如何做电影网站资源新乡做网站
训练网站:泓江科技 (lessonplan.cn) https://laiye.lessonplan.cn/list/ec0f5080-e1de-11ee-a1d8-3f479df4d981(本博客中会有部分课程ppt截屏,如有侵权请及请及时与小北我取得联系~)
https://laiye.lessonplan.cn/list/ec0f5080-e1de-11ee-a1d8-3f479df4d981(本博客中会有部分课程ppt截屏,如有侵权请及请及时与小北我取得联系~)
紧接着小北之前的几篇博客,友友们我们即将开展新课的学习~
单元1
第1天 RPA基础语法
本章主要介绍UiBot Creator的安装、注册及扩展程序的安装、流程的基本概念.UiBot Creator流程图界面与编辑器界面的使用、UiBot工程目录结构。RPA基础概念:变量与数据类型、运算符与表达式、基本语法:包括分支结构、循环结构、数学操作、数组与字典、字符串操作等。
一、相关材料链接:
【免费】Uibot(RPA设计软件)培训前期准备指南-课前材料资源-CSDN文库https://download.csdn.net/download/Zhiyilang/88695809?spm=1001.2014.3001.5501https://download.csdn.net/download/Zhiyilang/88695809?spm=1001.2014.3001.5501https://download.csdn.net/download/Zhiyilang/88695809?spm=1001.2014.3001.5501https://download.csdn.net/download/Zhiyilang/88695809?spm=1001.2014.3001.5501https://download.csdn.net/download/Zhiyilang/88695809?spm=1001.2014.3001.5501![]() https://download.csdn.net/download/Zhiyilang/88695809?spm=1001.2014.3001.5501
https://download.csdn.net/download/Zhiyilang/88695809?spm=1001.2014.3001.5501
温馨提示:在接下来的学习过程中,大家请不要升级UiBot6.0.0,自动忽略升级~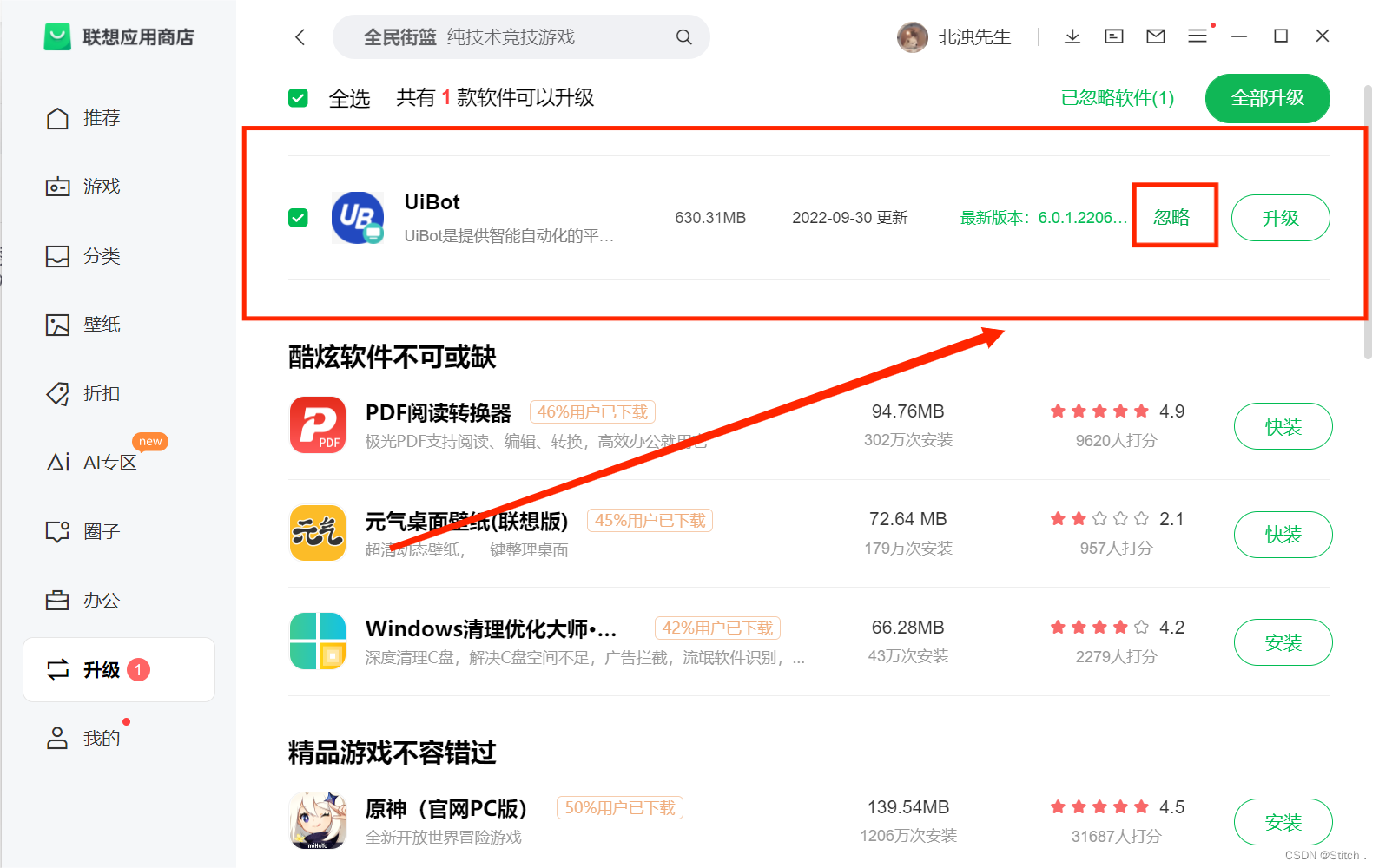
