网站建设+用ftp上传文件电商网站 编程语言
国标GB28181视频平台EasyGBS是基于国标GB/T28181协议的行业内安防视频流媒体能力平台,可实现的视频功能包括:实时监控直播、录像、检索与回看、语音对讲、云存储、告警、平台级联等功能。国标GB28181视频监控平台部署简单、可拓展性强,支持将接入的视频流进行全终端、全平台分发,分发的视频流包括RTSP、RTMP、FLV、HLS、WebRTC等格式。

有用户反馈,EasyGBS国标GB28181平台在播放时,出现了无法播放的情况,并且抓包查看返回ICMP,请求我们协助排查。今天我们来分享一下排查与解决步骤。
1)通过抓包分析我们发现了问题,首先第一次invite请求是在16:41:06秒,可以看到请求的rtp端口是58422;

2)在sip传输的时间里,5s已经是一个很久的概念了,音视频国标平台EasyGBS在5s内若没有收到设备下发的RTP流,就判定为此次播放失败,并且主动发一个Bye结束此次invite交互;
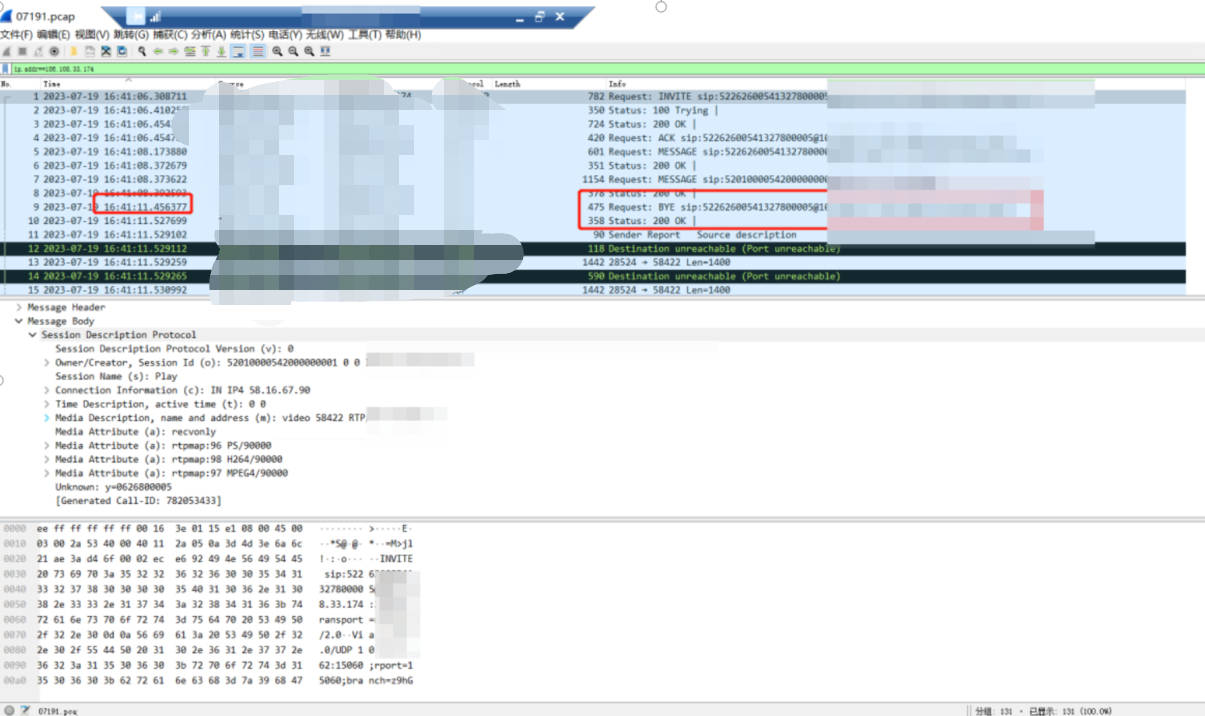
3)通过抓包的报文可以看到,设备并非没有发流,是因为设备发流的时长延时大概是6s左右,所以我们可以看到设备的确有发过来rtp流,并且是向58422的rtp流端口发送的;
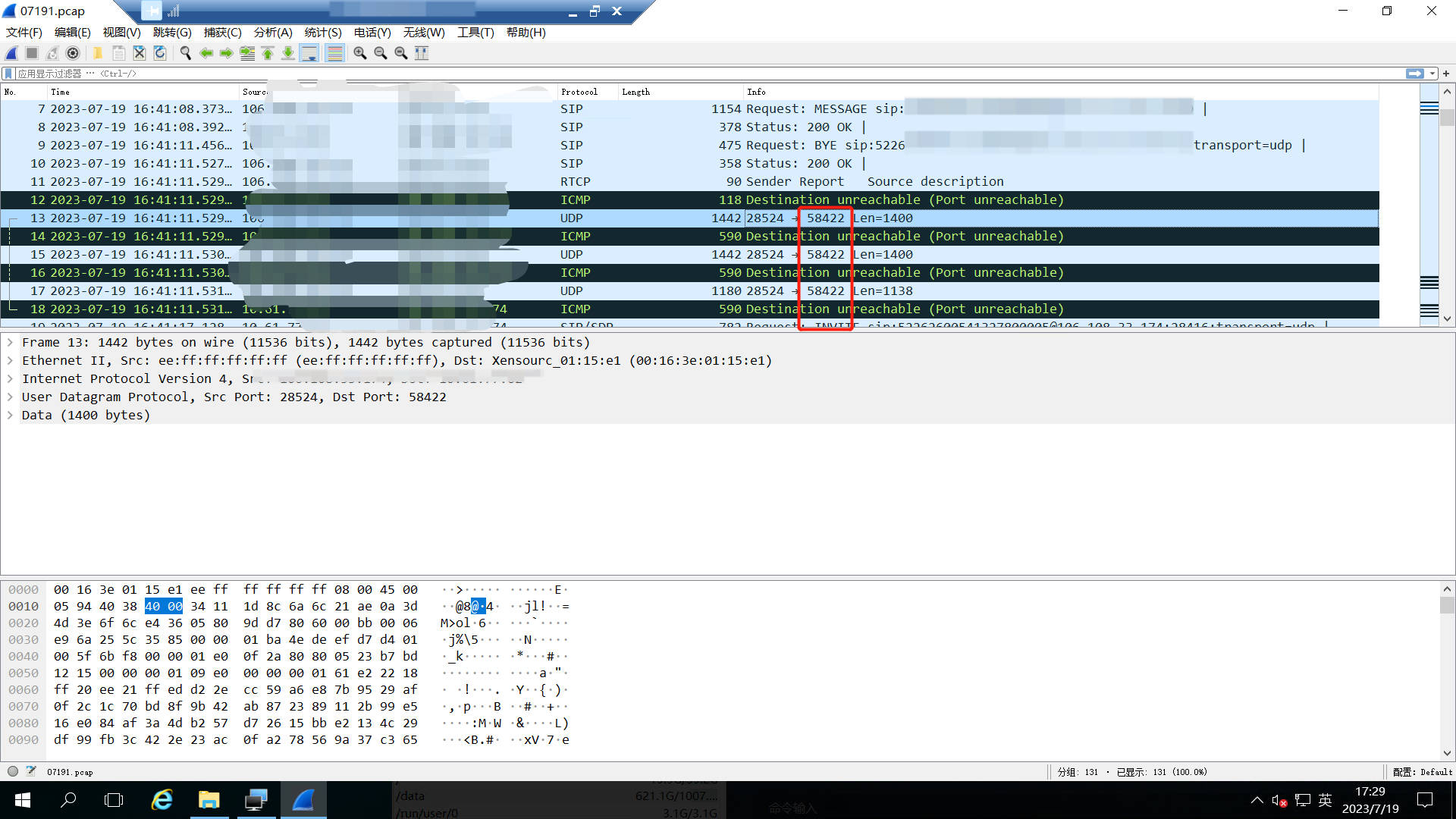
4)系统判断58422端口无效,因为国标GB28181视频平台EasyGBS已经对58422端口解除了绑定,所以没有服务占用58422这个端口,这样就导致服务器认为此端口没有使用并向设备回复了ICMP;
