百度站长快速收录和生活app下载安装最新版
云原生是应用上云的标准路径,也是未来发展大的趋势。如何将业务平滑过渡到云上?怎样应对上云期间的各项挑战呢?中电金信基于金融级数字底座“源启”打造了一款非常稳定可靠、多云异构、安全可控、开放灵活的容器平台产品——源启容器平台KubeGien,是源启四大平台之一的数字基础支撑平台重要组成部分,源启通过该平台向上实现应用的云原生容器化支撑,向下屏蔽多种异构底层基础计算环境的差异,助力广大用户打造云原生转型的破浪之舰,一路披荆斩棘、砥砺前行。

提到云化转型,不得不提及云原生。什么是云原生呢?01 云化转型的征程——产品概念
它是以容器、微服务、DevOps为代表的技术体系和方法论,应用生于云并且成长于云,是应用上云的标准化实现路径。云原生能够最大程度发挥云的优势,有极致的弹性,服务故障时可自愈,具备大规模可复制的能力,助力实现异构资源标准化,重塑IT数字基础设施。
为什么说云原生重塑了IT底层基础设施呢?
举例说明,传统的IT基础设施就像铁锅大烩菜,所有东西混杂在一起,一不小心就会串味儿。用虚拟机基础设施就好比砂锅米线,不会串味但是有点废锅人手一个。最后云原生基础设施则好比鸳鸯火锅,用更少的资源去搭配更多的东西,界限分明不串味儿,从而更好地降本增效和管控资源。
01 传统IT基础设施业务部署模式
物理机承载一切,堆叠杂乱,业务规模起来,无法运维。
02 虚拟机基础设施部署模式
分类有序部署,但虚拟机遍地,动辄上千License费用、运维成本、资源浪费(需要太多船)。
03 云原生数字基础设施部署模式
集装箱(容器)屏蔽货物属性,堆叠有序,管理通过货运码头(kubernetes)有序调度。
但云原生转型之路并不平坦,常常面临各种问题,比如硬件兼容性、成本问题、服务集成、稳定性和易用性等,需要借助“杀器”一一化解。源启容器平台KubeGien就像055导弹驱逐舰,帮助用户消灭云原生转型之路上的敌人,清除障碍。

云原生转型遇到的各种问题
055型驱逐舰是中国海军有史以来建造的吨位最大、技术先进的全能型防空驱逐舰,是我国海军驱逐舰发展史上一个重要的里程碑,也是航母身边当之无愧的“带刀侍卫”。就像055一样,源启容器平台KubeGien在垂发、指挥、雷达、操控、近防、舰炮等装备性能上,具备灵活的PAAS服务集成、异构资源统一管理、灵活分级一云多芯、智能弹性应用管理、稳定安全容器底座以及易用灵活服务能力,依靠六大杀手锏为用户打造云原生转型之路上的破浪之舰。
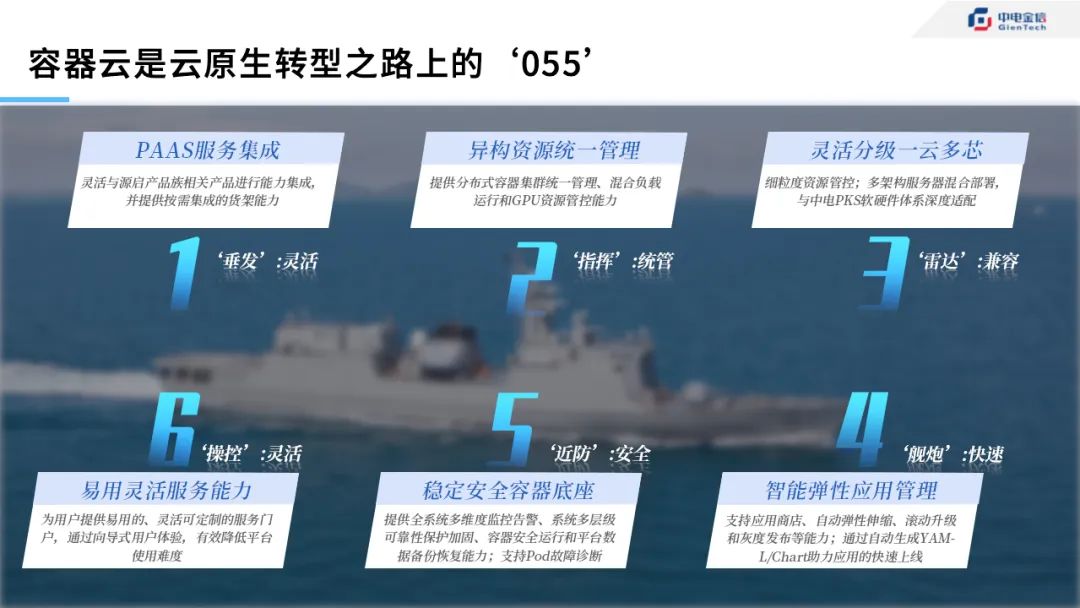
源启容器平台KubeGien的“055型六大杀手锏”
02 如何构筑破浪之舰——产品架构
如何构建破浪之舰?灵活可靠的产品架构是这艘破浪之舰的龙骨。
