网站域名注册价格旅游网站建设ppt模板下载
用免费GPU线上跑SD项目实践
DataWhale组织了一个线上白嫖GPU跑chatGLM与SD的项目活动,我很感兴趣就参加啦。之前就对chatGLM有所耳闻,是去年清华联合发布的开源大语言模型,可以用来打造个人知识库什么的,一直没有尝试。而SD我前两天刚跟着B站秋叶大佬和Nenly大佬的视频学习过,但是生成某些图片显存吃紧,想线上部署尝试一下。
参考:DataWhale 学习手册链接
1 学习简介
本文以趋动云平台为例,详细介绍下如何通过平台提供的在线开发环境,直接在云端编写、运行代码,并使用GPU资源进行加速。本教程将学习云算力资源的使用方式,并给出了两个AI项目实践:
- 用免费GPU创建属于自己的聊天GPT
- 用免费GPU部署自己的stable-diffusion
平台注册:
- 注册即送168元算力金
- Datawhale专属注册链接:https://growthdata.virtaicloud.com/t/SA
适用人群:
- 新手开发者、快速原型设计者;
- 需要协作和分享的团队;
- 对大模型部署感兴趣的人;
- 深度学习入门学习者;
- 对使用GPU资源有需求的人。
优势:
无需进行本地环境配置,简单易用,便于分享和协作。
组织方:Datawhale x 趋动云
