网站建设职业描述网站后台登录界面代码
本系统主要包括以下功能模块学生、教师、班级、考试评阅、在线考试、试题内容、考试等模块,通过这些模块的实现能够基本满足日常计算机系统平台的操作。
本文着重阐述了计算机系统平台的分析、设计与实现,首先介绍开发系统和环境配置、数据库的设计,接着说明功能模块的详细实现,最后进行了总结。
利用JSP、Eclipse和mysql数据库等知识点,结合相关设计模式、以及软件工程的相关知识,设计一个计算机系统平台,来进行记录学生的信息,以及系统信息的增删改查的功能,根据实现需求,系统需完成这些基本功能:

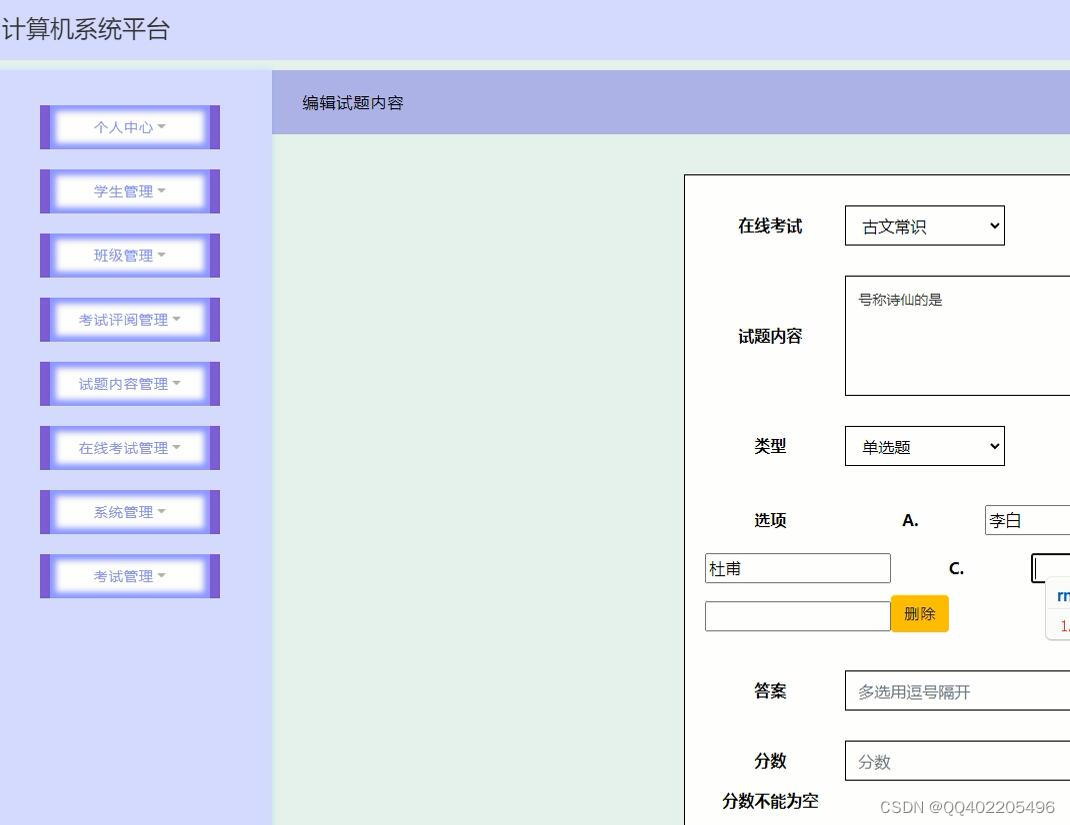
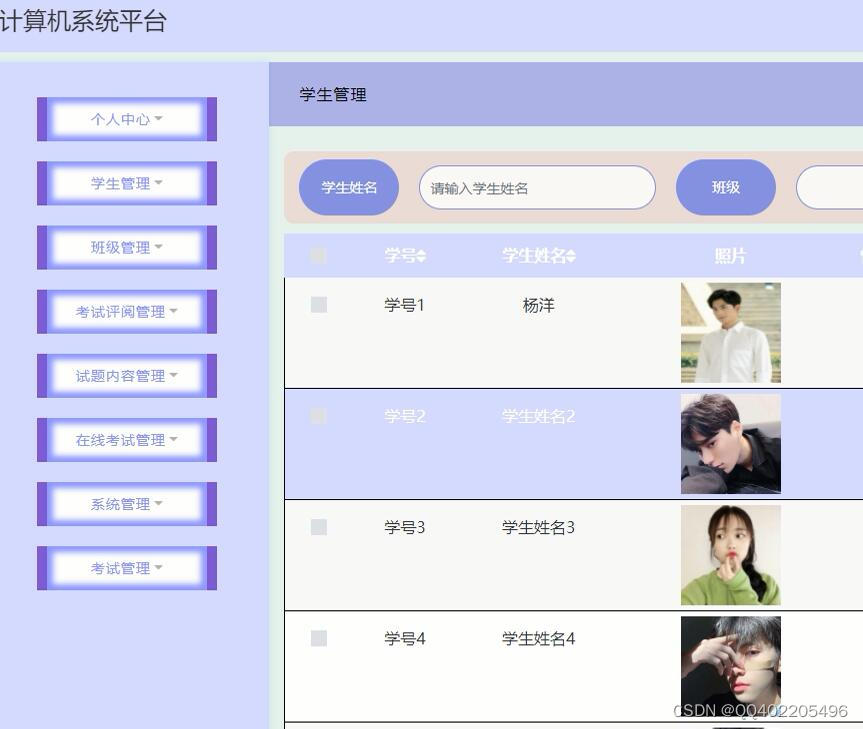

(1)系统合理显示考试评阅、考试等界面。
(2)学生、教师和管理员所有的信息都保存与数据库中。
(3)对计算机管理信息能够进行查询、修改、删除、添加等操作。
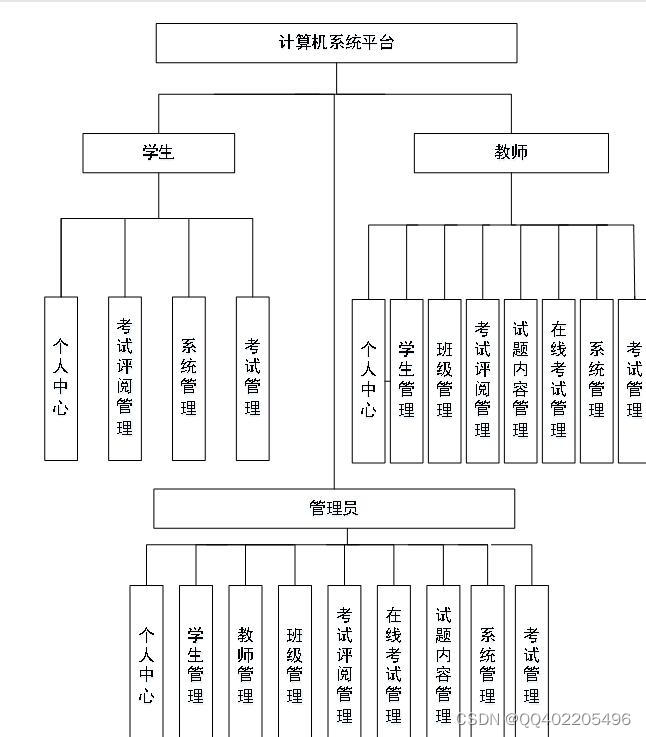
根据计算机系统平台的功能需求,进行系统设计。