二、视频展示:Uibot (RPA设计软件)微信群发助手机器人————课前材料二_uibot 怎么启动微信-CSDN博客https://blog.csdn.net/Zhiyilang/article/details/135453437?spm=1001.2014.3001.5501
UiBot微信消息轰炸
RPA微信群发助手机器人
Uibot (RPA设计软件)网页表单填写————课前材料三_uibot 列表 输入 选择-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/135487069?spm=1001.2014.3001.5501
https://blog.csdn.net/Zhiyilang/article/details/135487069?spm=1001.2014.3001.5501
UiBot (RPA设计软件)网页表单填写整体过程展示
Uibot (RPA设计软件)股票板块行情抓取————课前材料四_uibot 股票-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/135587294?spm=1001.2014.3001.5501
https://blog.csdn.net/Zhiyilang/article/details/135587294?spm=1001.2014.3001.5501
UiBot RPA设计软件 股票板块行情抓取
RPAUiBot 股票板块行情抓取拓展(每日)
Uibot (RPA设计软件)Mage AI智能识别(发票识别)———课前材料五_mage ai uibot-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/135591297?spm=1001.2014.3001.5501
https://blog.csdn.net/Zhiyilang/article/details/135591297?spm=1001.2014.3001.5501
UiBot (RPA)Mage AI智能识别——发票识别
Uibot (RPA设计软件)智能识别信息+微信群发助手(升级版)———课后练习1_uibot 微信消息推送-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/135970224?spm=1001.2014.3001.5501
https://blog.csdn.net/Zhiyilang/article/details/135970224?spm=1001.2014.3001.5501
Uibot (RPA设计软件)智能识别信息+微信群发助手(升级版)———课后练习2-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/136200438?spm=1001.2014.3001.5501
