网站名和域名能一样吗网站怎么换空间
变量 $
定义变量
$link-color: 'blue';
变量名可以与css中的属性名和选择器名称相同
使用变量
a {color: $link_color;
}
$highlight-border: 1px solid $link_color;
中划线和下划线相互兼容,即中划线声明的变量可以使用下划线的方式引用,反之亦然。
$link-color: blue;
a {color: $link_color;
}
变量作用域
{}中定义的变量为局部变量,仅在{}内有效
$nav-color: #F90;
nav {$width: 100px;width: $width;color: $nav-color;
}
变量默认值
$fancybox-width: 400px !default;
.fancybox {width: $fancybox-width;
}
若导入的sass局部文件声明了$fancybox-width变量,则默认值无效,否则$fancybox-width将默认为400px。
vscode中高亮显示scss代码
安装插件——Beautify css/sass/scss/less
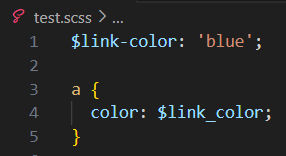
新建文件 test.scss,写入代码
$link-color: 'blue';a {color: $link_color;
}
效果如下
vscode中实时编译scss—查看最终css效果
安装插件——Live Sass Compiler
点击vscode下边栏的 Watch Sass

此时在 test.scss 同目录下会生成文件 test.css,其内容为
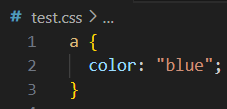
修改 test.scss 中的代码,test.css 会同步编译,方便实时查看最终css效果
样式嵌套
<div class="diary"><h1 class="title">标题</h1><p class="content">内容</p>
</div>
.diary {.title {color: red;}.content {color: blue;}
}
使用伪类选择器时,需要配合&符号,此时&表示父元素
a{color: green;&:hover{color: yellow;}
}
属性嵌套
方式一
nav {border: {style: solid;width: 1px;color: #ccc;}
}
转化为css后,效果如下:
nav {border-style: solid;border-width: 1px;border-color: #ccc;
}
方式二
nav {border: 1px solid #ccc {left: 0px;right: 0px;}
}
转化为css后,效果如下:
nav {border: 1px solid #ccc;border-left: 0px;border-right: 0px;
}
静默注释 //
静默注释是一种内容不会出现在生成的css文件中的注释
body {color: #333; // 这种注释内容不会出现在生成的css文件中padding: 0; /* 这种注释内容会出现在生成的css文件中 */
}
当/* … */注释出现在原生css不允许的地方,如在css属性或选择器中,这些注释也会被抹掉。
body {color /* 这块注释内容不会出现在生成的css中 */: #333;padding: 1; /* 这块注释内容也不会出现在生成的css中 */ 0;
}
循环 @for
@for $i from 1 to 4 {.pd#{$i} {padding: $i*10 + px;}
}
转化为css后,效果如下:
.pd1 {padding: 10px;
}.pd2 {padding: 20px;
}.pd3 {padding: 30px;
}
@for 内可同时循环生成多个样式
@for $i from 1 to 4 {.pd#{$i} {padding: $i*10 + px;}.mr#{$i} {margin: $i*10 + px;}
}
from to 改为 from through 则包含边界
@for $i from 1 through 4 {.pd#{$i} {padding: $i*10 + px;}
}
得到
.pd1 {padding: 10px;
}.pd2 {padding: 20px;
}.pd3 {padding: 30px;
}.pd4 {padding: 40px;
}
混合器 @minxin
用于给一大段样式赋予一个名字,方便样式的复用
和CSS类名的区别是,CSS类名是在html中使用,混合器是在样式代码中使用。
定义混合器 @mixin
@mixin mark {color: red;background: yellow;
}
使用混合器 @include
.note {font-weight: bold;@include mark
}
最终css效果
.note {font-weight: bold;color: red;background: yellow;
}
可传参的混合器
类似JavaScript里的function
@mixin link-colors($normal, $hover, $visited) {color: $normal;&:hover { color: $hover; }&:visited { color: $visited; }
}
调用时直接传参
a {@include link-colors(blue, red, green);
}
最终生成的css效果如下
a { color: blue; }
a:hover { color: red; }
a:visited { color: green; }
如果记不清参数的顺序,可以通过语法$name: value的形式指定每个参数的值。
a {@include link-colors($normal: blue,$visited: green,$hover: red);
}
指定默认参数值
@mixin link-colors($normal,$hover: $normal,$visited: $normal)
{color: $normal;&:hover { color: $hover; }&:visited { color: $visited; }
}
继承 @extend
跟混合器相比,继承生成的css代码相对更少。因为继承仅仅是重复选择器,而不会重复属性,所以使用继承往往比混合器生成的css体积更小。
//通过标签继承样式(默认的浏览器样式不会被继承,因为它们不属于样式表中的样式)
.disabled {color: gray;@extend a;
}
//通过选择器继承样式
.error {border: 1px solid red;background-color: #fdd;
}
.seriousError {@extend .error;border-width: 3px;
}
.seriousError不仅会继承.error自身的所有样式,任何跟.error有关的组合选择器样式也会被.seriousError以组合选择器的形式继承
//.seriousError从.error继承样式
.error a{ //应用到.seriousError acolor: red;font-weight: 100;
}
h1.error { //应用到hl.seriousErrorfont-size: 1.2rem;
}
在class="seriousError"的html元素内的超链接也会变成红色和粗体。