北京网站建设网站建设ssh鲜花礼品网站建设
一、浅谈HTTPS
我们都知道HTTP并非是安全传输,在HTTPS基础上使用SSL协议进行加密构成的HTTPS协议是相对安全的。目前越来越多的企业选择使用HTTPS协议与用户进行通信,如百度、谷歌等。HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。网上有诸多资料,有些写得过于晦涩难懂,尤其是需要密码学的一些知识。我做了一下简单的整理,刨除复杂的底层实现,单从理解SSL协议的角度宏观上认识一下HTTPS。一言以弊之,HTTPS是通过一次非对称加密算法(如RSA算法)进行了协商密钥的生成与交换,然后在后续通信过程中就使用协商密钥进行对称加密通信。HTTPS协议传输的原理和过程简图如下所示:
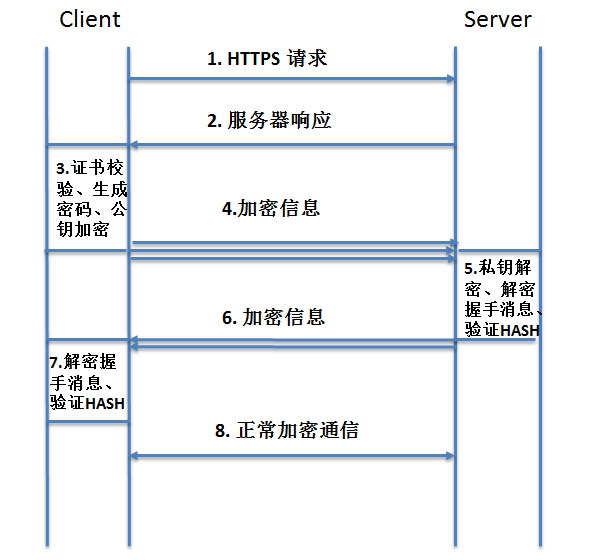
一共有8个步骤,我们针对每一步,具体看看发生了什么事:
第一步,客户端发起明文请求:将自己支持的一套加密规则、以及一个随机数(Random_C)发送给服务器。
第二步,服务器初步响应:服务器根据自己支持的加密规则,从客户端发来的请求中选出一组加密算法与HASH算法,生成随机数,并将自己的身份信息以证书(CA)的形式发回给浏览器。CA证书里面包含了服务器地址,加密公钥,以及证书的颁发机构等信息。这时服务器给客户端的包括选择使用的加密规则、CA证书、一个随机数(Random_S)。
第三步,客户端接到服务器的初步响应后做四件事情:
(1)证书校验: 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等)。
(2)生成密码:浏览器会生成一串随机数的密码(Pre_master),并用CA证书里的公钥加密(enc_pre_master),用于传给服务器。
(3)计算协商密钥:
此时客户端已经获取全部的计算协商密钥需要的信息:两个明文随机数 Random_C 和 Random_S 与自己计算产生的 Pre-master,计算得到协商密钥enc_key。
enc_key=Fuc(random_C, random_S, Pre-Master)
(4)生成握手信息:使用约定好的HASH计算握手消息,并使用协商密钥enc_key及约定好的算法对消息进行加密。
第四步,客户端将第三步产生的数据发给服务器:
这里要发送的数据有三条:
(1)用公钥加密过的服务器随机数密码enc_pre_master
(2)客户端发给服务器的通知,”以后我们都要用约定好的算法和协商密钥进行通信的哦”。
(3)客户端加密生成的握手信息。
第五步,服务器接收客户端发来的数据要做以下四件事情:(1)私钥解密:使用自己的私钥从接收到的enc_pre_master中解密取出密码Pre_master。
(2)计算协商密钥:此时服务器已经获取全部的计算协商密钥需要的信息:两个明文随机数 Random_C 和 Random_S 与Pre-master,计算得到协商密钥enc_key。
enc_key=Fuc(random_C, random_S, Pre-Master)
(3)解密握手消息:使用协商密钥enc_key解密客户端发来的握手消息,并验证HASH是否与客户端发来的一致。
(4)生成握手消息使用协商密钥enc_key及约定好的算法加密一段握手消息,发送给客户端。
第六步,服务器将第五步产生的数据发给客户端:
这里要发的数据有两条:
(1)服务器发给客户端的通知,”听你的,以后我们就用约定好的算法和协商密钥进行通信哦“。
(2)服务器加密生成的握手信息。
第七步,客户端拿到握手信息解密,握手结束。
客户端解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束。
第八步,正常加密通信
握手成功之后,所有的通信数据将由之前协商密钥enc_key及约定好的算法进行加密解密。
这里客户端与服务器互相发送加密的握手消息并验证,目的是为了保证双方都获得了一致的密码,并且可以正常的加密解密数据,为后续真正数据的传输做一次测试。另外,HTTPS一般使用的加密与HASH算法如下:非对称加密算法:RSA,DSA/DSS对称加密算法:AES,RC4,3DESHASH算法:MD5,SHA1,SHA256其中非对称加密算法用于在握手过程中加密生成的密码,对称加密算法用于对真正传输的数据进行加密,而HASH算法用于验证数据的完整性。由于浏览器生成的密码是整个数据加密的关键,因此在传输的时候使用了非对称加密算法对其加密。非对称加密算法会生成公钥和私钥,公钥只能用于加密数据,因此可以随意传输,而服务器的私钥用于对数据进行解密,所以服务器都会非常小心的保管自己的私钥,防止泄漏。
二、Fiddler抓取HTTPS协议原理
我们都知道,Fiddler是个很好的代理工具,可抓取协议请求用于调试。关于Fiddler抓取HTTP协议的原理和配置比较简单,对Fiddler和客户端稍作配置,便能使得Fiddler轻易地获取HTTP请求。但是由于HTTPS协议的特殊性,要进一步地配置Fiddler,我们首先要了解一下fiddler抓取HTTPS协议的原理才能更好地理解如何对fiddler进行配置。Fiddler本身就是一个协议代理工具,在上一节HTTPS原理图上,客户端与服务器端进行通信的过程全部都由Fiddler获取到,也就是如下图所示:
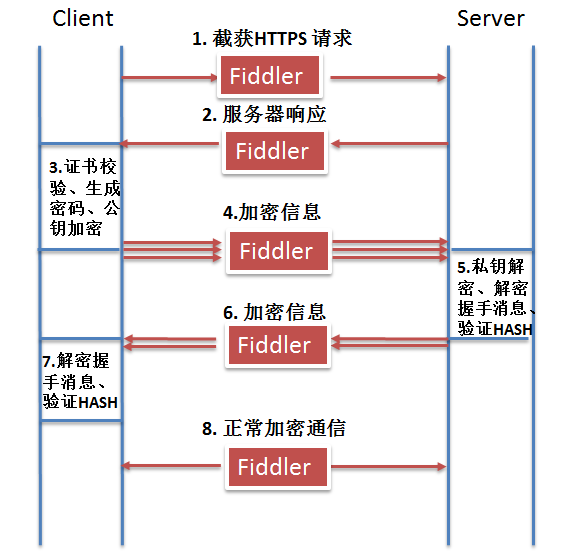
我们看到Fiddler抓取HTTPS协议主要由以下几步进行:
第一步,Fiddler截获客户端发送给服务器的HTTPS请求,Fiddler伪装成客户端向服务器发送请求进行握手 。
第二步,服务器发回相应,Fiddler获取到服务器的CA证书, 用根证书公钥进行解密, 验证服务器数据签名, 获取到服务器CA证书公钥。然后Fiddler伪造自己的CA证书, 冒充服务器证书传递给客户端浏览器。
第三步,与普通过程中客户端的操作相同,客户端根据返回的数据进行证书校验、生成密码Pre_master、用Fiddler伪造的证书公钥加密,并生成HTTPS通信用的对称密钥enc_key。
第四步,客户端将重要信息传递给服务器, 又被Fiddler截获。Fiddler将截获的密文用自己伪造证书的私钥解开, 获得并计算得到HTTPS通信用的对称密钥enc_key。Fiddler将对称密钥用服务器证书公钥加密传递给服务器。
第五步,与普通过程中服务器端的操作相同,服务器用私钥解开后建立信任,然后再发送加密的握手消息给客户端。
第六步,Fiddler截获服务器发送的密文, 用对称密钥解开, 再用自己伪造证书的私钥加密传给客户端。
第七步,客户端拿到加密信息后,用公钥解开,验证HASH。握手过程正式完成,客户端与服务器端就这样建立了”信任“。
在之后的正常加密通信过程中,Fiddler如何在服务器与客户端之间充当第三者呢?
服务器—>客户端:Fiddler接收到服务器发送的密文, 用对称密钥解开, 获得服务器发送的明文。再次加密, 发送给客户端。
客户端—>服务端:客户端用对称密钥加密,被Fiddler截获后,解密获得明文。再次加密,发送给服务器端。由于Fiddler一直拥有通信用对称密钥enc_key, 所以在整个HTTPS通信过程中信息对其透明。
从上面可以看到,Fiddler抓取HTTPS协议成功的关键是根证书(具体是什么,可Google),这是一个信任链的起点,这也是Fiddler伪造的CA证书能够获得客户端和服务器端信任的关键。
接下来我们就来看如果设置让Fiddler抓取HTTPS协议。
三、Fiddler抓取HTTPS设置
注意以下操作的前提是,手机已经能够连上Fiddler,这部分的配置过程简单就不赘述了,可参考:手机如何连接Fiddler 。
如何继续配置让Fiddler抓取到HTTPS协议呢?
(一)首先对Fiddler进行设置:打开工具栏->Tools->Fiddler Options->HTTPS

