网站被镜像怎么做微信公众号免费开通
一、问题提出
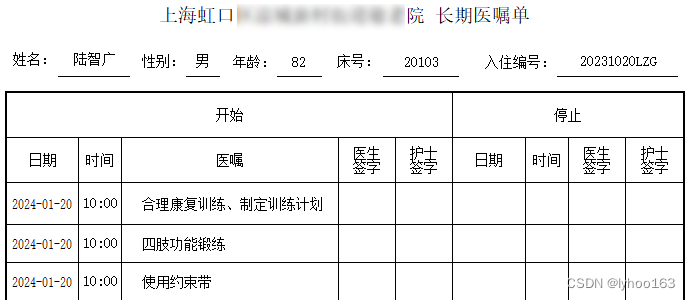
锐浪报表 Grid++Report,打印表格时,对于明细表格的标题,打开换页时,需要重复打印明细表格的标题,或取消打印明细表格的标题。见下表:
首页:

后续页:(无明细表格的标题)

后续页重复打印明细表格的标题:
二、解决办法
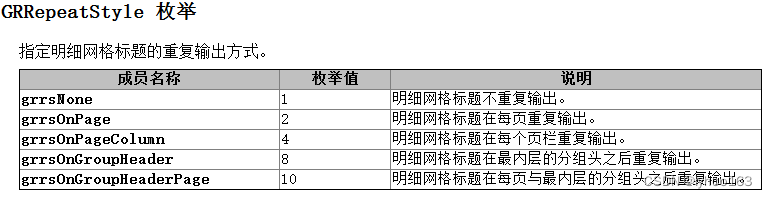
1、RepeatStyle 属性
这里,要使用 RepeatStyle 属性,其值是枚举类型,见下表。
2、在GridppReport的FetchRecord事件中处理
(1)做一个按键选择
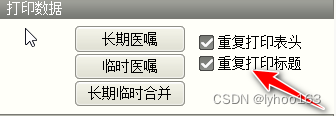
(2)加入以下代码
procedure TY_Standing_orders_Frm.GridppReport3FetchRecord(Sender: TObject);
var S,S1,S2,S3,S4:string;
beginif sCheckBox18.Checkedthen GridppReport3.DetailGrid.ColumnTitle.RepeatStyle:=grrsOnPage // 枚举值2else GridppReport3.DetailGrid.ColumnTitle.RepeatStyle:=grrsNone; // 枚举值0ExportTitle:='医疗服务_医嘱_'+ClientDataSet1.FieldByName('姓名').asString;GRP1:=GridppReport3.AddParameter('UsesN',grptString);GridppReport3.ParameterByName('UsesN').AsString:=UsesName;S1:=ClientDataSet1.FieldByName('性别').asString;S2:=ClientDataSet1.FieldByName('年龄').asString;....
end;
实现让客户,通过选择,打印出所需明细表格的标题的目的。