买域名建网站价格关于销售网站建设的短文
不知道什么时候Chrome自动升级到116.0.5845.188了,害得我原来的Chromedriver 114无法使用了,无奈之下只好重新去下载。
可寻遍网络,都没找到Chromedriver116的版本。网上大多网友给的下载网址是chromedriver.storage.googleapis.com/index.html,这个网址对于Chromedriver 114版及以前版本而言相当全,各个版本几乎都能找到,然而LATEST_RELEASE_114之后,再无新版放出。
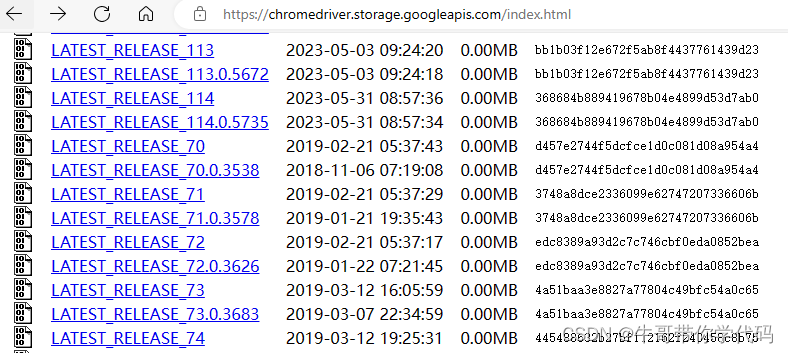
感觉Chrome好歹是Google的产品,这种大公司应该不会不管Chrome114以后版本的测试了吧,于是通过科学上网用Google找答案。果然被我找到了,网址如下:Announcing upcoming changes to the ChromeDriver release process (google.com),说的也很明白:After the M114 release, we’re making some changes to fully integrate ChromeDriver into the Chrome release process。发布时间是2023年5月16日,也就是说2023年5月16号以后,人家就不在https://chromedriver.storage.googleapis.com/index.html这里发布新版的Chromedriver了,以后每个新版Chrome发布时,都会共同发布Chromedriver,这倒是挺好的,省的再去对版本了。

