焦作网站建设公司如何建设一个网站网页
操作环境:
MATLAB 2022a
1、算法描述
1. DS-CDMA系统
DS-CDMA (Direct Sequence Code Division Multiple Access) 是一种多址接入技术,其基本思想是使用伪随机码序列来调制发送信号。DS-CDMA的特点是所有用户在同一频率上同时发送和接收信息,但每个用户使用不同的编码序列。这样,在接收端可以使用与发送时相同的编码序列进行解扩展,从而提取出目标用户的信号,而其他用户的信号则被视为噪声。
DS-CDMA的主要特点和操作如下:
-
信号调制与扩频: 每个用户的数据信号都会与一个独特的伪随机码序列(称为扩频码或切片码)进行调制。这一过程称为扩频,其结果是信号的带宽远大于原始数据信号的带宽。
-
伪随机码的选择: 这些伪随机码被设计为彼此之间的互相关性极低,这意味着一个用户的伪随机码与另一个用户的伪随机码的相关性接近于零。
-
多用户接入: 由于每个用户都有独特的扩频码,因此多个用户可以在同一频率范围内同时传输信号。接收器知道每个用户的扩频码,因此可以分辨并解码每个用户的数据。
-
抗干扰性: DS-CDMA由于其扩频的特性,具有很高的抗干扰性和抗多径衰落的能力。这使其在无线通信中尤为有价值,因为无线环境中的信号经常受到多种类型的干扰。
-
解扩展和解调: 在接收端,为了提取出目标用户的信号,会使用与发送端相同的伪随机码对接收到的信号进行解扩展。由于DS-CDMA系统中的伪随机码是正交的,因此目标用户的信号可以被有效地解码,而其他用户的信号则被视为噪声并被滤除。
-
容量: 与其他多址接入技术相比,CDMA在某些情况下可以提供更高的用户容量。但这也受到系统的干扰限制、信道条件和系统设计的影响。
-
软容量: DS-CDMA具有所谓的“软容量”的特点。这意味着系统的容量不是固定的,而是可以根据用户的信道质量、移动速度等因素进行动态调整。
DS-CDMA广泛应用于无线通信系统,尤其是第二代(2G)和第三代(3G)移动通信技术中,例如IS-95、CDMA2000和WCDMA。
2. m序列 (最大长度序列)
m序列是一种伪随机二进制序列,具有好的自相关和互相关特性。它的周期为 2^n−1,其中n为寄存器的个数。m序列的特点是在一个周期内,0和1的数目差异不超过1。
3. Gold序列
Gold序列是基于两个m序列通过特定的方式生成的。具体地说,取两个线性反馈移位寄存器生成的m序列(这两个m序列的特性多项式必须是互为本原多项式配对),然后对这两个m序列进行模2加法(异或运算)得到Gold序列。Gold序列的主要特性是其互相关特性比m序列差,但是Gold序列的集合数量大于m序列,因此在需要大量不同的伪随机序列时,Gold序列会是一个好的选择。
4. 正交Gold序列
正交Gold序列并不是直接从Gold序列中得到的。而是通过特定的方式构造出来的,使得这些序列之间是正交的,即它们之间的互相关为0。正交Gold序列通常用于同步或者当我们希望多个序列之间完全没有干扰时。
总结:DS-CDMA系统利用伪随机码序列来区分不同的用户,其中m序列、Gold序列和正交Gold序列都是常用的伪随机码序列。这些序列各有优势和使用场景,选择哪种取决于具体的应用需求。
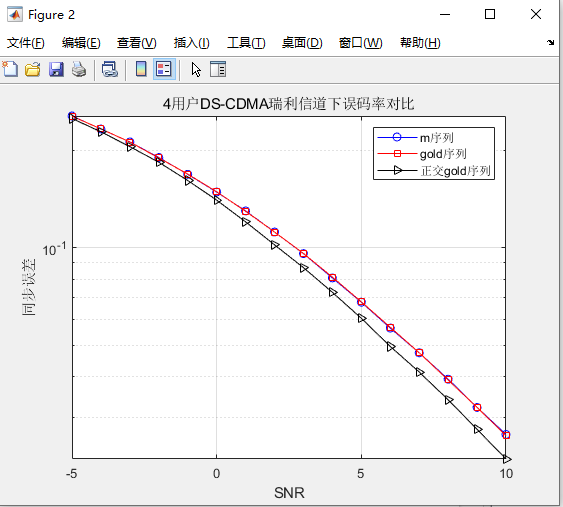
2、仿真结果演示
AWGN信道

rayleigh信道
3、关键代码展示
略
4、MATLAB 源码获取
V
点击下方名片