选中Capture HTTPS CONNECTs,因为我们要用Fiddler获取手机客户端发出的HTTPS请求,所以中间的下拉菜单中选中from remote clients only。选中下方Ignore server certificate errors.(二)然后,就是手机安装Fiddler证书。
这一步,也就是我们上面分析的抓取HTTPS请求的关键。
操作步骤很简单,打开手机浏览器,在浏览器地址输入代理服务器IP和端口,会看到一个Fiddler提供的页面。
接着点击最下方的FiddlerRoot certificate,这时候点击确定安装就可以下载Fiddler的证书了。
下载安装完成好后,我们用手机客户端或者浏览器发出HTTPS请求,Fiddler就可以截获到了,就跟截获普通的HTTP请求一样。
jmeter发送HTTPS请求
jmeter一般来说是压力测试的利器,最近想尝试jmeter和BeanShell进行接口测试。由于在云阅读接口测试的过程中需要进行登录操作,而登录请求是HTTPS协议。这就需要对jmeter进行设置。
(一)设置HTTP请求
我们首先右键添加线程组,然后继续右键添加控制器,由于登陆操作只请求一次,因而选择仅一次控制器。接下来右键添加sampler->HTTP请求,设置HTTP请求。这里注意的地方首先是端口号,如果只是普通的HTTP协议,默认不填,而这里是HTTPS协议,因而填端口号443。另外“协议”这儿填“https”。请求体数据,由于云阅读登陆时的post数据是json结构的,所以填在Body Data这里,用大括号将数据组织起来。PS:实际上应该是post请求,截图过快忘记改了~