可在哪儿下载呢,看到看到给出网址,赶紧下载。谁想版本又太新了,看来是这个页面只发布最新版本的chrome。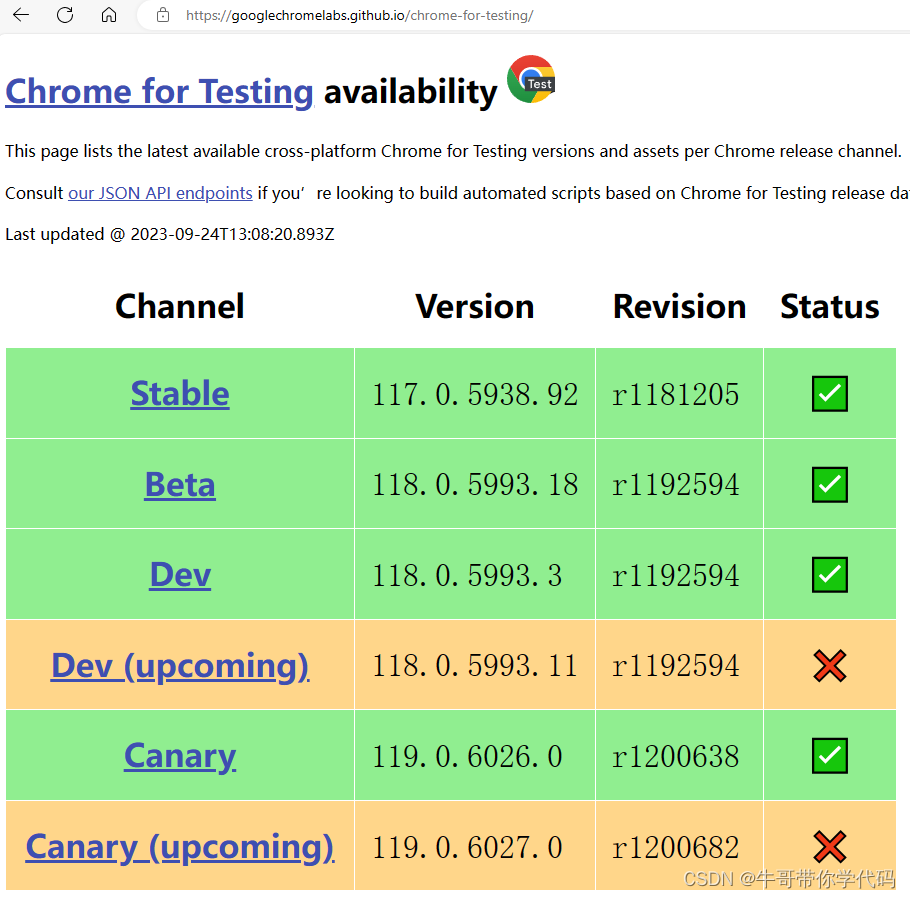
在这个网址可以看到,chromedriver的确是被作为Chrome的一部分,作为整体一起进行了发布,这对于经常使用chromedriver的测试人员来说是个好消息。
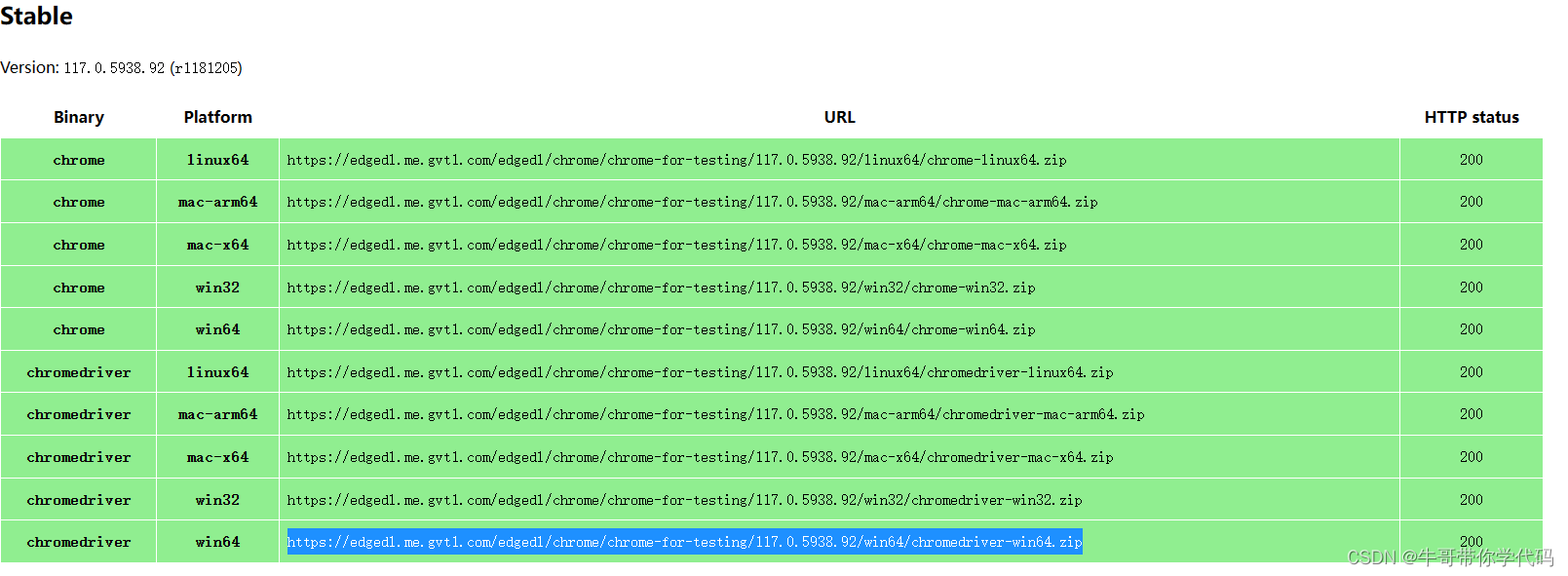
不管说的再好,还是不全,还是没找到Chromedriver 116在哪下载。
不过,从上面的网址来看,中间数字部分是Chrome的版本号,根据他们的说法,让查询其EndPoint,感觉象是以最终版本号作为终版,进行发布提供下载,随即进行了测试。先试115。
点进来,看看,哈已知的好版本。
 115版的最初版本是115.0.5790.3,如果是使用终版(115.0.5790.170)的话,这个版本应该不能下载了。
115版的最初版本是115.0.5790.3,如果是使用终版(115.0.5790.170)的话,这个版本应该不能下载了。
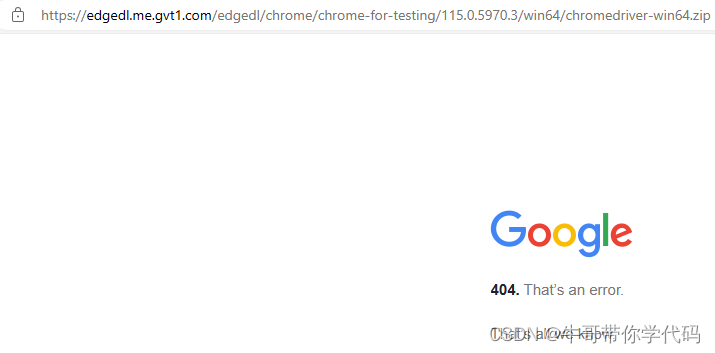
果然如此。再试下115.0.5790.170,下载成功。

解压,看一下版本号。

版本测试也没问题,就是115.0.5790.170。
我的Chrome版本是116.0.5845.188,可是known-good-vision里只有116.0.5845.96,只能用它试了。
 把前面下载网址中的版本号
把前面下载网址中的版本号
换成116.0.5845.96,下载成功,解压测试版本没问题,实测Chromedriver16.0.5845.96驱动Chrome116.0.5845.188无任何问题。

如果有兴趣,完全可以利用谷歌提供的known-good-versions.json结合下载网址,做一个软件根据chrome版本自动下载driver,不过只是查找和复制粘贴的事,就不费这劲了。
如果文章有不当之处或错误,希望大家能告诉我。如果各位大佬有其他好办法,也请不吝指点。