3 云端部署StableDiffusion模型
3.1 项目配置
-
创建项目
在趋动云用户工作台中,点击 快速创建 ,选择 创建项目,创建新项目。
-
镜像配置
选择 趋动云小助手 的
AUTOMATIC1111/stable-diffusion-webui镜像。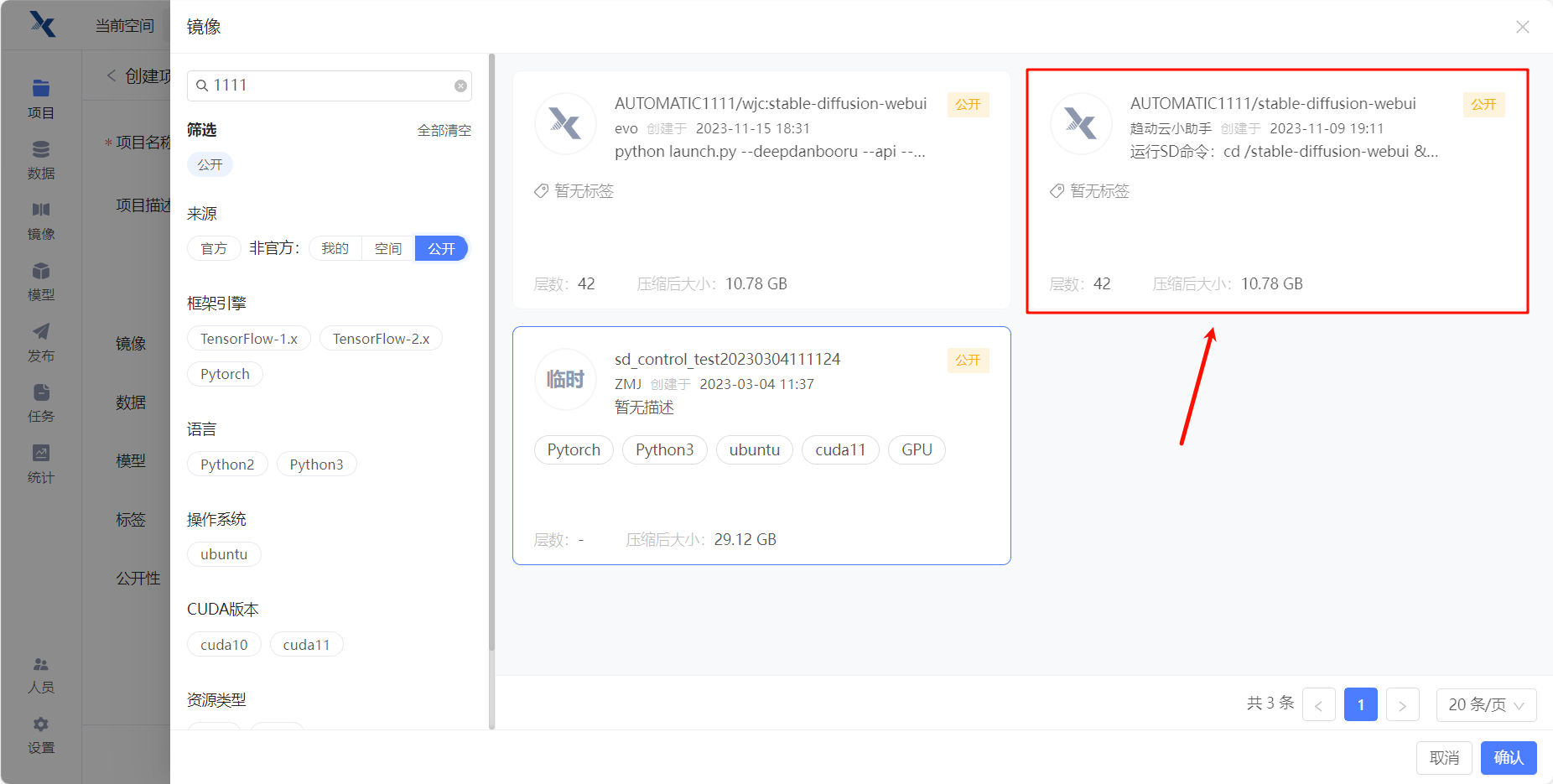
-
数据集配置
在 公开 数据集中,选择
stable-diffusion-models数据集。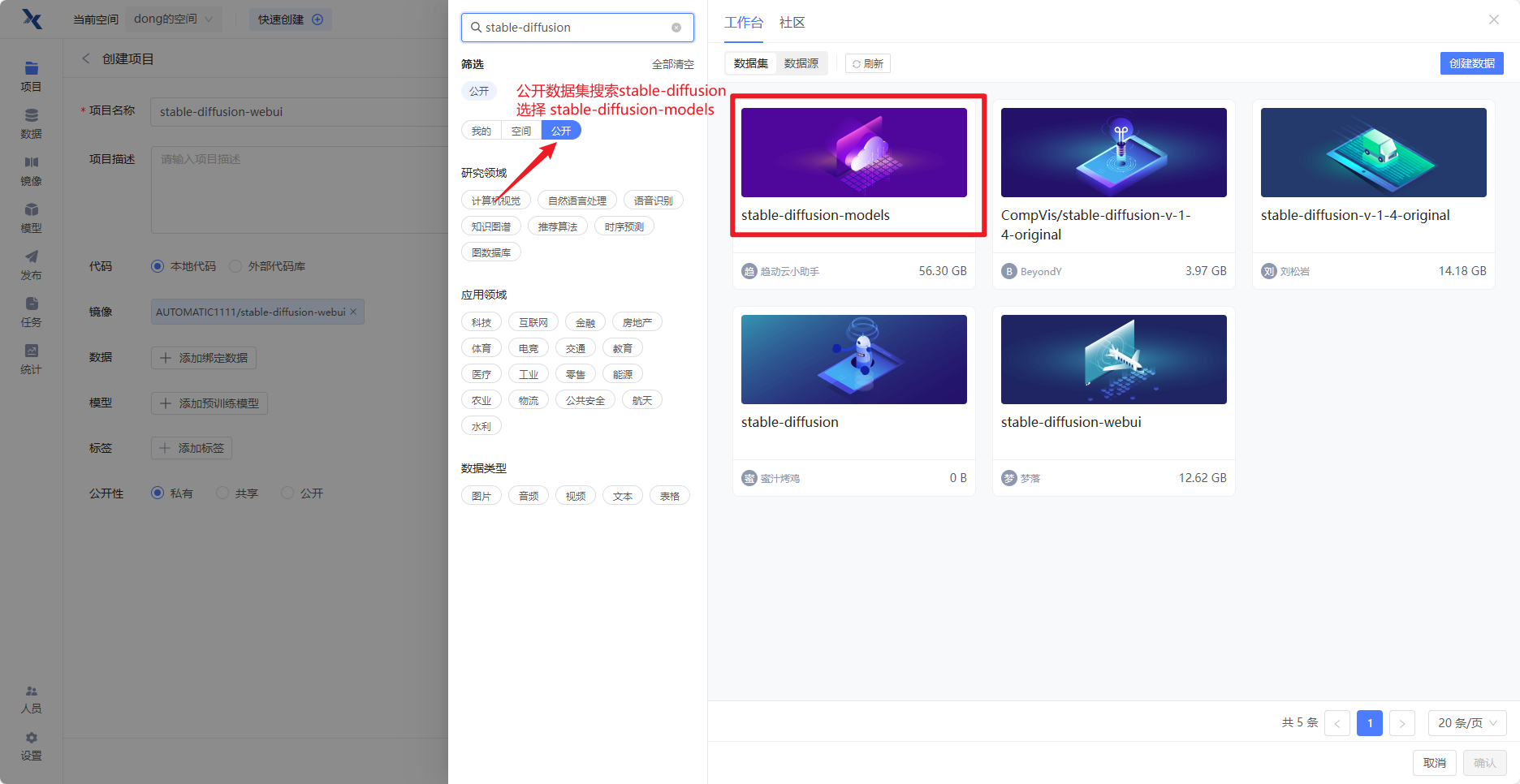
配置完成后,点击创建,要求上传代码时,选择 暂不上传 。
-
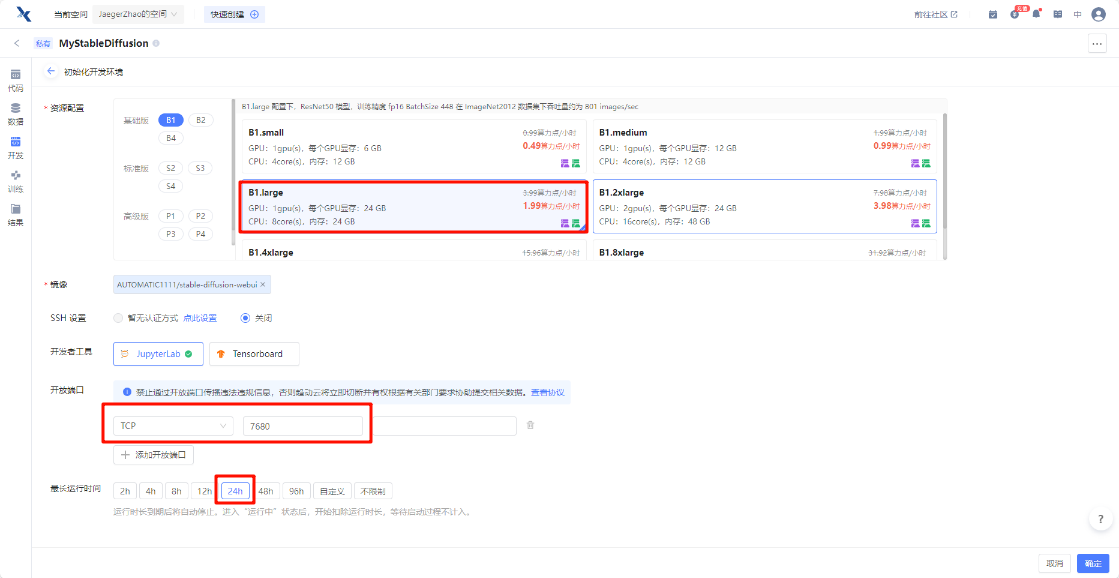
初始化开发环境
找到最右侧 “开发”-> “初始化开发环境实例”,我这里没按教程配置,因为SD生图需要较大显存,我选择了拥有24G显存的 B1.large,其他按教程一样,并设置了24h的最长运行时间。
3.2 环境配置
因为数据集代码有所变化,所以教程中有些步骤可以省略,以下为具体步骤。
-
解压代码及模型
tar xf /gemini/data-1/stable-diffusion-webui.tar -C /gemini/code/ -
