一个网站的构建装修公司电话号码查询
SourceTree
SourceTree链接: https://pan.baidu.com/s/1oqPxhpHeNOOiuRRQydes6g?pwd=ngru
提取码: ngru

点击Generate


分别保存私钥和公钥

gitee官网注册


这是gitee的公钥,与上面SourceTree的公钥私钥不一样

gitee生成公钥,确保本地安装好git
git链接: https://pan.baidu.com/s/1N3niCSTcQ-Yj_rbo85u1cA?pwd=8m54
提取码: 8m54



打开上图中的公钥,复制在下框中

gitee登录时候,自己设置密码



复制的是刚刚SourceTree生成的私钥

Addkey之后,点击close关掉

回到idea,设置好git菜单






IDEA 新版本——顶部菜单消失解决办法-CSDN博客
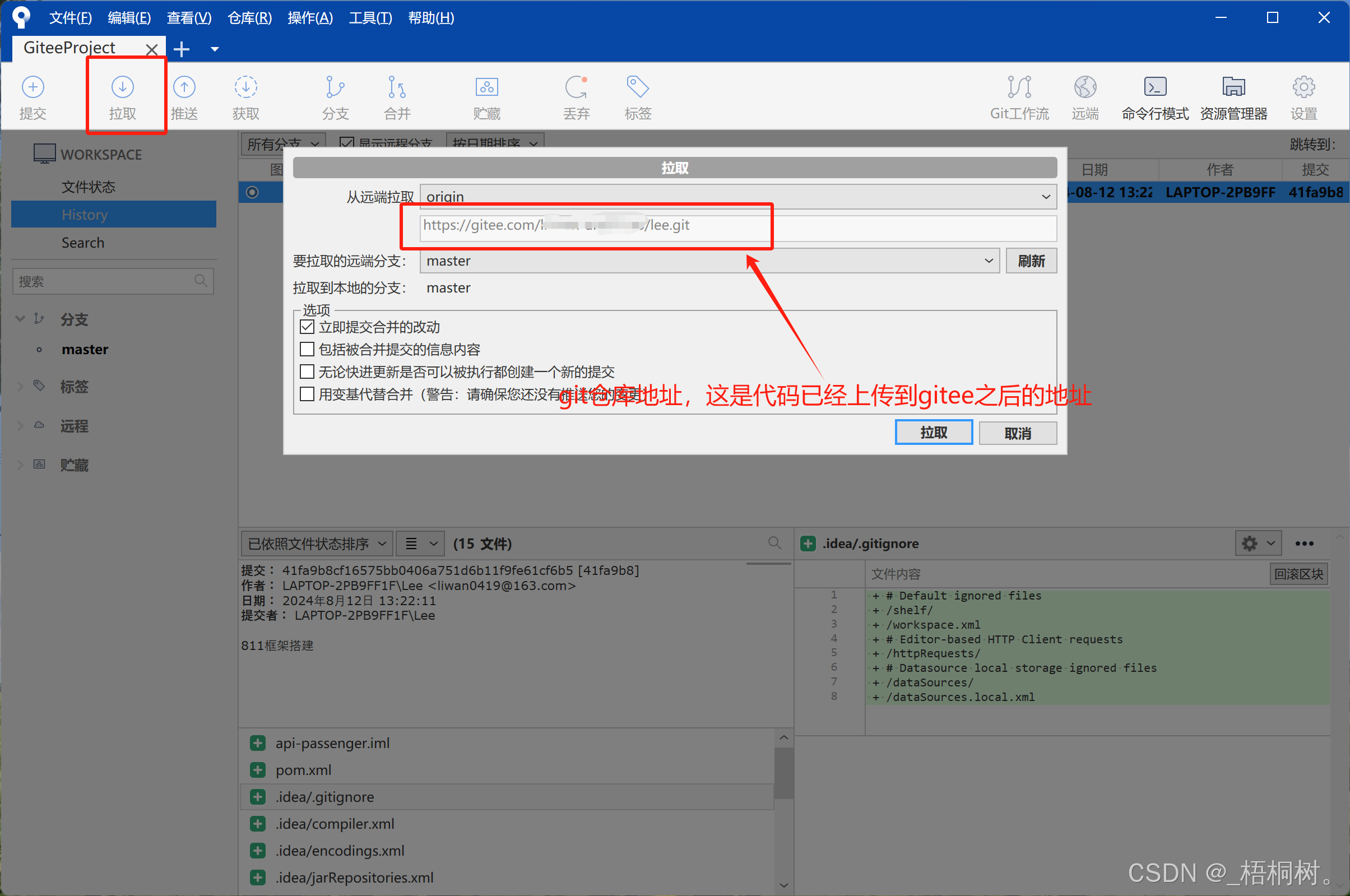
idea代码提交到gitee

复制好gitee的连接

把链接放在idea中


gitee的账号密码,电话号码和自己设置的密码

gitee上查看刚刚提交好的项目代码


查看地址这样



点开SourceTree复制gitee的链接