技术架构上,源启KubeGien容器平台以kubernetes为代表的云原生技术作为基础,为金融、泛金融、能源、电力等行业用户,提供应用管理、集群管理、镜像管理、资源管理等全栈服务,最大化实现云原生的价值。
技术架构采用了分层模块化的设计思路,功能上整个系统由六大部分组成,分别是面向用户的服务门户、提供API接口的API Server、提供核心功能的核心服务、提供辅助功能的扩展服务、采用可插拔模式的服务插件以及提供基本能力的容器底座。

产品功能架构
就像055要能适应各种作战任务一样,源启容器平台为了适应多种业务场景,采用“三群两面”的部署架构(控制节点集群、工作节点集群、存储节点集群 、管理&业务网络平面、存储网络平面),将管理节点进行集群部署并结合多网络平面,提升系统的稳定性。
03 攻坚克难的杀器——产品能力
源启容器平台以“开源、成熟、灵活”为原则,采用主流成熟开源项目+自研增强的方式进行产品研发。在GPU虚拟化、虚拟机负载、安全容器、Pod故障诊断等方面均做了自研和增强。值得一提的是,中电金信源启容器平台团队多人通过CKA认证,同时积极进行开源社区贡献,最近一年提交了10余项开源社区贡献。
源启容器平台KubeGien产品凭借六大能力为用户的云原生转型之路保驾护航。
1. PAAS服务集成——“垂发”、灵活
冷热共架的大型国产垂直导弹发射系统,是055的杀手锏之一,能够在一个垂直发射单元中同时装填多枚导弹,并兼容多种武器系统。那么这种垂直发射、一坑多弹的先进理念能否应用于我们的KubeGien容器平台呢?答案是肯定的。

丰富解耦的服务集成
产品在设计之初没有采用部分友商“全家桶”式的服务绑定模式,而是希望可以通过容器平台产品与其他服务进行灵活的、解耦式的服务集成能力,为用户提供符合自身实际需要的产品能力集合,产品之间均通过标准开放的API接口进行对接,既可整体提供服务,也可以拆分单独提供。
为了丰富破浪之舰的武器库,应对实际执行任务中错综复杂的场景,KubeGien容器平台在业界首次提出云原生适配层概念,向下屏蔽底层平台差异,向上提供云原生适配层货架能力,产品按需适配模块化功能,增强集成产品能力,降低开发成本与复杂度,提升应用交付效率。
2. 异构资源统一管理——“指挥”、统管
055型驱逐舰采用了最新的数字化技术,配备了高性能的指挥和通信系统,能够快速响应指挥部的指令,并精准执行各项任务。源启KubeGien容器平台对异构资源进行统一管理,具备多集群管理能力、随需而动的混合负载、按需分配GPU资源。
统一管理的多云集群
Q :当前金融行业生产环境愈发复杂,通常会部署多个分布于不同数据中心的Kubernetes集群,如何运维?如何监管?如何快速进行应用发放?
