宁晋企业做网站国外优秀的网页设计作品
在当今数字化时代,用户对网页体验的要求日益提高。在网页设计过程中,扮演着至关重要的角色。通过网页原型设计,产品经理能够更好地展示和传达网页的整体布局、导航结构、元素位置和交互效果,从而使团队成员更清晰地了解设计意图,提供及时的反馈,并做出必要的调整,以确保最终的网页设计符合预期和用户需求。因此,网页原型设计在现代网页设计中不可或缺,它为设计师和开发者提供了强大而有效的工具,以创造出更符合用户预期的用户体验。
在本文中,我们将一起探讨以下内容:
• 什么是网页原型设计?
• Web原型设计规范
• Web端原型设计尺寸
• 入门小白都能做的网页原型设计(网页原型图怎么画?)
• 网页原型设计工具推荐
通过阅读本文,相信你将对网页原型设计会有更深入的了解,也将为你的网页设计工作提供更多的灵感和指导。
什么是网页原型设计?
网页原型设计是指在网页设计过程中创建和呈现网页界面的初步模型,它旨在以可视化和交互的方式展示网页的布局、内容和功能,帮助设计师、开发者和客户更好地理解和评估网页的设计概念,从而进行及时的反馈和调整。
网页原型设计的目的是在正式开发网页之前尽早发现和解决潜在的设计问题。通过创建网页原型,设计师可以测试不同的布局和功能选项,评估用户界面的可用性,以及验证设计决策是否符合用户需求。网页原型设计可以帮助团队成员更好地理解用户流程、页面结构和交互细节,从而提高合作效率,并确保最终的网页设计符合预期目标。
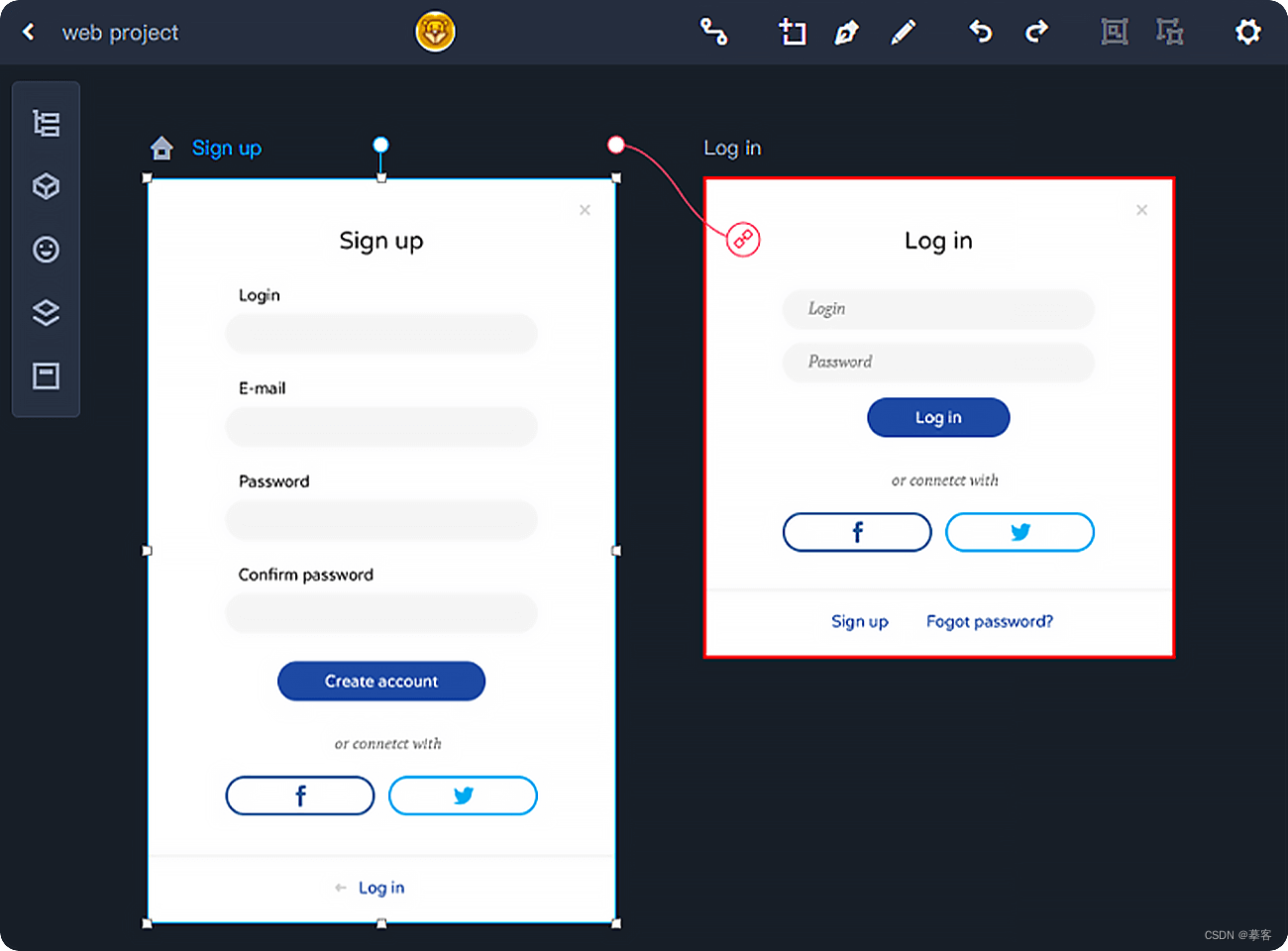
Alt: 网页原型设计
通过网页原型设计,设计师和开发者可以在网页开发过程的早期阶段收集反馈和改进设计,从而提高最终网页的质量和用户体验。它有助于减少后期的修改和重构工作,并最大程度地满足用户的期望和需求。
Web原型设计规范
Web原型设计规范是指在进行Web端原型设计时应遵循的一系列规范和准则,旨在确保设计的一致性、可用性和用户体验。这些规范可以帮助设计师在创建Web原型时遵循最佳实践,并确保最终的设计符合用户需求和预期。

