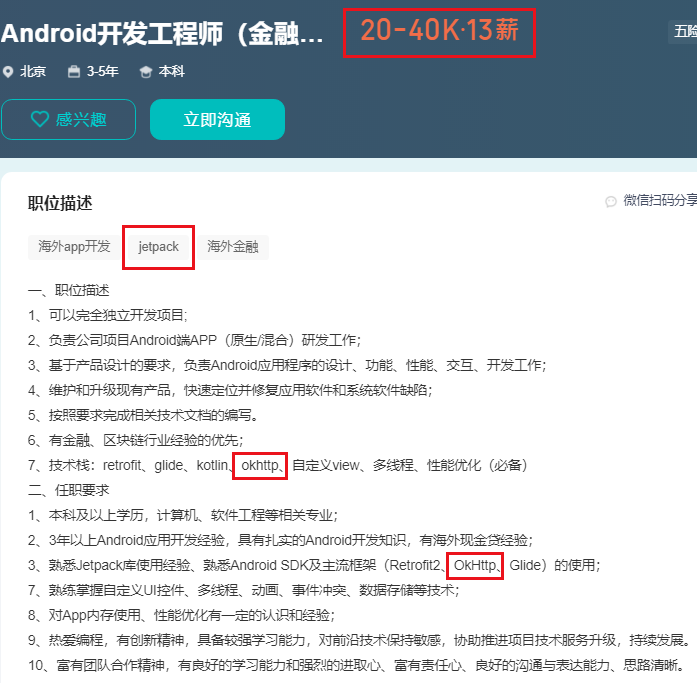
公司专业网站建设标准品购买网站
Jetpack Compose是Android开发领域的一项前沿技术,它提供了一种全新的方式来构建用户界面。近年来,Jetpack Compose在各大招聘等网站上的招聘岗位逐渐增多,薪资待遇也相应提高。本文将从招聘岗位的薪资与技术要求入手,分析Jetpack Compose的岗位优势、学习路线和技术内容,并说说Jetpack Compose的发展。
一、Jetpack Compose的岗位优势
- 技术前沿:Jetpack Compose是Android开发领域的新兴技术,采用了声明式的UI编程模型,相较于传统的基于XML的布局方式更加灵活和直观。在招聘岗位中,对于掌握Jetpack Compose的开发者有着较高的要求,这意味着掌握Jetpack Compose的开发者在技术上具备了一定的竞争优势。
- 提升开发效率:Jetpack Compose的声明式UI编程模型使得开发者可以更加便捷地构建用户界面,减少了繁琐的布局代码,提升了开发效率。这也是招聘岗位中对于具备Jetpack Compose开发经验的开发者的一个重要要求。
- 跨平台支持:Jetpack Compose不仅支持Android平台,还可以在其他平台上进行开发,如桌面应用程序、Web应用程序等。这意味着掌握Jetpack Compose的开发者可以更加灵活地应对多种开发需求,具备更广泛的职业发展空间。
二、Jetpack Compose的学习路线与技术内容
-
学习路线:要学习Jetpack Compose,首先需要掌握Kotlin语言基础,因为Jetpack Compose是使用Kotlin语言进行开发的。其次,可以通过官方文档、教程和示例代码来学习Jetpack Compose的使用方法和原理。 资料参考:《Jetpack全家桶与架构师技术深度讲解》
-
技术内容:Jetpack Compose包括了一系列的组件和API,用于构建用户界面。其中一些重要的技术内容包括:
- 组件:Jetpack Compose提供了一系列的组件,如Text、Button、Image等,用于构建用户界面的各个部分。
- 布局:Jetpack Compose使用了ConstraintLayout和Column、Row等布局方式,使得界面布局更加直观和灵活。
- 状态管理:Jetpack Compose引入了一种新的状态管理方式,通过使用State和MutableState等概念来管理界面状态的变化。
- 动画效果:Jetpack Compose提供了一套强大的动画效果库,开发者可以通过简单的代码实现各种动画效果,为用户带来更加流畅和生动的交互体验。
- 主题和样式:Jetpack Compose支持自定义主题和样式,开发者可以根据需求自定义界面的外观和风格,实现个性化的用户界面。
- 生命周期和数据流:Jetpack Compose引入了一种新的生命周期和数据流管理方式,通过使用ViewModel和LiveData等概念来管理界面的数据和生命周期,使得开发者可以更加方便地处理数据的变化和界面的更新。
三、Jetpack Compose发展
Jetpack Compose作为Android开发领域的新兴技术,具有广阔的前景和发展空间。以下几个方面展示了Jetpack Compose的前景:
- Google的支持:Jetpack Compose是由Google官方推出的技术,得到了Google的全力支持和投入。这意味着Jetpack Compose将会得到持续的更新和改进,同时也会得到更多的资源和社区支持。
- 趋势与需求:随着移动应用的日益普及和用户对于用户界面的要求不断提高,开发者对于更加灵活、高效的界面构建方式的需求也越来越强烈。Jetpack Compose作为一种全新的UI编程模型,能够有效地满足这些需求,因此在招聘岗位中对于掌握Jetpack Compose的开发者的需求也在逐渐增加。
- 跨平台支持:Jetpack Compose不仅仅局限于Android平台,还可以在其他平台上进行开发。这意味着掌握Jetpack Compose的开发者不仅可以在Android领域找到更多的职业机会,还可以在其他平台上进行开发,拓宽自己的职业发展空间。
综上所述,Jetpack Compose作为Android开发领域的一项前沿技术,具有技术前沿、提升开发效率和跨平台支持等优势。学习Jetpack Compose需要掌握Kotlin语言基础,并深入了解其组件、布局、状态管理、动画效果等技术内容。Jetpack Compose的前景非常广阔,得到了Google的支持,满足了开发者对于更灵活高效的界面构建方式的需求,并具备跨平台开发的能力。因此,掌握Jetpack Compose的开发者将具备竞争优势,并在Android开发领域拥有更广阔的职业发展空间。