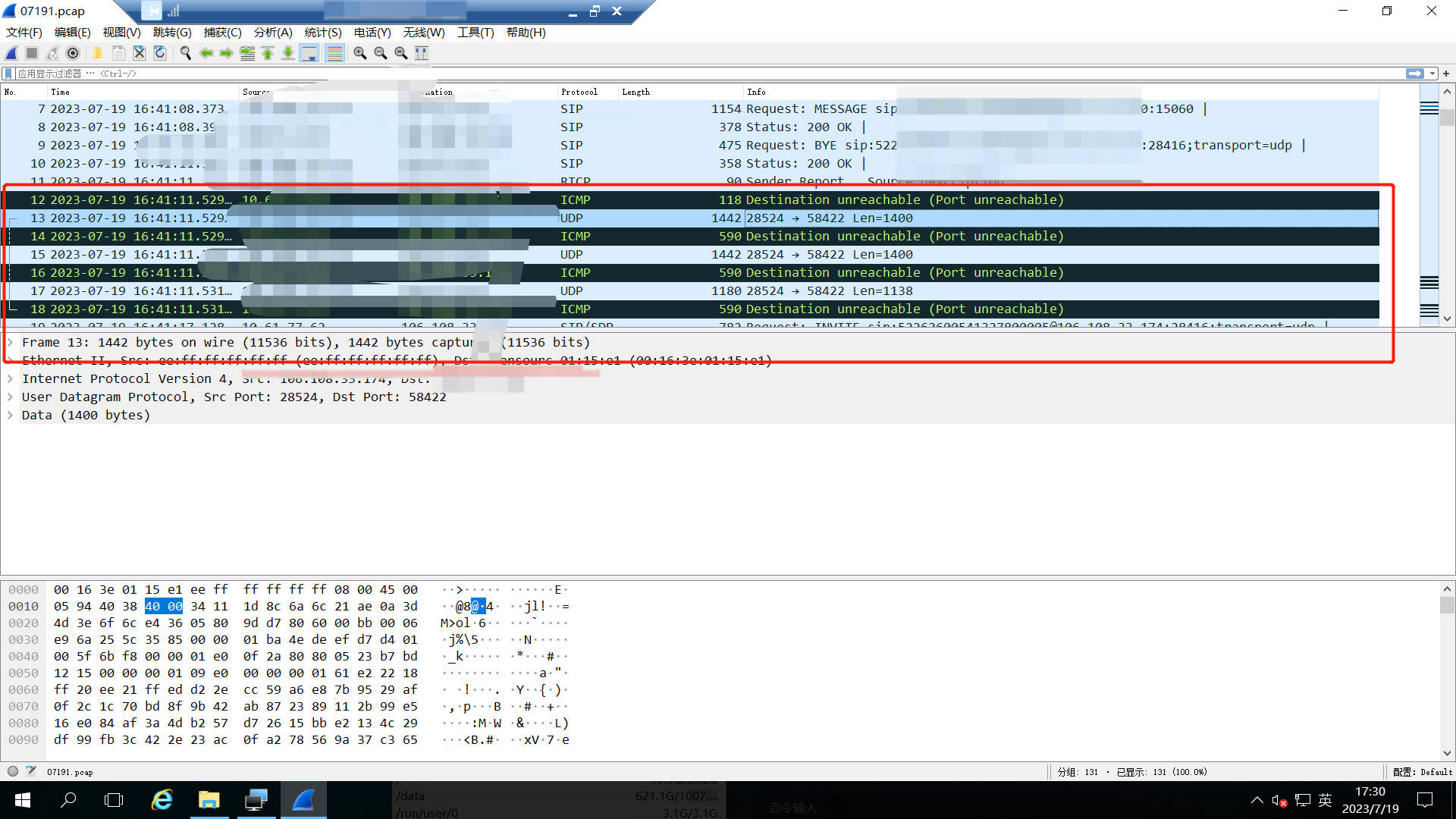
5)经过判断国标GB28181安防监控平台EasyGBS和现场设备正常的sip交互延时是很低的,所以应该和网络传输无关,建议用户在设备端进行排查。经过用户的排查,现场设备升级后,上述问题得到了解决。
视频流媒体安防监控国标GB28181平台EasyGBS视频能力丰富,部署灵活,既能作为业务平台使用,也能作为安防监控视频能力层被业务管理平台调用。国标GB28181视频EasyGBS平台可提供流媒体接入、处理、转发等服务,支持内网、公网的安防视频监控设备通过国标GB/T28181协议进行视频监控直播。