拷贝frpc内网穿透文件
chmod +x /root/miniconda3/lib/python3.10/sitepackages/gradio/frpc_linux_amd64_v0.2 -
拷贝模型文件到项目目录下
cp /gemini/data-1/v1-5-pruned-emaonly.safetensors /gemini/code/stable-diffusion-webui/ -
更新系统httpx依赖
pip install httpx==0.24.1 -
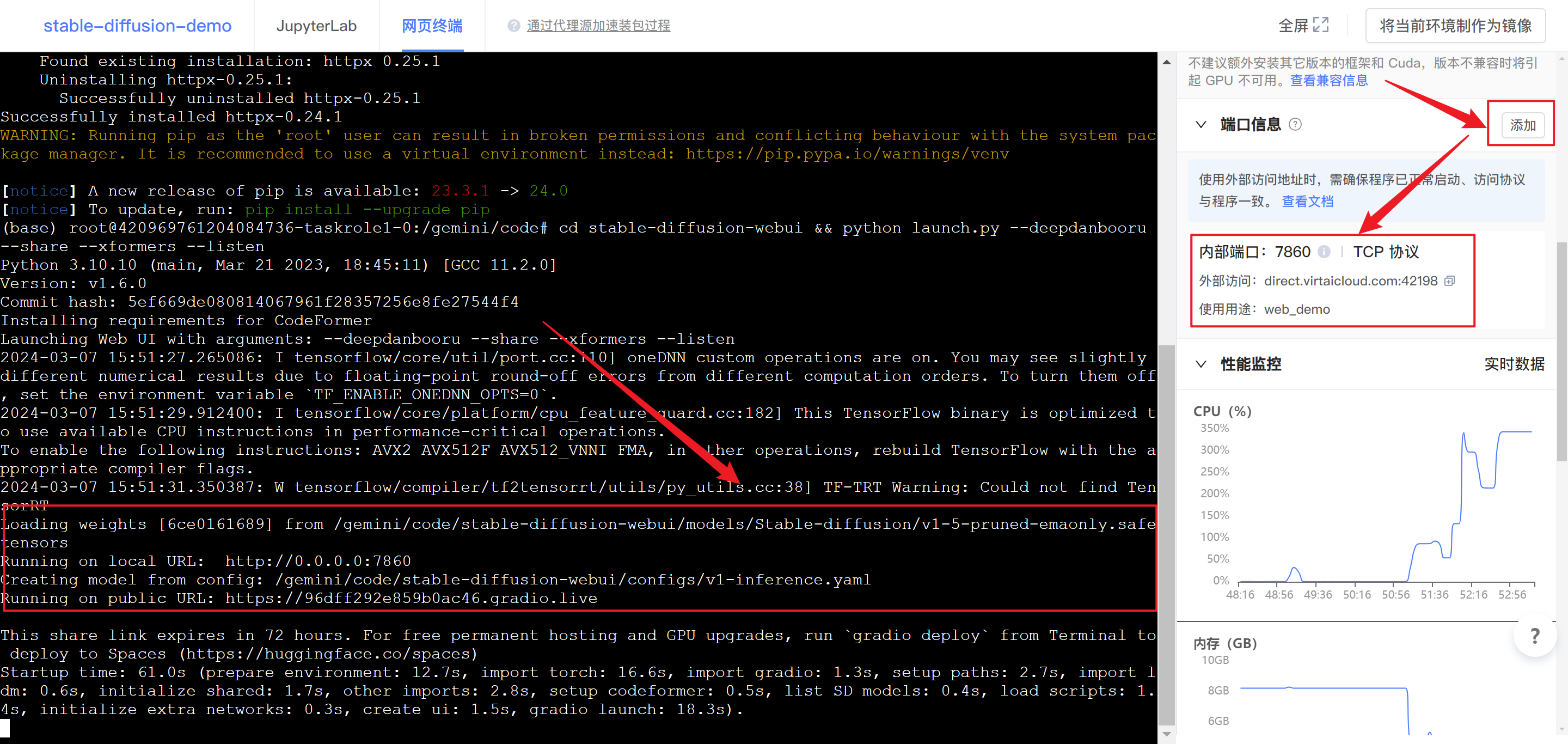
运行项目
cd /gemini/code/stable-diffusion-webui && python launch.py --deepdanbooru --share --xformers --listen运行项目后,点击右侧添加,创建 外部访问链接 。
-
访问StableDiffusion的WebUI
复制外部访问链接,在浏览器粘贴并访问,就成功打开WebUI界面啦。
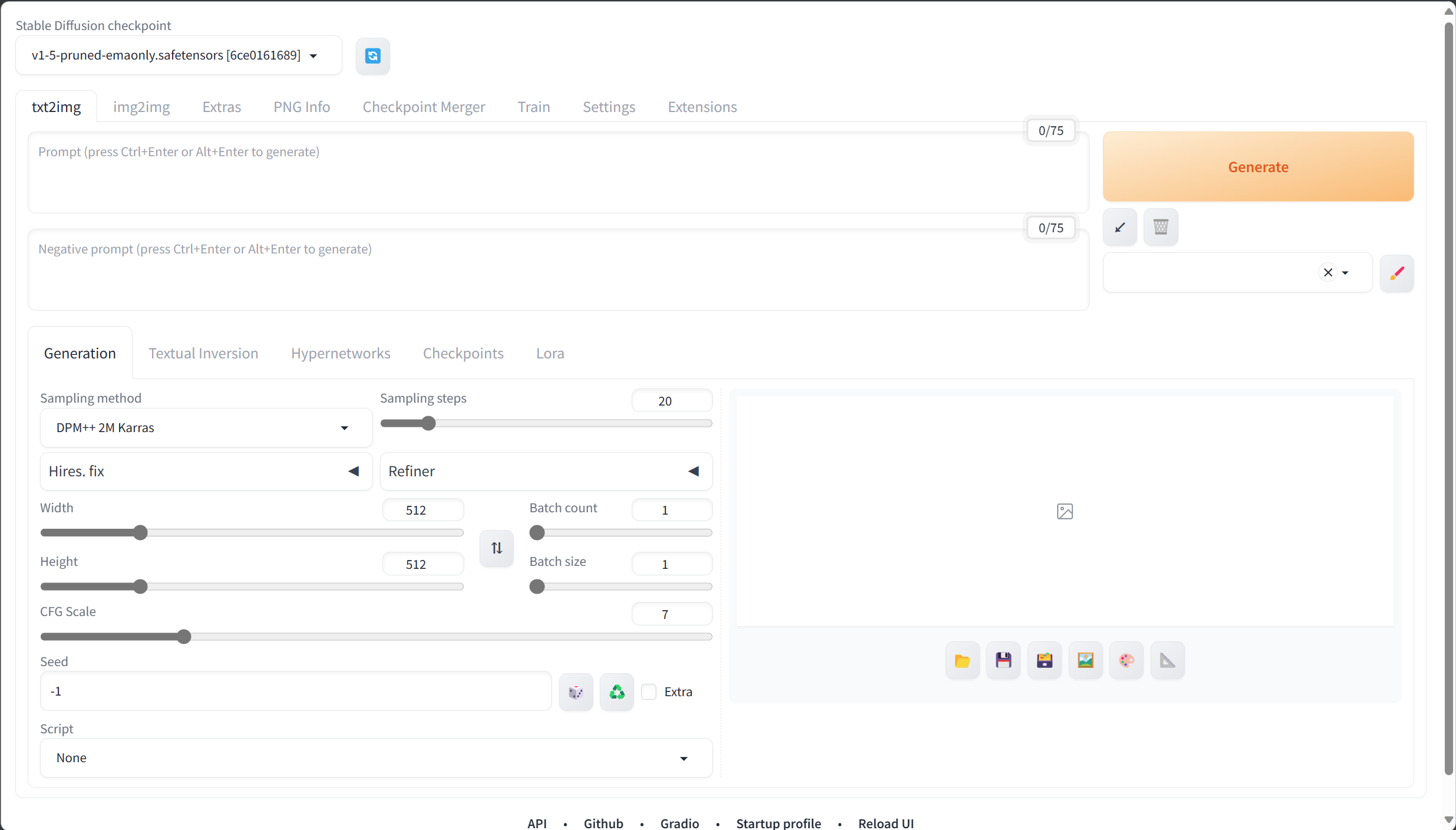
-
生成镜像
点击右上角 将当前环境制作为镜像,点击 智能生成,在
