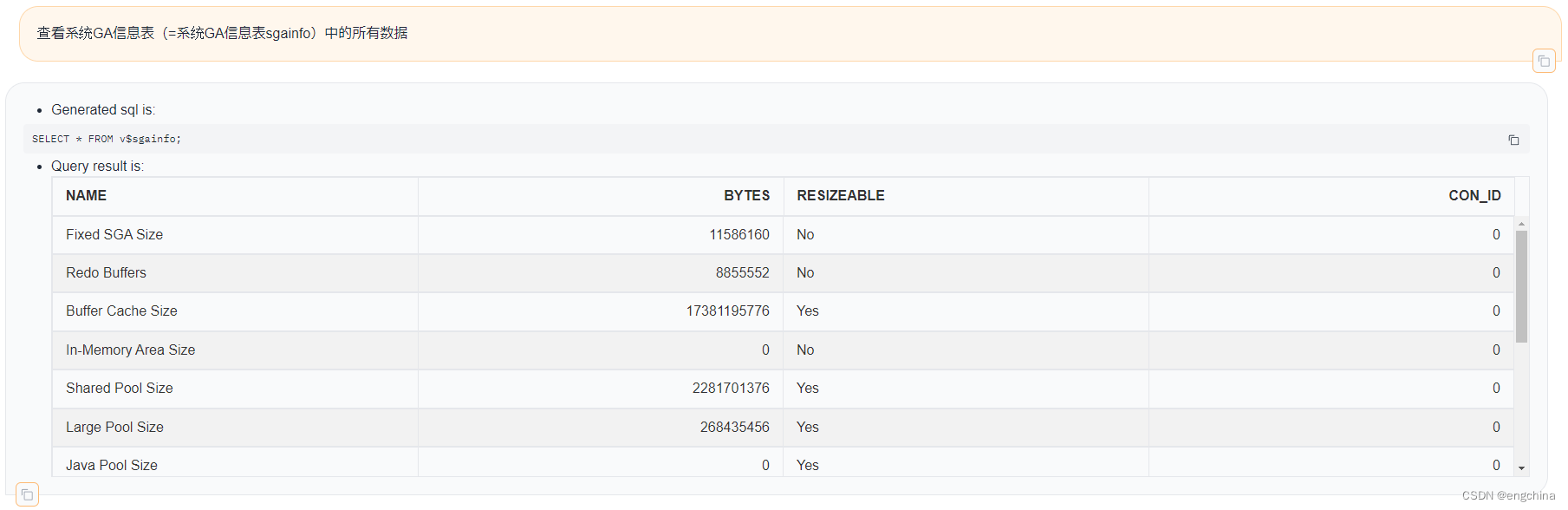
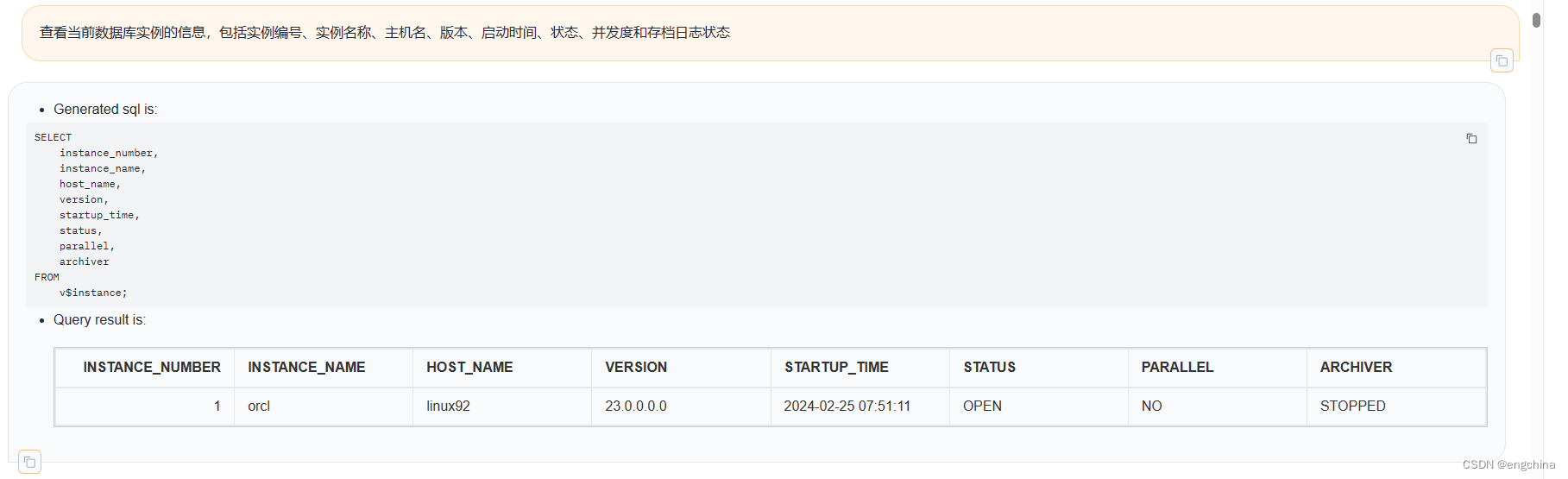


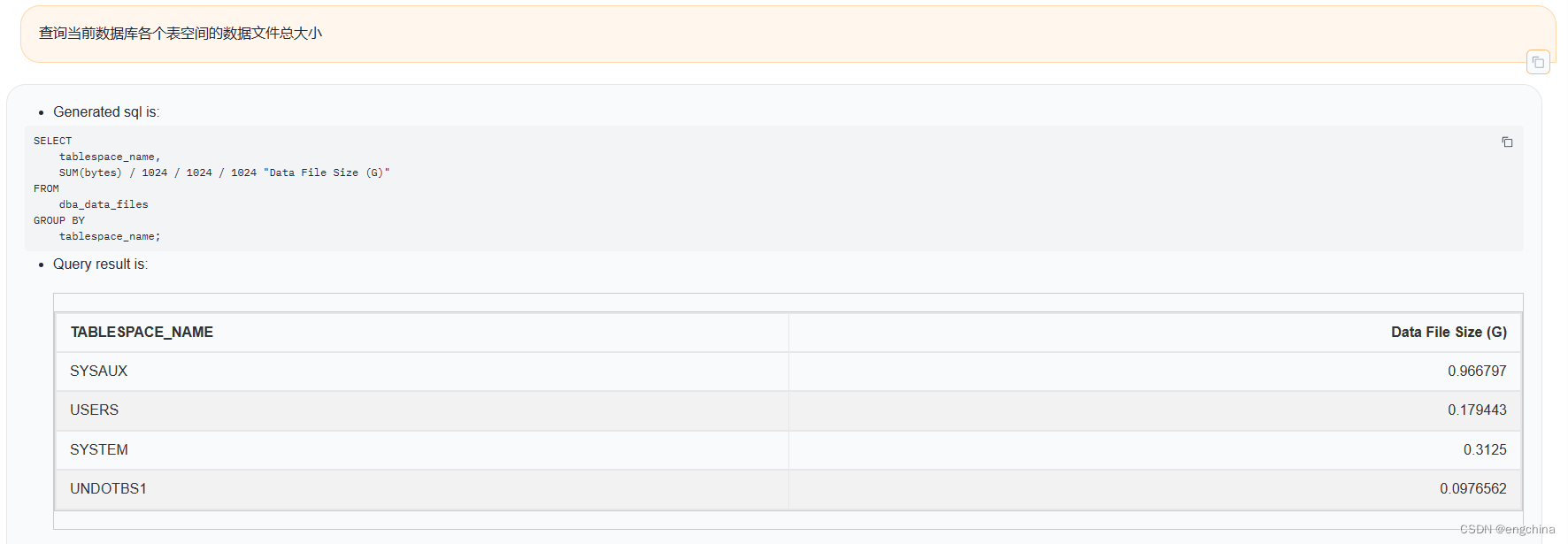
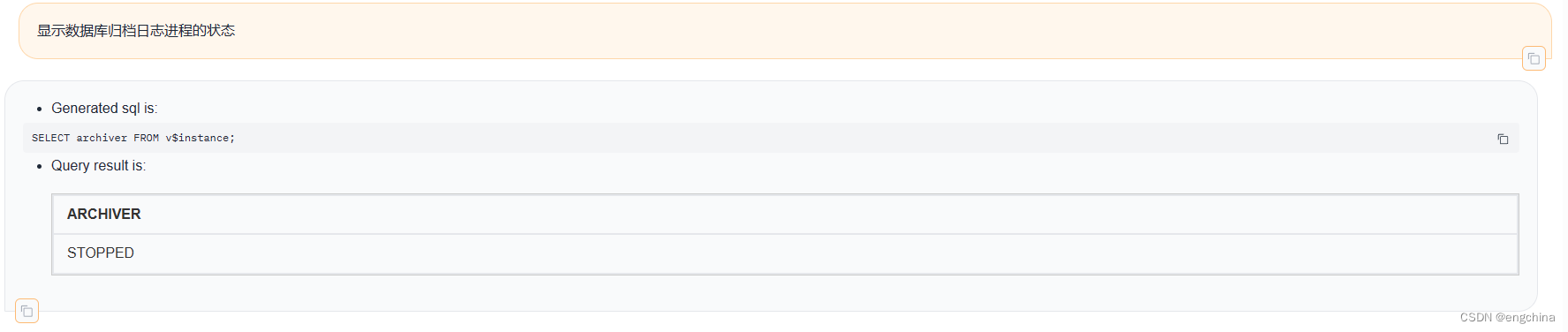