学生进入系统可以实现个人中心、考试评阅管理、系统管理、考试管理等进行操作;
后台主要是管理员,管理员功能包括个人中心、学生管理、教师管理、班级管理、考试评阅管理、在线考试管理、试题内容管理、系统管理、考试管理等;
目 录
第一章 绪论 1
1.1 研究背景 3
1.2 计算机管理的现状 5
1.3 系统实现的功能 6
1.4 计算机管理信息系统的特点 6
1.5 本文的组织结构 6
第二章 开发技术与环境配置 7
2.1 JSP技术介绍 7
2.2 mysql数据库介绍 7
2.3 B/S架构 7
2.4 SSM框架 9
第三章 系统分析与设计 10
3.1 可行性分析 10
3.1.1 技术可行性 10
3.1.2 操作可行性 10
3.1.3经济可行性 10
3.2 需求分析 11
3.3 总体设计 11
3.4 数据库设计与实现 11
3.4.1 数据库概念结构设计 12
3.4.2 数据库具体设计 13
第四章 系统功能的具体实现 21
4.1 系统功能模块 21
4.2 管理员功能模块 24
4.3 学生功能模块 27
4.4 教师功能模块 27
第五章 系统测试 29
总 结 30
参考文献 31
致 谢 32
第一章 绪论