AUTOMATIC1111/stable-diffusion-webui基础镜像下生成,点击 构建,完成对镜像的构建。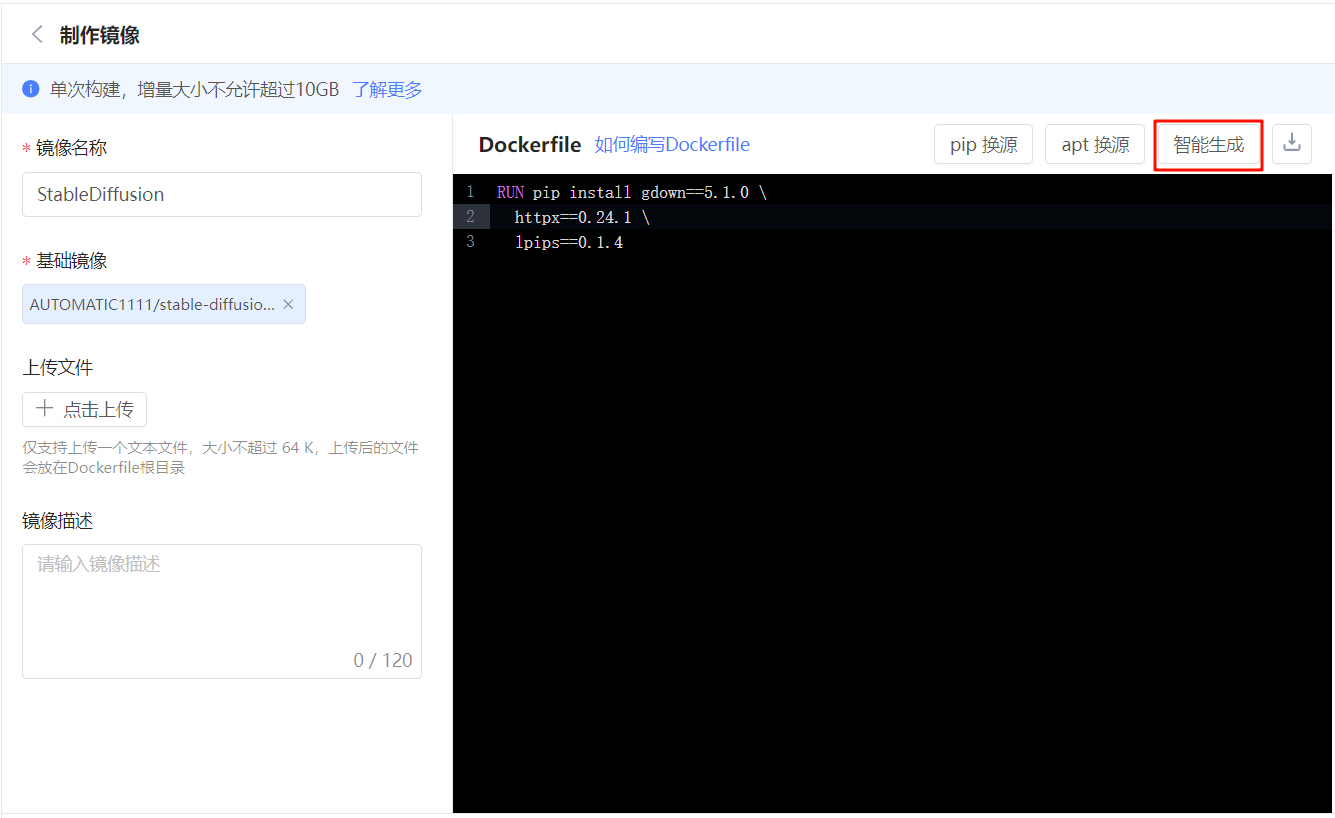
之后安装上一章的步骤,将镜像配置到你的项目里就好啦。
配置好环境后,再次访问,在终端输入以下指令直接运行 WebUI 。
cd /gemini/code/stable-diffusion-webui && python launch.py --deepdanbooru --share --xformers --listen
3.3 StableDiffusion 使用
-
生成第一张美图
部署好了当然是要生成一张图,我选择生成一张猫猫图,结果如下。
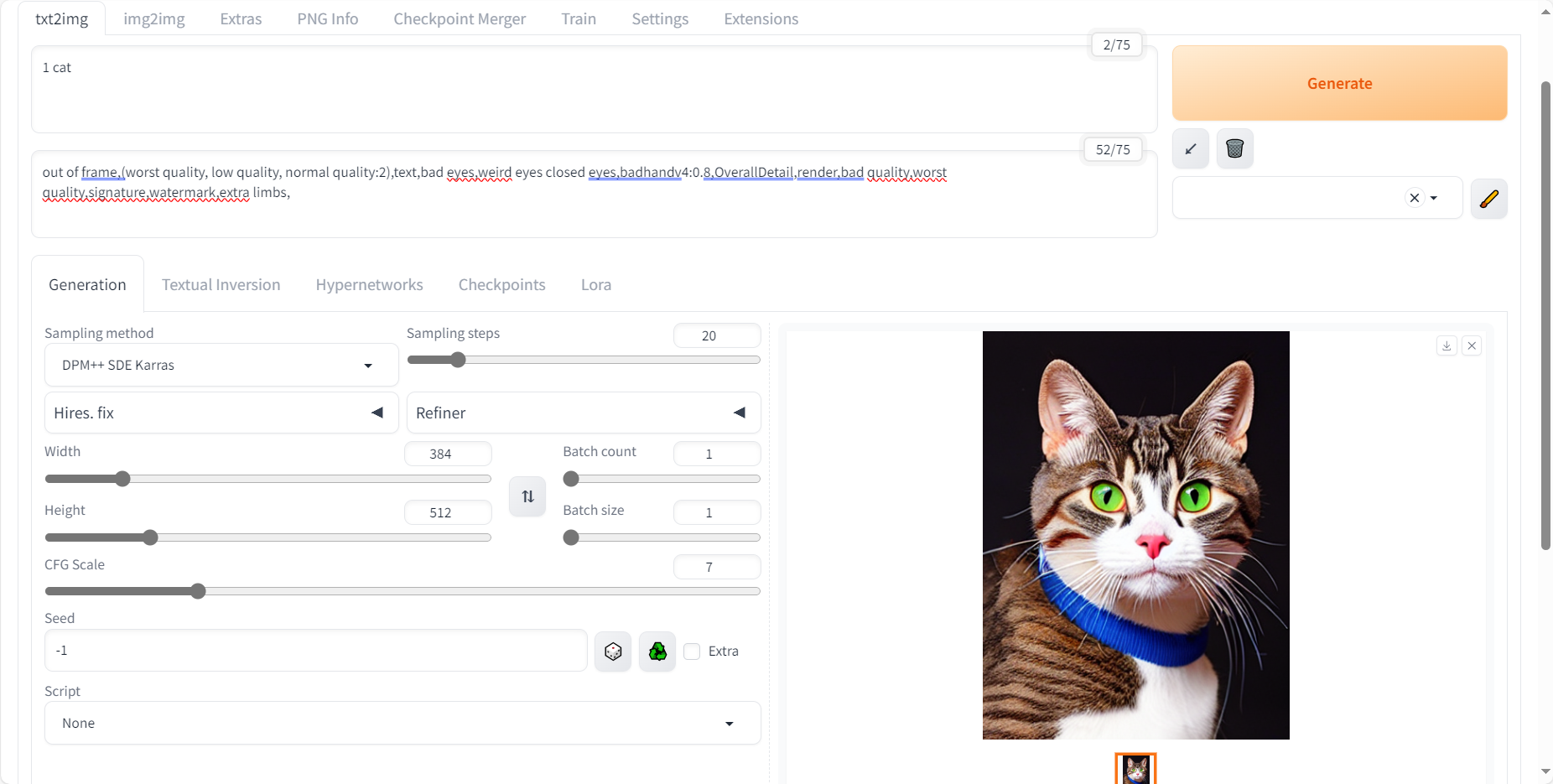
库自带的模型是
v1-5-pruned-emaonly模型,这个模型是官方的1.5 版本预训练模型,是在512*512的小尺寸图像上训练的,所以说如果图像尺寸超过1000的话,容易出现多头多人的情况。 在这里我选择的参数与提示词如下:
-
提示词(prompt):
1 cat -
负面提示词(Negative prompt):