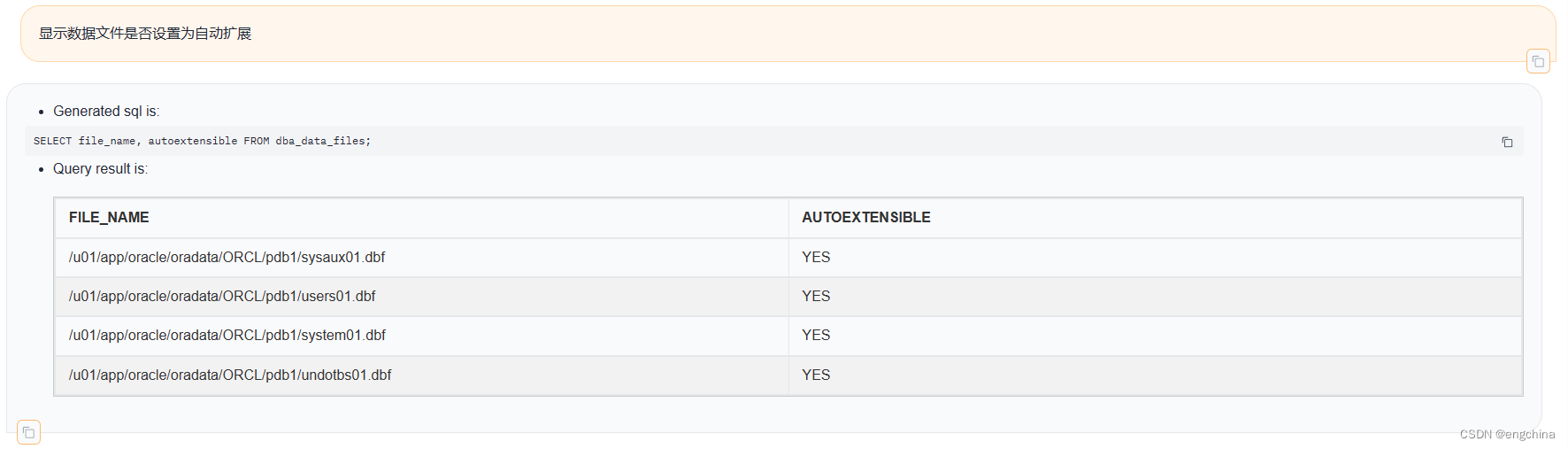
4. 未来展望
随着AI技术的不断发展,AI在Oracle数据库管理领域的应用将会更加深入和广泛。AI将帮助DBA更高效地管理数据库,并提升数据库的性能和安全性。
以下是AI在Oracle数据库管理领域的一些潜在应用场景:
- 数据库容量规划: AI可以预测未来的数据库容量需求,并自动进行资源扩容。
- 数据库性能调优: AI可以持续分析数据库性能指标,并自动进行调优。
- 数据库安全态势分析: AI可以分析数据库安全日志,并识别潜在的安全威胁。
- 数据库故障自愈: AI可以自动诊断和修复数据库故障。
完结!