网站 提示建设中淘宝网站网页图片怎么做的


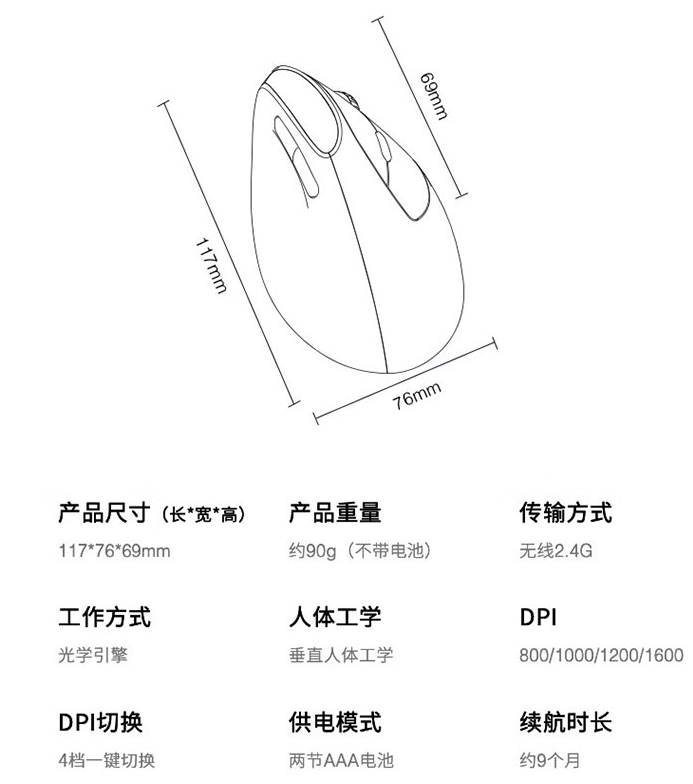
用了1年多,第一次用竖着的鼠标,现在已经很习惯了,感觉还不错。说说使用感受:
1、 仍然是长时间使用鼠标,但是很少出现手腕痛的情况,确实是有一定效果的。
2、使用场景是有限制的,我是配合笔记本使用,在办公室还好,桌面很宽敞,能把整个小臂放在桌面上,正常使用起来没什么问题,但是,如果是在出差,或者在桌面很小的条件下,只能用普通鼠标的使用方式来使用这个鼠标,比较难受
3、偶尔会出现卡顿,指示灯闪烁,但是无法使用,需要重启。
4、换一次电池能使用好几个月,还是很耐用的,但是电池电量会出现卡顿等情况
5、不用鼠标垫,在大多数平面上用起来还算顺畅