out of frame,(worst quality, low quality, normal quality:2),text,bad eyes,weird eyes closed eyes,badhandv4:0.8,OverallDetail,render,bad quality,worst quality,signature,watermark,extra limbs, -
迭代步数(Steps)、采样器(Sampler)、提示词相关性(CFG scale):
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, -
随机种子(Seed)、图像尺寸(Size)、模型(Model)
Seed: 3052626755, Size: 384x512, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly, Version: v1.6.0
生成的猫猫图如下:

-
-
批量生成
我想要更多的猫猫图,于是增大了生成的
Batch Count和Batch size,生成结果如下。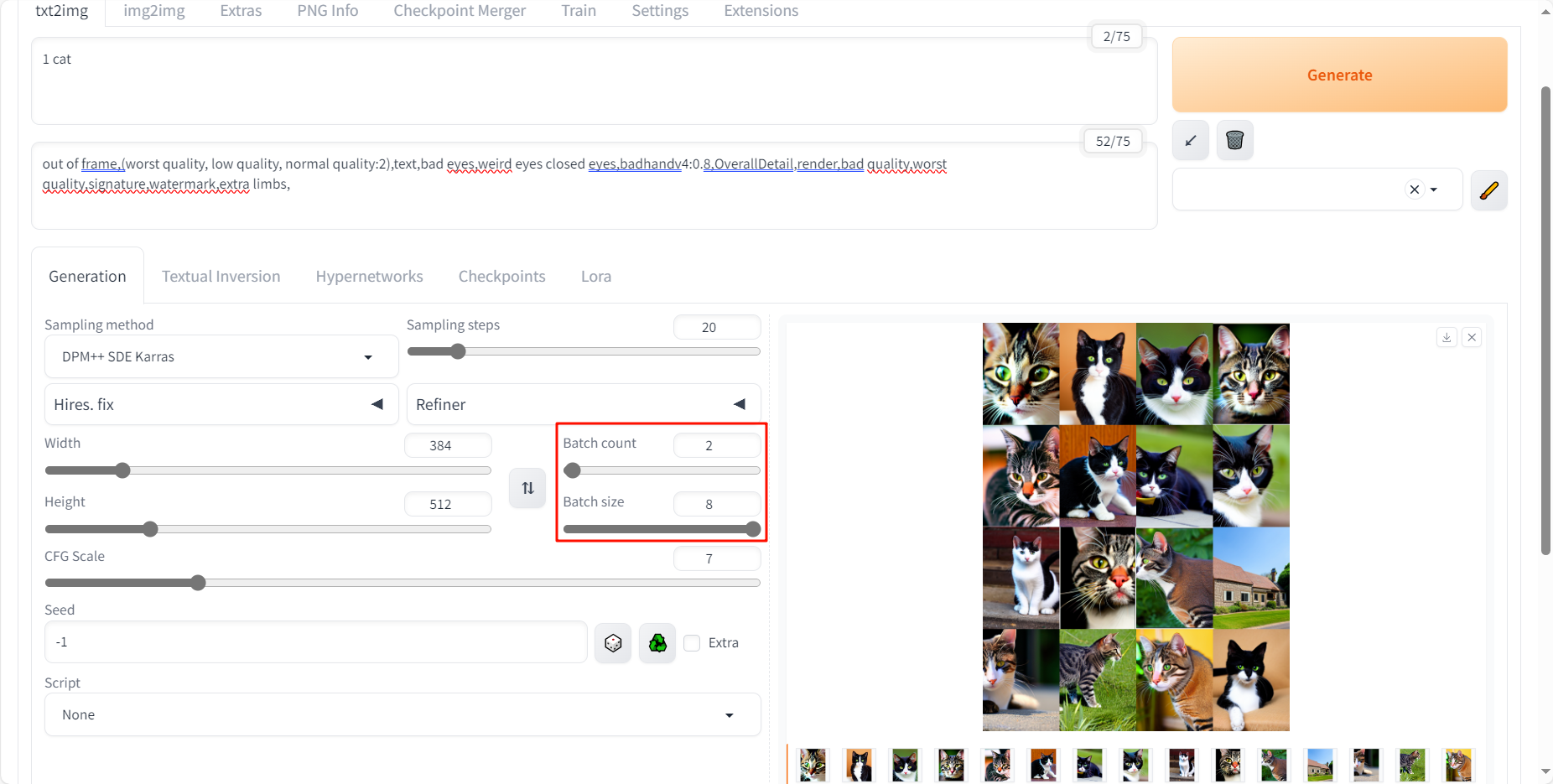
可以看到一下生成了16张猫猫图,它实际上是分了两批,每批生成8张,这样生成的。