alt: web原型设计规范
以下是一些常见的Web原型设计规范:
• 页面布局和结构:设计清晰、直观的页面布局,包括头部、导航栏、主要内容区域、侧边栏和底部等部分,使页面有层次感和逻辑性。
• 导航设计:设计清晰、直观的导航菜单和链接,使用户能够轻松浏览和导航到网站的不同部分。
• 色彩和视觉风格:选择适合品牌和用户体验的色彩方案,并确保颜色在不同设备上保持一致。
• 字体和排版:选择易读且符合品牌形象的字体,并考虑字号、行距、段落间距等排版因素,以提高页面的可读性和可视化层次。
• 图像和多媒体:优化图像和多媒体文件的大小和格式,以提高页面加载速度和性能。确保图像清晰、相关,并与内容相匹配。
• 响应式设计:确保Web原型在不同设备和屏幕尺寸下具有良好的适应性,采用响应式布局和设计技术,使网页能够自动调整和适应不同的视口。
• 交互和反馈:设计清晰、直观的交互元素和操作流程,使用户能够理解并提供及时的反馈和状态指示,以增强用户的交互体验。
• 页面加载速度:优化网页原型的性能,使用合适的图像压缩、资源缓存和代码优化等技术手段,以加快页面加载速度。
通过遵循这些网页原型设计规范,可以创建出一致、易用且具有良好用户体验的网页原型,这将有助于满足用户需求,提高网站的可用性和吸引力,并确保最终的设计与预期目标相一致。
Web端原型设计尺寸
整体尺寸
Web端原型设计尺寸通常分为桌面端和平板电脑端,以下提供这两种类型的原型设计尺寸:
• 桌面端(Desktop):常见的桌面端原型设计尺寸为 1920px × 1080px,这是目前大多数桌面电脑和笔记本电脑屏幕的分辨率。可以选择适应不同分辨率的宽屏设计,但需要确保主要内容在常见的桌面分辨率下仍然可见。
• 平板电脑(Tablet):平板电脑的屏幕尺寸和分辨率多种多样,常见的平板电脑原型设计尺寸包括 1024px × 768px 和 2048px × 1536px。需要考虑平板电脑的屏幕比例和分辨率,确保设计在不同平板设备上能够适应和呈现良好。