A :借助KubeGien容器平台,用户可轻松进行多集群场景下的统一资源管理,通过纳管接入、跨集群调度、自定义策略下发和标准开放接口等核心能力,实现分布式集群的可见、可管、可用。
随需而动的混合负载
Q :对于暂时无法进行容器化改造的虚拟化应用如何处理,或者能否在同一平台对现有虚拟化负载和容器化负载进行统一管理,能不能鱼与熊掌兼得?
A :KubeGien除支持容器类型负载外,还支持虚拟化类型负载,用户可在服务门户上创建虚拟机,并和容器负载一样进行生命周期管理和控制台访问,轻松满足混合负载的需求。
按需分配GPU资源
Q :结合具体使用场景,产品对于算力资源又该如何分配?
A :为了满足用户对高性能计算、视频处理或图形渲染的需求,KubeGien容器平台提供GPU资源给有需求的用户使用,既可以多任务共享使用GPU设备资源,也可以在特定租户及项目内进行GPU资源专用。
3. 灵活分级一云多芯 ——“雷达”、兼容
055型驱逐舰安装了双波段的相控阵雷达,为组织指挥防空反导作战提供了敏锐的“视力”和聪明的“脑力”,防空防导作战能力全面提升。KubeGien容器平台通过灵活分级的资源模型和一云多芯的信创适配能力兼容多种用户场景。
灵活分级的资源模型:KubeGien采用四级资源模型设计,对集群资源进行逐级分解抽象,提供不同粒度的管控能力,每个层级都可以进行资源配额管控,构建了高度灵活的分级资源模型,不论用户自身容器集群规模如何,都可充分对资源进行细粒度的管理。
一云多芯的信创适配:随着信创政策的实施,许多用户存在多种芯片架构服务器混用的场景,KubeGien针对这种情况专门提供一云多芯服务,为用户提供硬件资源异构管理能力,构建不同类型云原生物理资源池,通过上层云原生引擎的兼容性和调度能力,为用户提供满足不同场景所需的资源适配需求。
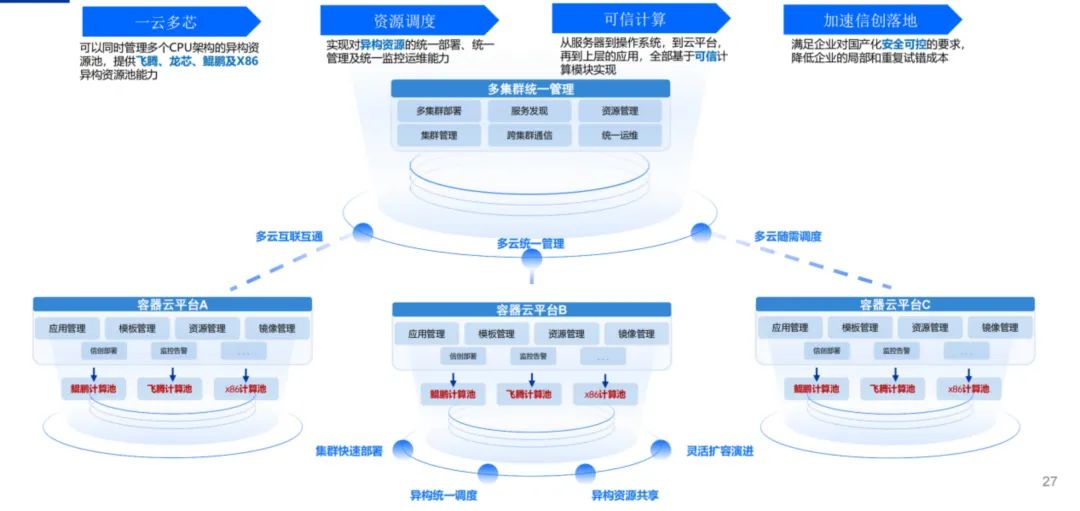
一云多芯的信创适配
4. 智能弹性应用管理 ——“舰炮”、快速