(二)设置Jmeter代理
刚刚讲了HTTPS协议和代理控制发送HTTPS请求的原理,我们知道要成功地发送HTTPS请求,关键之处就是代理的设置。首先我们要在线程组里添加一个录制控制器,不然无法生成Jmeter的CA证书文件。然后在工作台右键添加-〉非测试元件-〉HTTP代理服务器。选择默认端口是8080即可。直接点击启动。
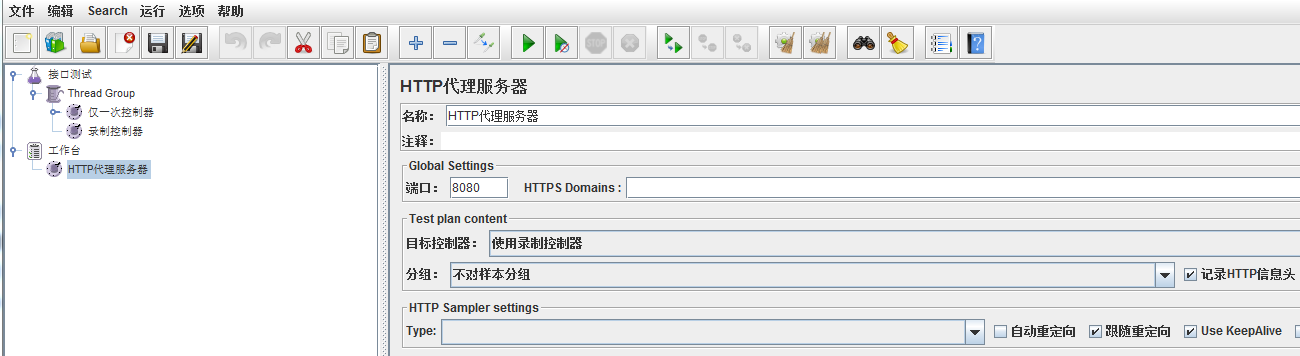
点击启动后弹出页面提示CA证书已经生成,在Bin目录下。点击确定即可。

