如何建设一免费的网站万网怎么上传网站
文章目录
- 设计模式的 6 大设计原则
- 设计模式的三大分类
- 常见的设计模式有哪几种
- 1. 单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点。(连接池)
- 1. 饿汉式
- 2. 懒汉式
- 3. 双重检测
- 2. 工厂模式
- 3. 观察者模式
- ● 推模型
- ● 拉模型
- 4. 装饰模式
- 5. 建造者模式
- 6. 代理模式
- 7. 策略模式
设计模式的 6 大设计原则
- 单一职责原则:就一个类而言,应该仅有一个引起它变化的原因。
- 开放封闭原则:软件实体可以扩展,但是不可修改。即面对需求,对程序的改动可以通过增加代码来完成,但是不能改动现有的代码。
- 里氏代换原则:一个软件实体如果使用的是一个基类,那么一定适用于其派生类。即在软件中,把基类替换成派生类,程序的行为没有变化。
- 依赖倒转原则:抽象不应该依赖细节,细节应该依赖抽象。即针对接口编程,不要针对实现编程。
- 迪米特原则:如果两个类不直接通信,那么这两个类就不应当发生直接的相互作用。如果一个类需要调用另一个类的某个方法的话,可以通过第三个类转发这个调用。
- 接口隔离原则:每个接口中不存在派生类用不到却必须实现的方法,如果不然,就要将接口拆分,使用多个隔离的接口。
设计模式的三大分类
- 创造型模式:单例模式、工厂模式、建造者模式、原型模式 (4)
- 结构型模式:适配器模式、桥接模式、外观模式、组合模式、装饰模式、享元模式、代理模式 (7)
- 行为型模式:责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式、访问者模式 (12)
注意:简单工厂模式 违背了六大原则中的开发-封闭原则,故而不属于23种GOF设计模式之一 也叫静态工厂方法模式
常见的设计模式有哪几种
1. 单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点。(连接池)
单例模式的实现需要三个必要的条件:
- 单例类的构造函数必须是私有的,这样才能将类的创建权控制在类的内部,从而使得类的外部不能创建类的实例。
- 单例类通过一个私有的静态变量来存储其唯一实例。
- 单例类通过提供一个公开的静态方法,使得外部使用者可以访问类的唯一实例。
另外,实现单例类时,还需要考虑三个问题:
- 创建单例对象时,是否线程安全。
- 单例对象的创建,是否延时加载。
- 获取单例对象时,是否需要加锁(锁会导致低性能)。
下面介绍五种实现单例模式的方式。
1. 饿汉式
饿汉式的单例实现比较简单,其在类加载的时候,静态实例 instance 就已创建并初始化好了。
public class Singleton { private static final Singleton instance = new Singleton();private Singleton () {}public static Singleton getInstance() {return instance;}
}饿汉式单例优缺点:
- 优点:
- 单例对象的创建是线程安全的;
- 获取单例对象时不需要加锁。
- 缺点:单例对象的创建,不是延时加载。
一般认为延时加载可以节省内存资源。但是延时加载是不是真正的好,要看实际的应用场景,而不一定所有的应用场景都需要延时加载。
2. 懒汉式
与饿汉式对应的是懒汉式,懒汉式为了支持延时加载,将对象的创建延迟到了获取对象的时候,但为了线程安全,不得不为获取对象的操作加锁,这就导致了低性能。
public class Singleton { private static final Singleton instance;private Singleton () {}public static synchronized Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; }
}懒汉式单例优缺点:
- 优点:
- 对象的创建是线程安全的。
- 支持延时加载。
- 缺点:获取对象的操作被加上了锁,影响了并发度。
- 如果单例对象需要频繁使用,那这个缺点就是无法接受的。
- 如果单例对象不需要频繁使用,那这个缺点也无伤大雅。
3. 双重检测
饿汉式和懒汉式的单例都有缺点,双重检测的实现方式解决了这两者的缺点。
双重检测将懒汉式中的 synchronized 方法改成了 synchronized 代码块。
public class Singleton { private static Singleton instance;private Singleton () {}public static Singleton getInstance() {if (instance == null) {synchronized(Singleton.class) { // 注意这里是类级别的锁if (instance == null) { // 这里的检测避免多线程并发时多次创建对象instance = new Singleton();}}}return instance;}
}双重检测单例优点:
- 对象的创建是线程安全的。
- 支持延时加载。
- 获取对象时不需要加锁。
2. 工厂模式
包括简单工厂模式、抽象工厂模式、工厂方法模式