055型驱逐舰装备有种新型武器系统,能够在多个领域发挥重要作用。其中近防炮被网友称之为"土豪炮",每秒能发射166发炮弹,每分钟发射近万枚炮弹。KubeGien容器平台也支持智能弹性的应用管理和业务应用快速上线,方便用户使用。
应用管理弹性伸缩:应用上云后的一大变化就是从以往围绕计算、网络、存储这些资源为重心,转变为以应用生命周期为重心。源启容器平台立足这一点,从应用管理的两个重要支撑技术(应用包管理和应用镜像管理)出发,形成双仓库的管理和基于Helm Chart包的应用生命周期管理能力。用户可以在平台上传和下载应用包和镜像,并支持在分布式集群中对应用进行分发部署。
业务应用快速上线:在破浪之舰的打造过程中,势必会遇到许多大风大浪,首当其冲的就是应对如何上云的巨浪。KubeGien通过屏蔽容器化细节,抽象易变配置,实现自动生成YAML/Chart,并结合DevOps提供一套流水线模板,用户选择该模板后,只需要较少的修改,即可完成所有的配置,从而满足微服务应用快速上线需求,同时开发人员无需掌握太多容器业务知识。
5. 稳定安全容器底座——“近防”、安全
055型驱逐舰的防御能力,主要依赖“两大门神”系统,一个是近防炮,每分钟射速能达到上万发,具备极强的拦截能力;另一个则是 “海红旗”-10近程反导系统,能有效的拦截包括超音速导弹在内的各型导弹。KubeGien容器平台通过可视全面的监控告警、稳定可靠的运行系统等来构筑稳定安全的容器底座。
源启容器平台支持对物理资源、系统核心组件、应用资源进行多维度指标监控和告警通知,用户可以看到系统运行情况,自行定义监控可视化界面,还可以接入面向数据中心级的监控能力体系,提供更大范围、更细粒度的监控能力。
破浪之舰不仅要有犀利的攻击能力,自身也要具备可靠的防护能力,KubeGien容器平台从立项开始就将可靠性放在产品研发的第一位,对系统关键组件和服务均进行了可靠性加固,力求为用户打造一艘经得起惊涛骇浪的稳固之舰。KubeGien容器平台还提供业务故障诊断工具,针对崩溃后异常容器的模拟调试、容器内缺少问题排查命令等场景进行问题定位处理,确保破浪之舰的平稳储蓄运行。
