做外贸网站需要注册公司吗精品网站建设费用 找磐石网络一流
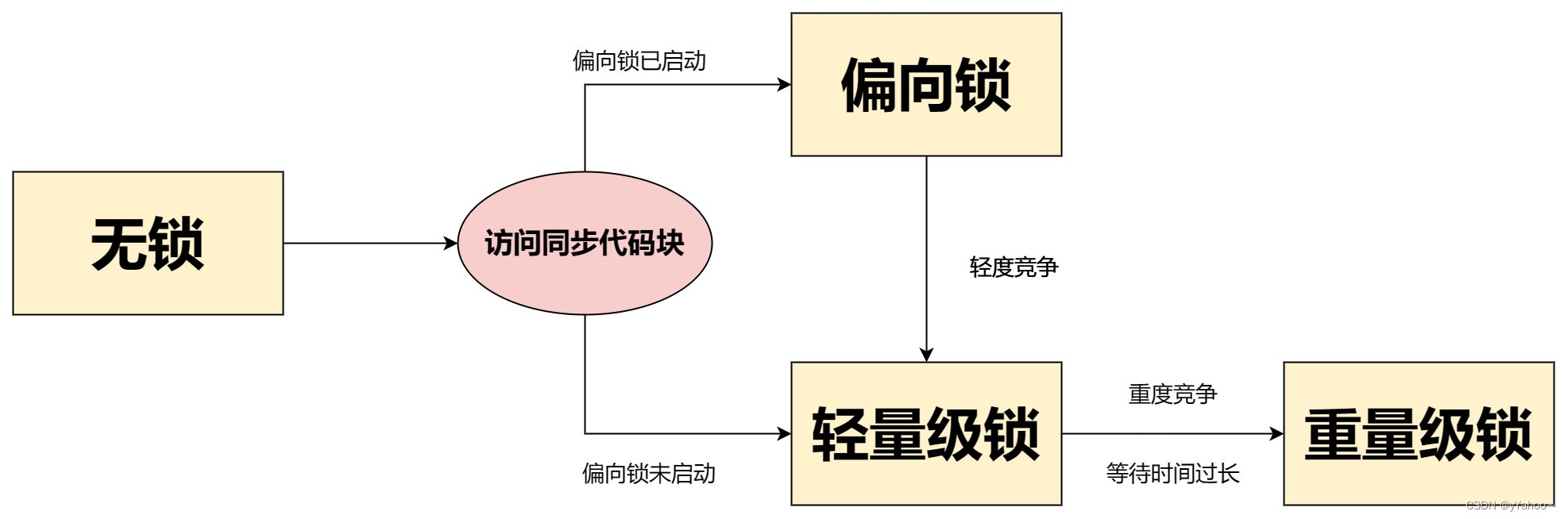
Java 中的锁机制是多线程编程中的一部分。锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。
锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
几种锁状态的关系图
一、偏向锁
偏向锁字面意思是“偏向于第一个获得它的线程”的锁,在单线程的环境下,对于同一个对象的多次加锁,只需记录下该线程ID即可。
偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,偏向锁会升级成轻量级锁。
偏向锁在Java 6和Java 7里是默认启用的,但是它在应用程序启动几秒钟之后才激活。如有必要可以使用JVM参数来关闭延迟:-XX:BiasedLockingStartupDelay=0。
如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:
-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
什么是锁竞争?
如果多个线程轮流获取一个锁,但是每次获取锁的时候都很顺利,没有发生阻塞,那么就不存在锁竞争。
只有当某线程尝试获取锁的时候,发现该锁已经被占用,只能等待其释放,这才发生了锁竞争。
二、轻量级锁
轻量级锁是在多线程的环境下,对于同一个对象的多次加锁,使用CAS操作来进行同步。
当其他线程来竞争时,没有抢到锁的线程将自旋,即不停地循环判断锁是否能够被成功获取,自旋达到一定次数后,轻量级锁会升级为重量级锁。
轻量级锁的获取主要由两种情况:
-
当关闭偏向锁功能时
-
由于多个线程竞争偏向锁导致偏向锁升级为轻量级锁
自旋锁时在多线程环境下,线程请求锁时,不会被挂起,而是采用循环的方式进行自旋。只有当锁的持有者释放锁时,请求锁的线程才能获得锁。
自旋锁的好处:减少线程挂起的时间,提高性能。
三、重量级锁
重量级锁是指当有一个线程获取锁之后,其余所有等待获取该锁的线程都会处于阻塞状态。
重量级锁是在多线程环境下,采用操作系统的互斥量来进行同步。当线程竞争加剧、CAS自旋到一定次数的时候,锁就会升级为重量级锁。当后续线程尝试获取锁时,发现被占用的锁是重量级锁,则直接将自己挂起(而不是忙等),等待将来被唤醒。
自旋锁消耗CPU资源,重量级锁有等待队列,不会消耗CPU资源。
🎈锁可以升级但不能降级的原因
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。
当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
🎈锁的优缺点比对
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗, 和执行非同步方法相比仅存在纳秒级的差距。 | 如果线程间存在锁竞争, | 适用于只有一个线程访问同步块场景 |
| 轻量级锁 | 竞争的线程不会阻塞, | 如果始终得不到锁竞争的线程, 使用自旋会消耗CPU。 | 追求响应时间,同步块执行速度非常快 |
| 重量级锁 | 线程竞争不使用自旋, | 线程阻塞, 响应时间缓慢。 | 追求吞吐量, 同步块执行速度较长 |