字体规范
● 字体
中文:宋体、微软黑体、苹果系统黑体
英文:Arial、Comis Sans MS等
● 字体大小
最小:12px
普通文字:14px(axure中默认文本标签为14px)
其他字体:要遵循偶数原则
● 字间距
行间距:1.5-2倍
段间距:2-2.5倍
● 字体颜色(安全色)
#333333到#666666 之间
其他尺寸
左右留白:360px
顶部栏:48px
如果是中后台的话,一般配置如下:
左右留白:24px
顶部栏:48px
此外,随着响应式设计的普及,还应考虑设计在不同屏幕尺寸和设备上的自适应性。使用流体布局、媒体查询和断点布局等技术可以实现响应式设计,确保网页在各种设备上都能够适应和呈现良好的用户体验。
入门小白都能做的网页原型设计(网页原型图怎么画?)
对于入门小白而言,想要快速开启原型设计之旅,可以尝试以下两种方式:
使用网页原型模板
这些模板通常已经预先设计好了常见的网页结构和元素,只需要根据自己的需求进行适当的修改和定制即可。
以下是一些模板网站推荐:
:作为一款快速原型设计工具,提供了许多免费的网页原型模板,你可以在其中寻找适合你项目的模板,保存到原型工具中直接使用。
:这是一个聚合了许多 Sketch 原型模板的网站,你可以在其中找到各种类型的网页原型模板。
:AxureHub提供网页产品原型、RP源文件、后台管理原型、APP产品原型、手机H5页面原型、小程序原型的发布和下载,服务于产品经理及交互设计师。
使用快速原型设计工具绘制网页原型图
使用快速原型设计工具可以帮助新手小白快速创建网页原型,并进行交互设计。
以下是详细的步骤(以使用摹客RP为例):
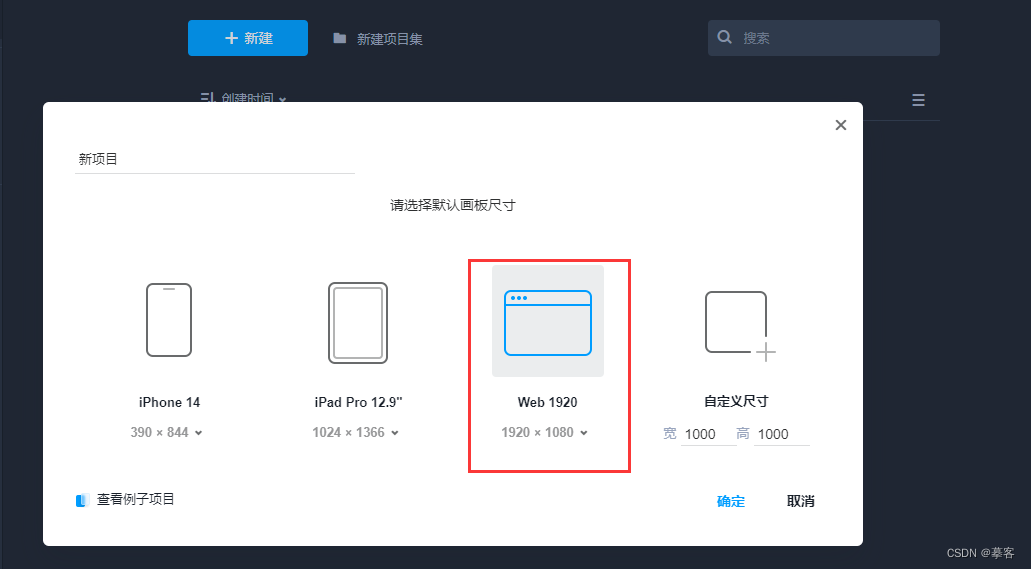
第一步:创建网页原型项目
在摹客RP中创建一个新的项目,并选择或设置自定义页面尺寸。
第二步:新建原型页面
在左侧面板>页面面板>点击新建“+”按钮创建页面,并为页面命名;
第三步:利用组件库快速进行原型制作