6. 易用灵活服务能力——“操控” 、灵活
为用户提供易用的、灵活可定制的服务门户,通过向导式用户体验,有效降低平台使用难度。
04 坚定探索的实践——产品案例
KubeGien产品诞生以来,不断助力用户云原生转型之路的探索,在一个个项目中解决用户痛点,持续打磨产品,举例两个源启KubeGien产品的应用案例,如需了解项目更多介绍可致电24小时客服400-020-9900,安排专家一对一沟通。
案例1:为某农信银行提供灵活、解耦的服务集成能力
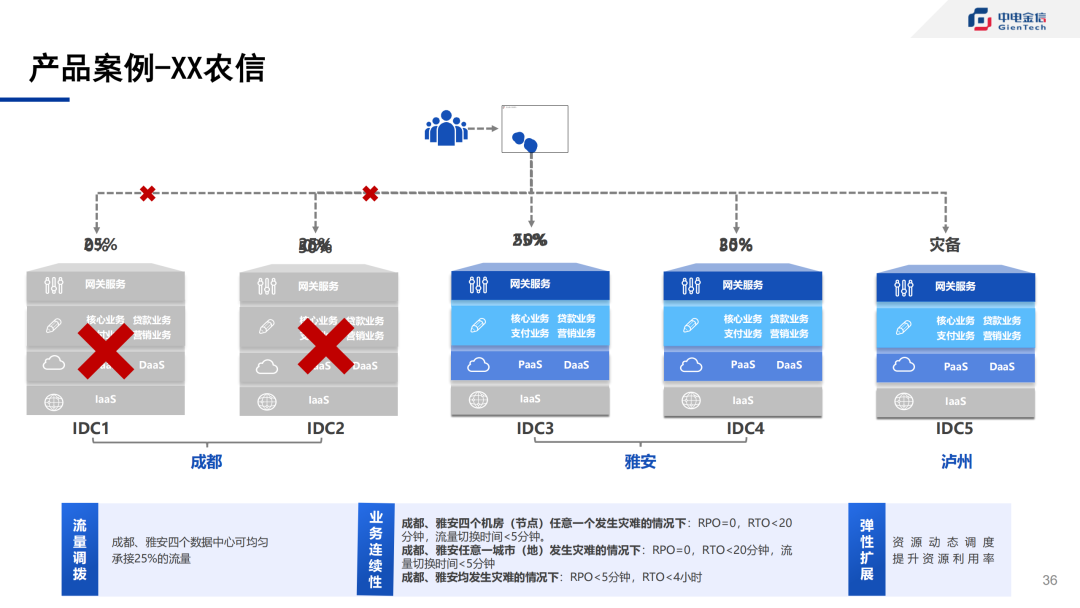
某农信社服务集成项目
针对某农信银行在云原生转型过程中的业务需求,部分厂商以产品全家桶模式提供服务,各层级间服务相互耦合,难以对其他异构容器集群进行兼容。中电金信对服务路由、单元化等能力进行了定制调优,能更好的适配多地多中心场景,并提供多集群统一纳管、跨集群调度部署、跨集群通信等能力,屏蔽了底层不同容器平台厂商的差异,使得上层平台无需感知底层容器底座,避免上层系统与底层平台必须绑定的困境。
案例2:帮助某能建企业解决业务拓展、数据共建等问题
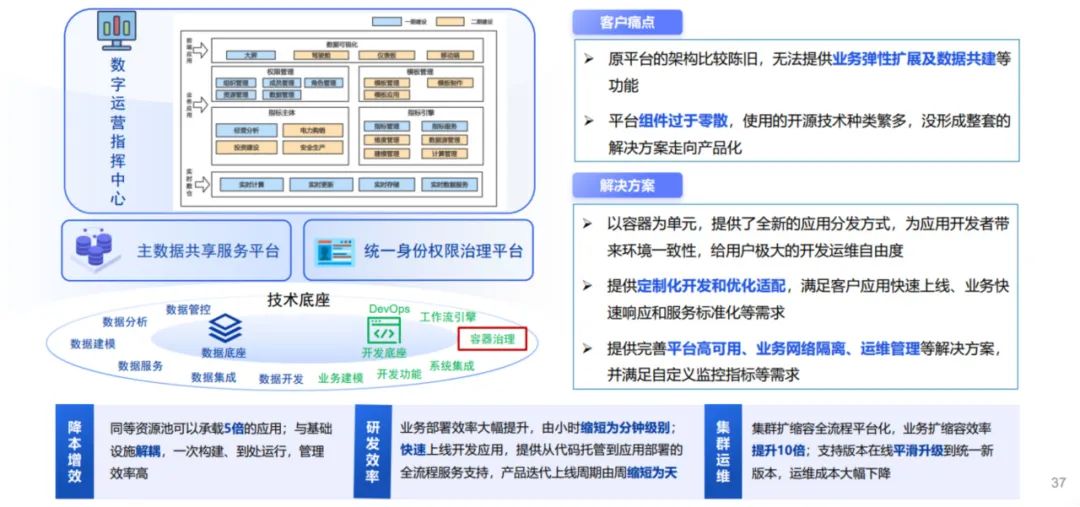
某能建企业项目案例
某能建企业原技术底座平台架构比较陈旧,无法提供业务弹性扩展等功能,平台组件过于零散,使用的开源技术种类繁多,没有形成成套的解决方案。中电金信依托源启体系进行企业数字化转型,提供完善的云原生解决方案,帮助企业构建底数底座平台以及主数据共享平台、统一身份权限治理平台、数字运营指挥中心等(如上图),最终使资源池的应用承载能力提升5倍,业务部署效率由小时缩短为分钟级,同时大幅缩短了产品迭代上线周期,集群运维成本明显下降,推动用户战略目标的达成。