- 简单工厂模式:主要用于创建对象。用一个工厂来根据输入的条件产生不同的类,然后根据不同类的虚函数得到不同的结果。
public class SimpleFactory {public static Product createProduct(String type) {if (type.equals("A")) {return new ProductA();} else if (type.equals("B")) {return new ProductB();} else {return null;}}
}public interface Product {void use();
}public class ProductA implements Product {@Overridepublic void use() {System.out.println("Using Product A");}
}public class ProductB implements Product {@Overridepublic void use() {System.out.println("Using Product B");}
}b. 工厂方法模式:修正了简单工厂模式中不遵守开放封闭原则。把选择判断移到了客户端去实现,如果想添加新功能就不用修改原来的类,直接修改客户端即可。
public interface Factory {Product createProduct();
}public class ProductAFactory implements Factory {@Overridepublic Product createProduct() {return new ProductA();}
}public class ProductBFactory implements Factory {@Overridepublic Product createProduct() {return new ProductB();}
}
c. 抽象工厂模式:定义了一个创建一系列相关或相互依赖的接口,而无需指定他们的具体类。
public interface AbstractFactory {Product createProductA();Product createProductB();
}---public class AbstractProductFactory implements AbstractFactory {@Overridepublic Product createProductA() {return new ProductAFactory().createProduct();}@Overridepublic Product createProductB() {return new ProductBFactory().createProduct();}
}
public class Client {public static void main(String[] args) {AbstractFactory factory = new AbstractProductFactory();Product productA = factory.createProductA();Product productB = factory.createProductB();productA.use();productB.use();}
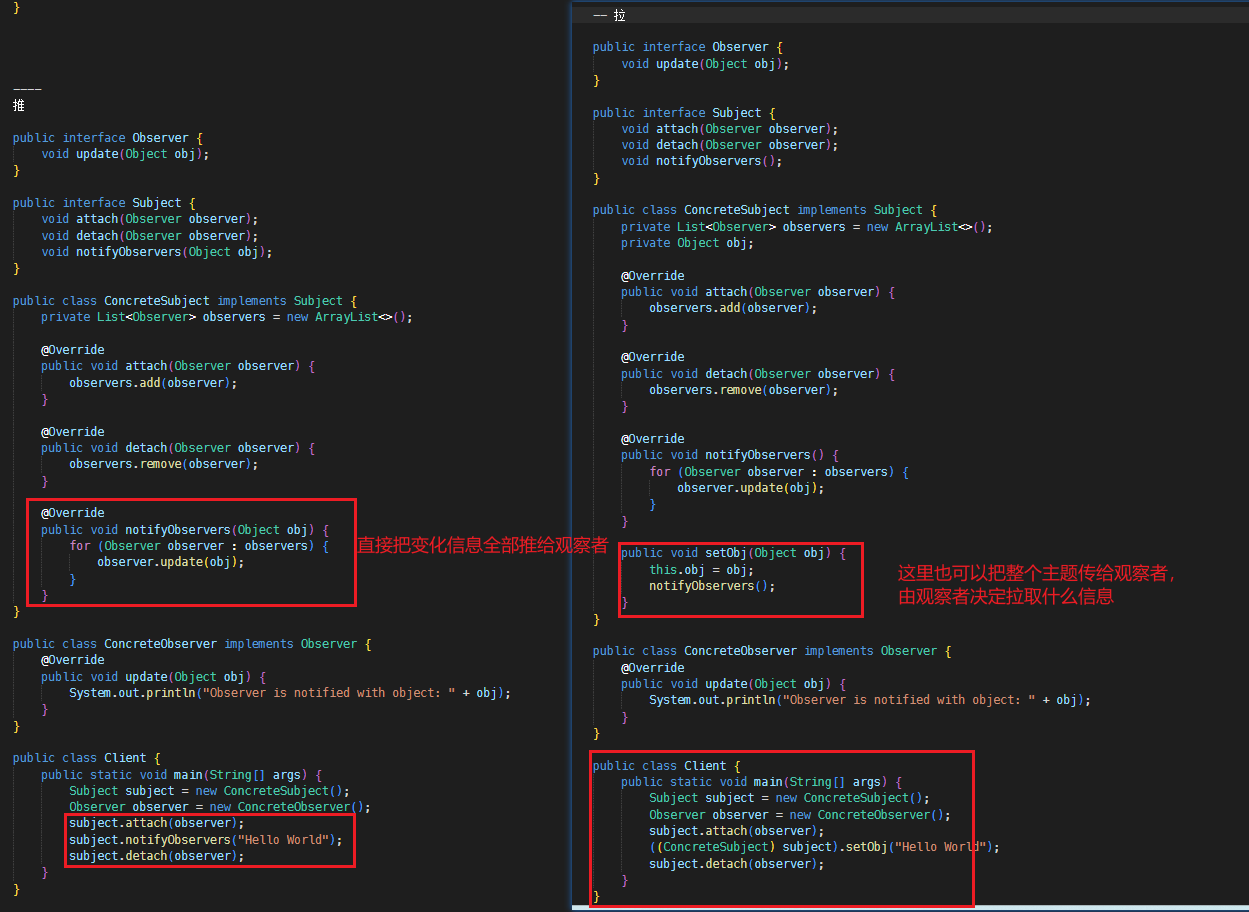
}3. 观察者模式
定义了一种一对多的关系,让多个观察对象同时监听一个主题对象,主题对象发生变化时,会通知所有的观察者,使他们能够更新自己。(微信朋友圈动态通知、消息通知、邮件通知、广播通知、桌面程序的事件响应)
在观察者模式中,又分为推模型和拉模型两种方式。
● 推模型
主题对象向观察者推送主题的详细信息,不管观察者是否需要,推送的信息通常是主题对象的全部或部分数据。
● 拉模型
主题对象在通知观察者的时候,只传递少量信息。如果观察者需要更具体的信息,由观察者主动到主题对象中获取,相当于是观察者从主题对象中拉数据。一般这种模型的实现中,会把主题对象自身通过update()方法传递给观察者,这样在观察者需要获取数据的时候,就可以通过这个引用来获取了。
4. 装饰模式
动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成派生类更为灵活。(输入输出流)
文件流 -> 输入输出流 -> 缓冲池流 (层层包装,扩展功能)
BufferedReader in1 = new BufferedReader(new InputStreamReader(new FileInputStream(file)));//字符流DataInputStream in2 = new DataInputStream(new BufferedInputStream(new FileInputStream(file)));//字节流// DataInputStream-从数据流读取字节,并将它们装换为正确的基本类型值或字符串// BufferedInputStream-可以通过减少读写次数来提高输入和输出的速度
5. 建造者模式
建造者模式的目的是为了分离对象的属性与创建过程。
建造者模式是构造方法的一种替代方案,为什么需要建造者模式,我们可以想,假设有一个对象里面有20个属性:
● 属性1
● 属性2
● ...
● 属性20
对开发者来说这不是疯了,也就是说我要去使用这个对象,我得去了解每个属性的含义,然后在构造函数或者Setter中一个一个去指定。更加复杂的场景是,这些属性之间是有关联的,比如属性1=A,那么属性2只能等于B/C/D,这样对于开发者来说更是增加了学习成本,开源产品这样的一个对象相信不会有太多开发者去使用。
为了解决以上的痛点,建造者模式应运而生,对象中属性多,但是通常重要的只有几个,因此建造者模式会让开发者指定一些比较重要的属性或者让开发者指定某几个对象类型,然后让建造者去实现复杂的构建对象的过程,这就是对象的属性与创建分离。这样对于开发者而言隐藏了复杂的对象构建细节,降低了学习成本,同时提升了代码的可复用性。
@Data
public class CarBuilder {// 车型private String type;// 动力private String power;public Car build() {Assert.assertNotNull(type);Assert.assertNotNull(power);return new Car(this);}public CarBuilder type(String type) {this.type = type;return this;}public CarBuilder power(String power) {this.power = power;return this;}}
@Test
public void test() {Car car = new CarBuilder().power("动力一般").type("紧凑型车").build();System.out.println(JSON.toJSONString(car));
}
6. 代理模式
- 优点:代理可以协调调用方与被调用方,降低了系统的耦合度。根据代理类型和场景的不同,可以起到控制安全性、减小系统开销等作用。
- 缺点:增加了一层代理处理,增加了系统的复杂度,同时可能会降低系统的相应速度。
Aop 就是使用代理模式来实现的。
public interface Subject {void request();
}public class RealSubject implements Subject {@Overridepublic void request() {System.out.println("RealSubject handles the request");}
}---public class Proxy implements Subject {private RealSubject realSubject;@Overridepublic void request() {if (realSubject == null) {realSubject = new RealSubject();}System.out.println("Proxy handles the request");// before aoprealSubject.request();// post aop}
}public class Client {public static void main(String[] args) {Proxy proxy = new Proxy();proxy.request();}
}7. 策略模式
优缺点
- 优点:策略模式提供了对“开闭原则”的完美支持,用户可以在不修改原有系统的基础上选择算法或行为。干掉复杂难看的if-else。
- 缺点:调用时,必须提前知道都有哪些策略模式类,才能自行决定当前场景该使用何种策略。
public interface Strategy {void execute();
}public class ConcreteStrategyA implements Strategy {@Overridepublic void execute() {System.out.println("Executing strategy A");}
}public class ConcreteStrategyB implements Strategy {@Overridepublic void execute() {System.out.println("Executing strategy B");}
}public class Context {private Strategy strategy;public Context(Strategy strategy) {this.strategy = strategy;}public void executeStrategy() {strategy.execute();}
}public class Client {public static void main(String[] args) {Strategy strategyA = new ConcreteStrategyA();Strategy strategyB = new ConcreteStrategyB();Context context = new Context(strategyA);context.executeStrategy();context = new Context(strategyB);context.executeStrategy();}
}