在左侧面板内,有组件、图标、资源三个模块,可以直接使用预设组件绘制出页面的主要区块和组件,如导航栏、标题、内容区域等。
• 组件:摹客RP的组件分为基本、容器、常用、图标、批注、形状等,简单组件可以使用文字、矩形、圆形、线条、图片等,复杂组件可以使用表格、批注、动态组件、轮播图等,直接拖入原型图即可使用。除了摹客RP自带的预设组件库外,还提供了8个国内外大厂高保真UI组件库,包括Ant Design,Element UI,TDesign,Arco Design,WeUI,iOS,macOS和Material Design。
• 图标:图标分类有支付、办公、手势、社交、交通、多媒体等,适用于多个原型设计场景。
• 资源:在这个模块中,你可以找到团队内共享的设计资源,从而确保团队在设计方面保持统一性和一致性。这样的集中资源库能够优化团队的工作流程,有助于快速访问和共享所需的设计元素、模板、样式和其他相关资产。
第四步:制作页面跳转交互
通过摹客RP提供的拖拽添加交互功能,将不同页面之间建立链接关系。设定导航菜单、按钮等元素的链接目标,以模拟用户在网页间的导航和跳转。
第五步:添加状态交互
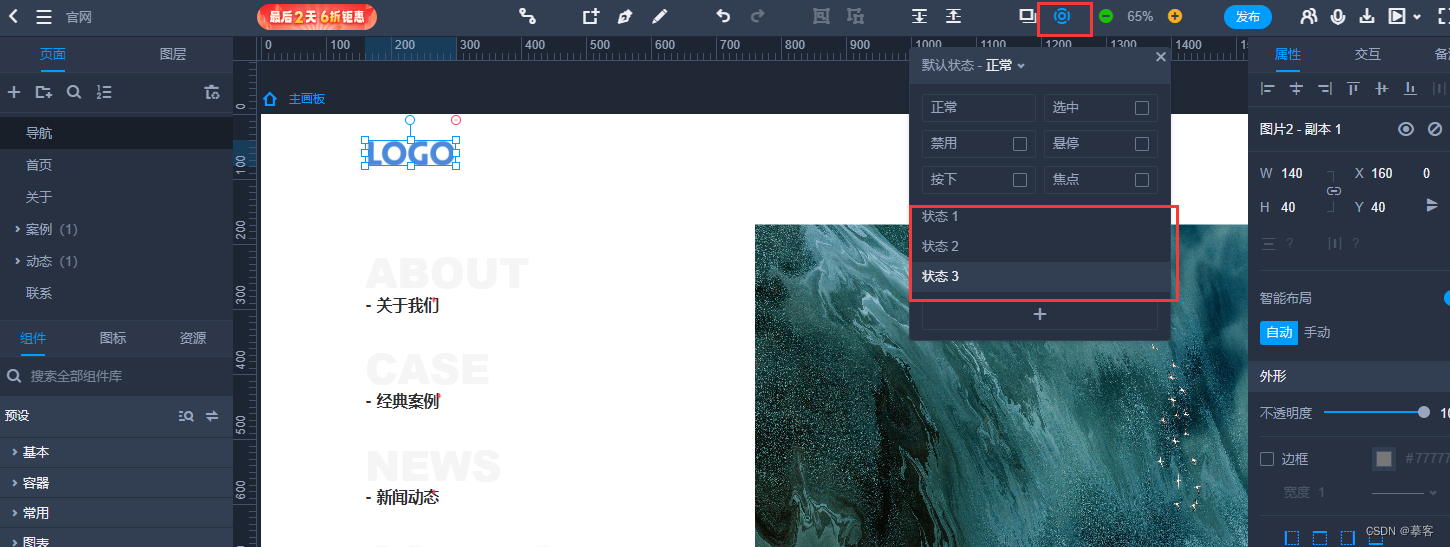
状态交互可以设置细节,比如组件平滑移动的效果,并且设计状态交互后,可以让页面中的某个组件的属性(位置、大小、颜色等)发生改变。
在顶部工具栏中,点击圆形按钮打开状态面板,可以组件设置不同的状态交互。
第六步:完善细节和样式
在基本布局和交互设置完成后,在右侧属性面板中调整文本样式、颜色、字体等细节,确保页面的一致性和视觉美感。
第七步:进行预览和分享
使用摹客RP制作原型图后,可以进行预览和分享。
• 预览:点击右上角的“预览”按钮,即可完成原型预览。
• 分享:点击右上角的“分享”按钮,在弹窗内设置查看权限、评论权限等细节,复制链接,即可完成分享。
此外,你还可以直接使用摹客RP提供的导出功能,将原型导出为HTML格式进行离线演示,以便相关人员进一步的评估、开发和发布。
