做招聘网站做服务器多少钱ftp怎么做网站
概要
代码编译过程中,为了防止同一份代码被重复引用,通常有两种实现方式
方式一
#pragma once
方式二
#ifndef _TEST_H_
#define _TEST_H_
#endif // !TEST_H
通常情况下,使用上述两种方式中的任意一种都是可以的。最近工作中,代码按照其功能性被划分出不同的模块,这时二者的区别就体现出来了。
模块依赖图
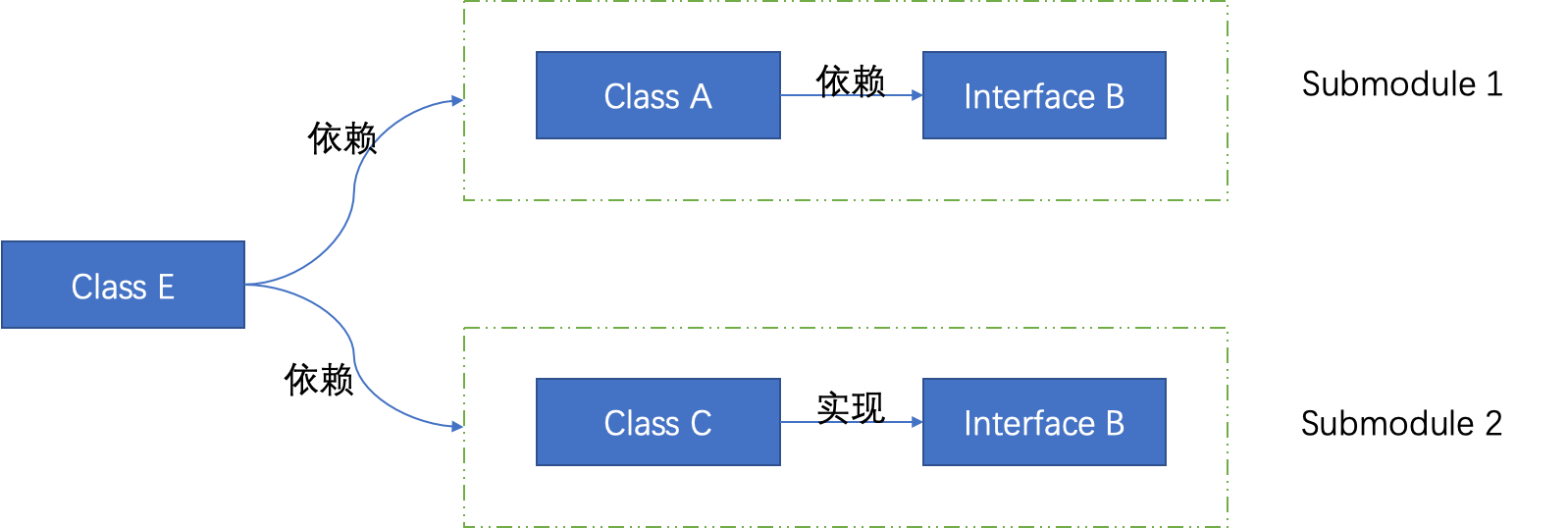
- Submodule1和submodule2是两个独立的模块,相互见不可见
- 两个模块均存在同一个接口文件(Interface B)
- Class E同时依赖Submodule1和submodule2
实验
如果在Interface B文件中,使用pragma once,在编译环节会有如下的报错:
error: redefinition of 'XXX' // Interface B文件中实现的一个数据结构
struct XXX{
但是使用ifndef不会报错,且代码运行符合预期。
区别
pragma once只是保证同一个文件不会被引用两次,但是对于不同的文件(即时文件名和内部实现完全一致),该语法是不生效的。
Ifndef其实是定义一个宏,即时在不同的文件中出现相同的宏名,它也有排他性。
链接的问题
由于submodule1和submodule2是分开编译的,因此编译出的静态库文件均包含了类xxx的实现。在编译外部的可执行目标class E的过程中,无疑它也包含了类xxx的实现。当这三部分进行链接时,肯定是存在重复的部分的。与编译器不同的是,链接器它能通过symbol的名称进行排重(只会选取一个),因此不再报错。
参考文献
- C++学习笔记之pragma once的理解_pragma once什么意思-CSDN博客
- https://www.cnblogs.com/math/p/how_to_resolve_multi_define_symbols.html