Batch count控制了生成批次的数量,Batch size控制每批生成图片的数量。Batch size越大对显卡显存要求越高,当然白嫖的24g显存不在话下了。
可以看到生成的图像各有千秋,甚至有的生成了个房子(太离谱了),所以选择合适的种子很重要。可以通过批量生成找到自己喜欢的图像风格的种子,固定下来进行进一步操作。
我很喜欢第四张,大脸狸花猫,于是点开图片,可以在图片下方看到种子号
2617670965。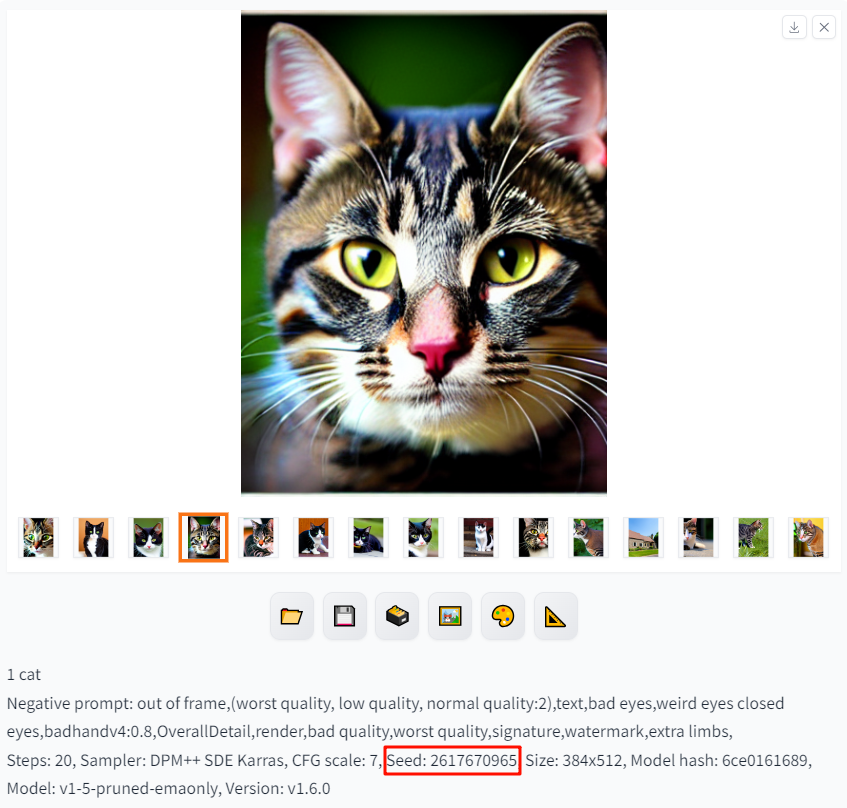
-
图像放大
我想放大刚才选中的大脸狸花猫图,可以通过固定种子,并通过
Hires fix的方法放大生成图像。我想使用一个名为 R-ESRGAN4x 的放大算法,从云平台下载太慢了,选择从 该github链接 本地下载,并放在
/gemini/code/stable-diffusion-webui/models/RealESRGAN/RealESRGAN_x4plus.pth路径下。设置以下参数,重新生成,结果如下。
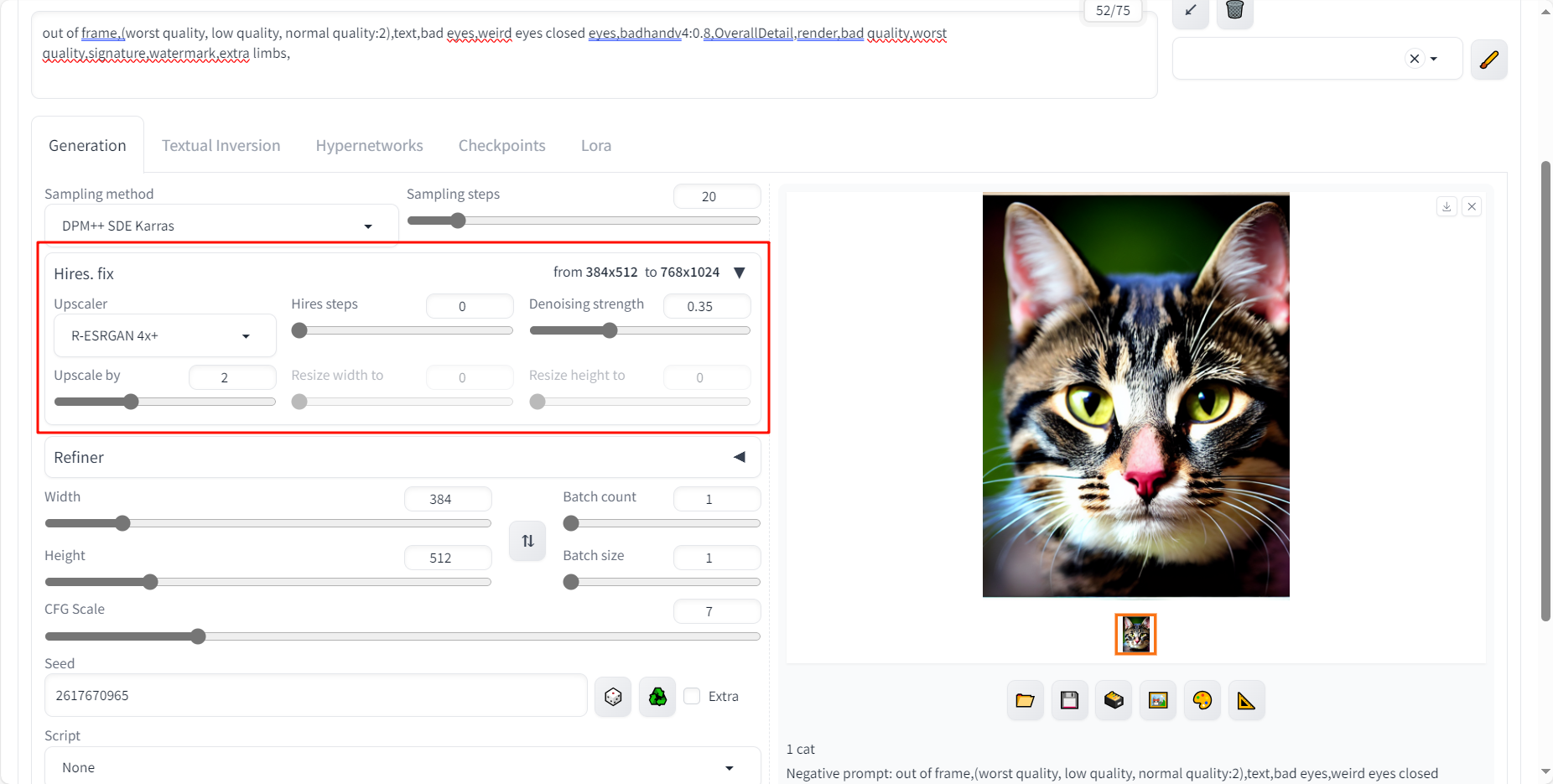
成功将图像尺寸放大到原来的两倍,即 768*1024 的尺寸。图像参数如下:
1 cat Negative prompt: out of frame,(worst quality, low quality, normal quality:2),text,bad eyes,weird eyes closed eyes,badhandv4:0.8,OverallDetail,render,bad quality,worst quality,signature,watermark,extra limbs, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2617670965, Size: 384x512, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly, Denoising strength: 0.35, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+, Version: v1.6.0猫猫图如下:

效果还不错,不过我还想让他更清晰一点,于是选择让他放大4倍,结果如下。

可以看到,真的清晰了不少。
-
图生图
图生图就是以给的图片为基准,生成其他的图片,我就像用刚才生成的猫猫图,来生成一个宇宙的星系,于是写了以下的提示词。
stars,out space,galaxy,负面提示词不变,分两个批次生成16张星系图片,结果如下。
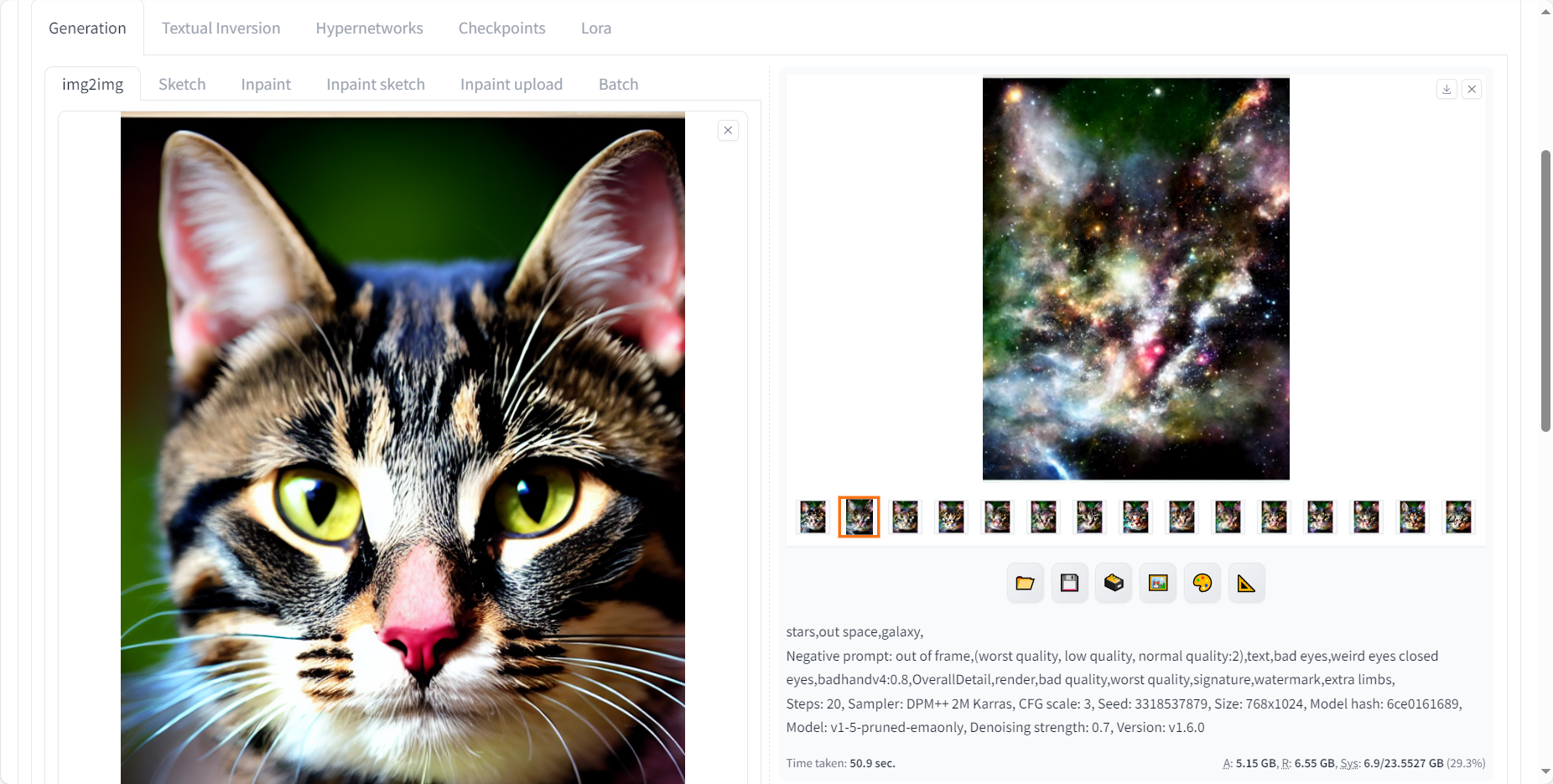
可以看到,生成了具有猫猫形状的星系图案,我从中挑了一张最喜欢的,就是下面这张。

图片参数如下:
stars,out space,galaxy, Negative prompt: out of frame,(worst quality, low quality, normal quality:2),text,bad eyes,weird eyes closed eyes,badhandv4:0.8,OverallDetail,render,bad quality,worst quality,signature,watermark,extra limbs, Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 3, Seed: 3318537879, Size: 768x1024, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly, Denoising strength: 0.7, Version: v1.6.0以上就尝试玩SD的基本功能啦,之后可以再玩一些进阶玩法,用更厉害的模型,添加lora、ControlNet等插件,生成更可控好看的图片。