网页原型设计工具推荐
使用网页原型设计工具可以帮助快速验证概念、优化用户体验、迭代设计、促进团队沟通和提供技术实现指导。这些工具可以提高设计的效率和质量,减少开发过程中的问题和改动,并最终帮助设计师和开发者交付出更好的网页设计。
下面就给大家推荐一些常用且受欢迎的网页原型设计工具:
摹客RP
是一款功能全面且易于使用的原型设计工具,提供了简洁直观的界面和丰富的设计元素,可以快速拖拽创建网页原型。它具备丰富的交互设计功能,可以添加按钮、链接、表单和手势等交互元素,模拟真实用户交互过程。此外,摹客RP还支持多人协作,团队成员可以同时编辑和评论原型,实现协同设计和版本控制。
Axure
Axure RP 是一款功能强大的网页原型设计工具,特别适合需要展示交互细节和复杂逻辑的网页设计项目。Axure提供多种交互功能和动画效果,可以自定义交互行为、过渡效果和动态内容,同时还支持使用动态数据和变量,可以模拟数据的输入和输出,展示应用程序的动态效果和数据交互。
http://Proto.io
http://Proto.io 是一款海外流行的网页原型设计工具,提供了易于使用的拖放功能和丰富的预设组件,可以快速搭建原型界面,并通过实时预览功能进行实时查看和修改。http://Proto.io 可以用于设计和测试网页、移动应用和其他数字产品的用户界面和用户体验。
总结
网页原型设计是网页开发过程中不可或缺的环节,它允许产品经理和设计师模拟用户与网站的交互过程,并根据用户的反馈进行优化。通过测试和评估原型,可以改进网站的导航、布局、内容呈现和交互方式,提供更好的用户体验。
对于新手或初学者来说,选择适合自己项目需求的原型工具非常重要。网页原型设计工具提供了快速、直观和交互式的方式来创建网页原型。通过工具的绘图和交互功能,可以设计网页的外观、界面元素以及模拟用户的交互过程,这些工具还支持用户体验测试和团队协作,以便更好地改进和优化设计。选择适合自己的工具能提高工作效率,并帮助实现更好的用户体验。希望本文提供的信息对你在网页原型设计方面的工作有所帮助。