(三)开启Jmeter代理
找到工具栏“选项”-〉SSL管理器。打开bin目录下的ApacheJMeterTemporaryRootCA.crt即可。

(四)修改HTTP请求
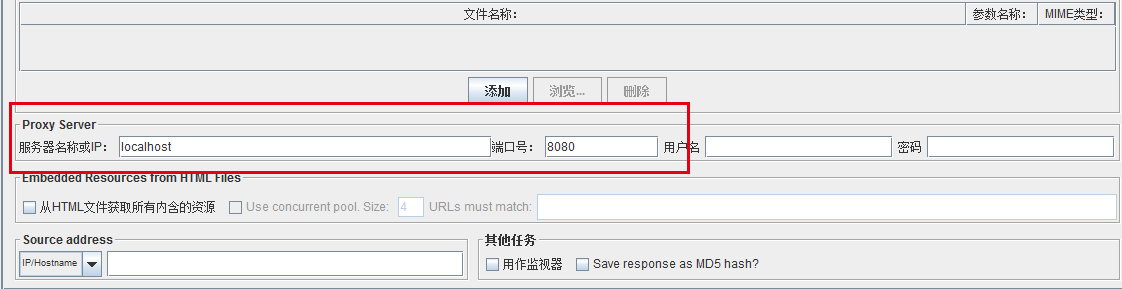
现在已经设置好代理,重新修改下已经创建好的HTTP请求。再最下方Proxy server处添加代理服务器:localhost(本机上搭建的Jmeter代理),端口号就是8080。保存一下整个计划就可以。
(五)添加HTTP请求头
由于我的请求体数据是json类型的,而默认HTTP请求头的content-Type是application/x-www-form-urlencoded。所以我们要在HTTP请求基础上添加一个HTTP请求头,设置Content-Type为application/json类型。

(六)添加结果查看树
在HTTP代理后添加-〉监听器-〉查看结果树。

(七)执行HTTPS请求,并查看结果
点击工具栏的保存,然后点击运行按钮,接下来就可以在结果树中查看运行结果。我们看到运行成功,表示HTTPS请求成功!

最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