https://blog.csdn.net/Zhiyilang/article/details/136200438?spm=1001.2014.3001.5501
UiBot6.0校网更新提示助手(初版成功)
Uibot (RPA设计软件)财务会计Web应用自动化(批量开票机器人)-CSDN博客![]() https://blog.csdn.net/Zhiyilang/article/details/136782171?spm=1001.2014.3001.5501
https://blog.csdn.net/Zhiyilang/article/details/136782171?spm=1001.2014.3001.5501
RPA-财务会计Web应用自动化(批量开票机器人)
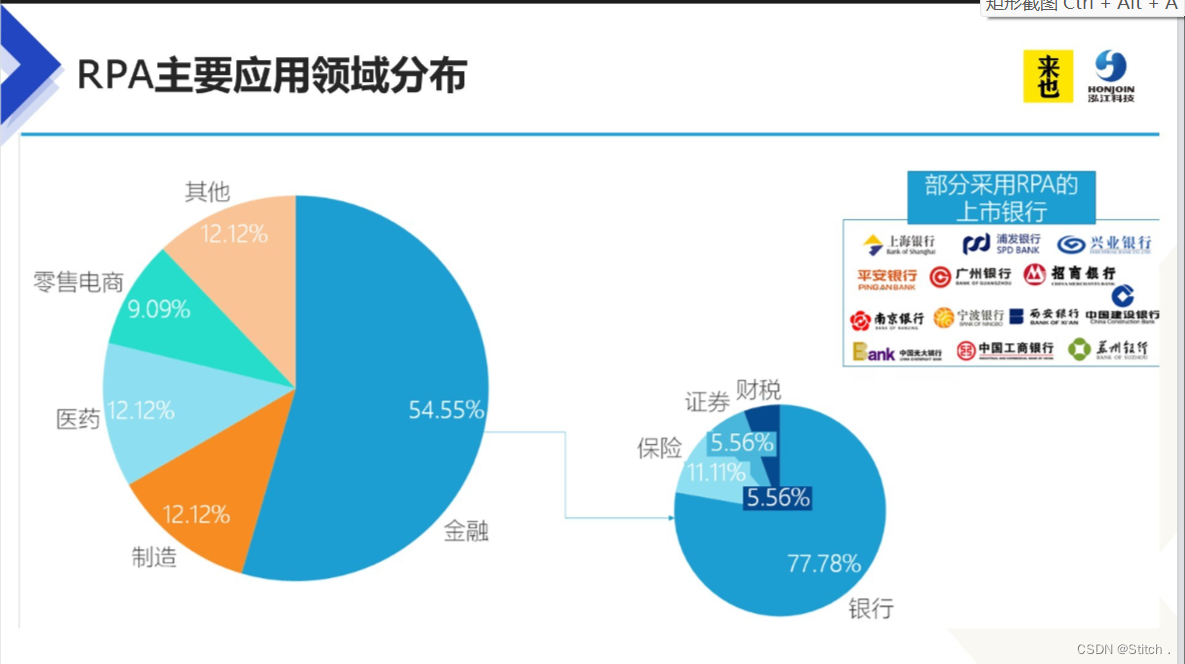
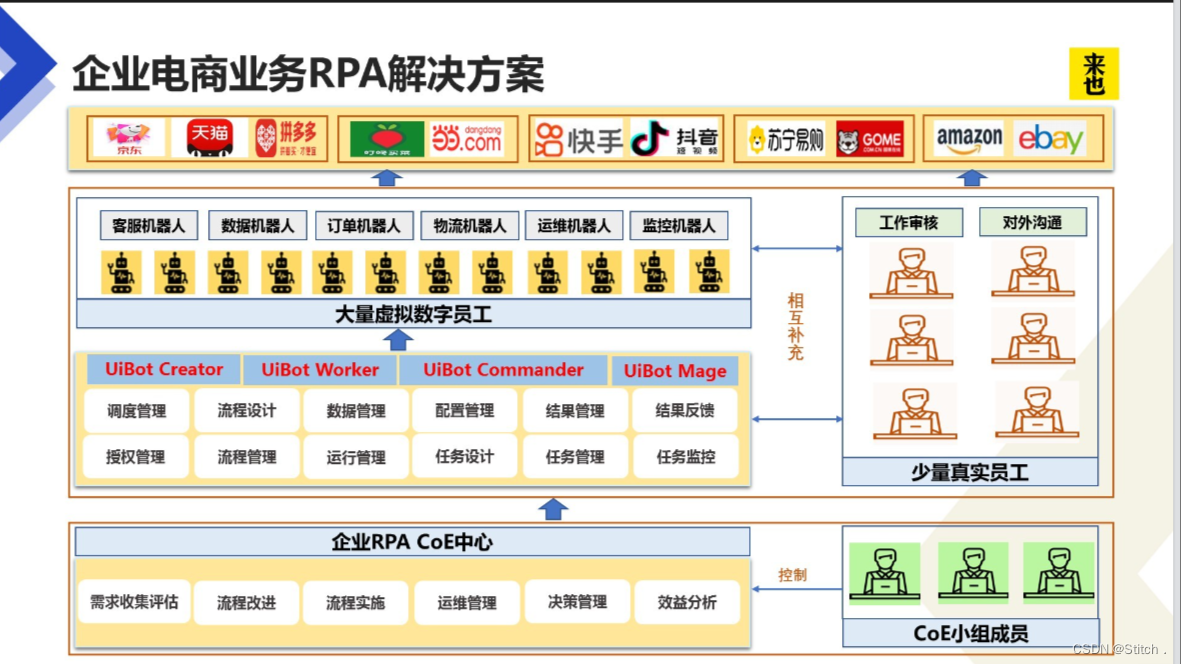
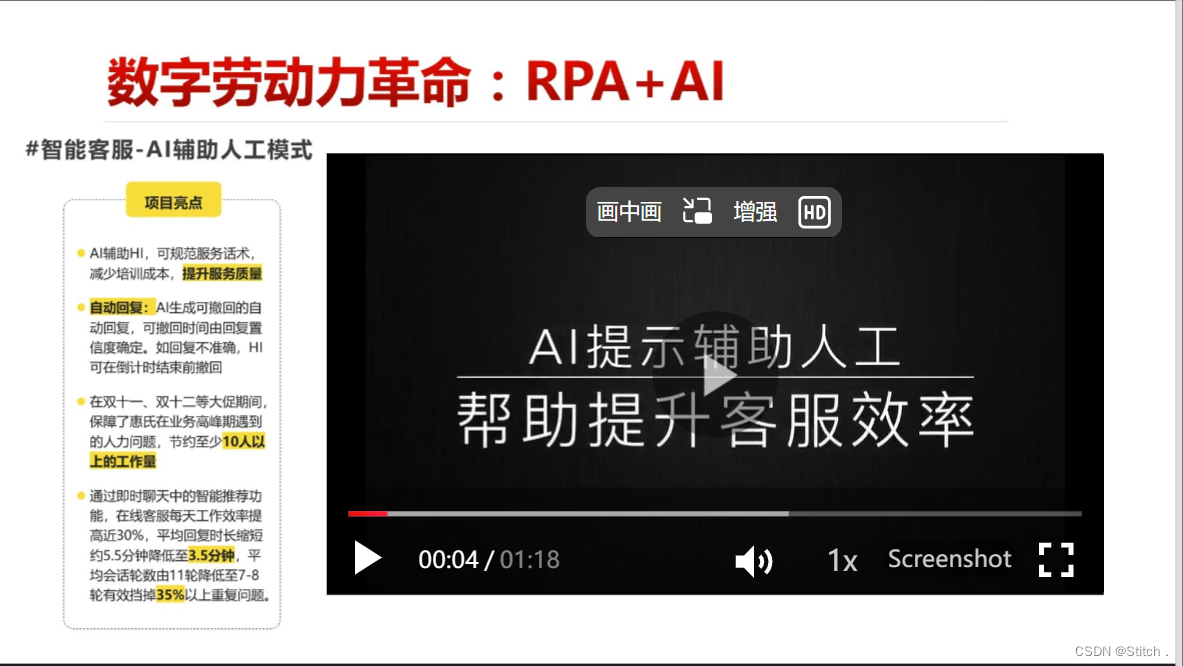
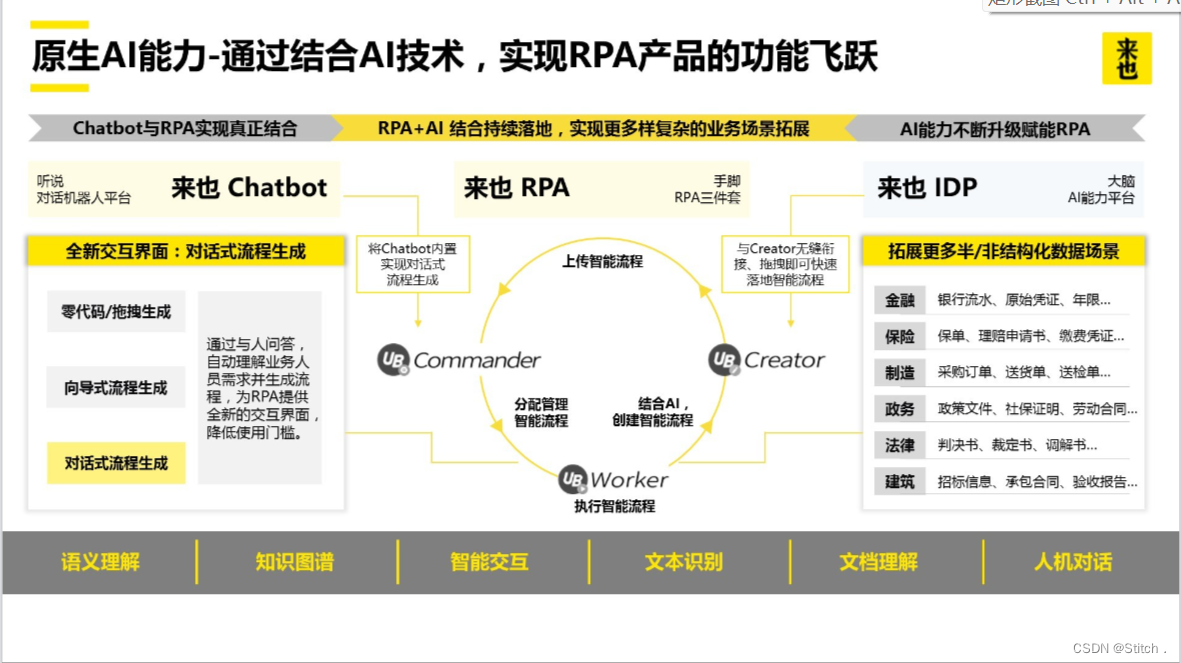
三、RPA+AI








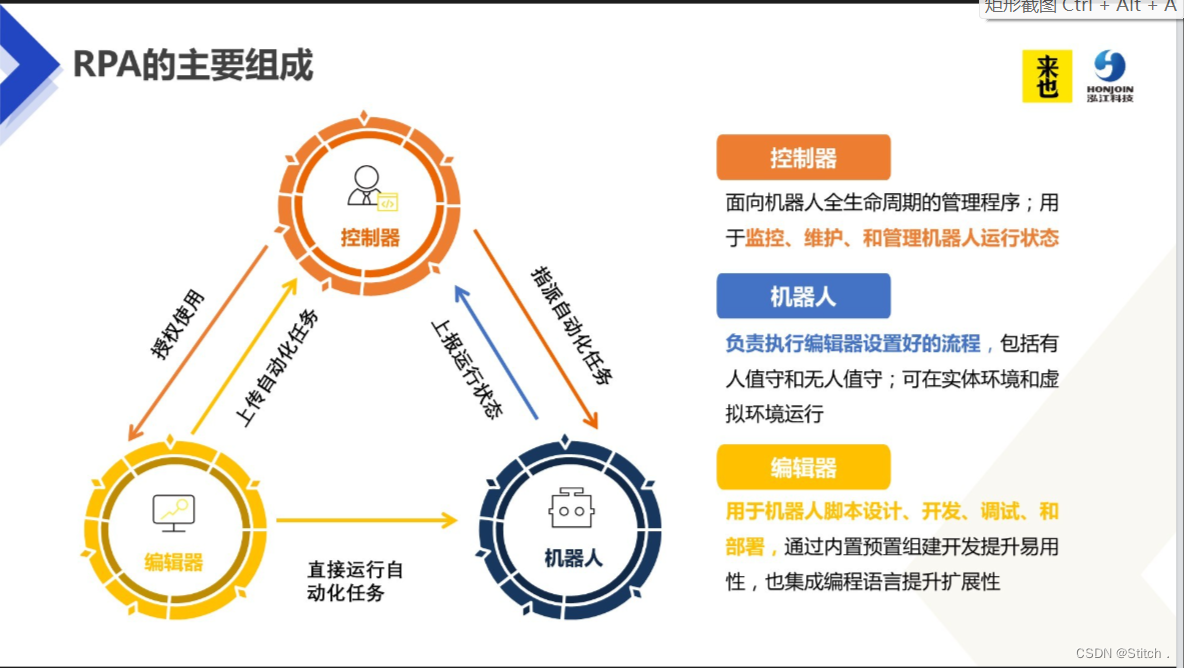

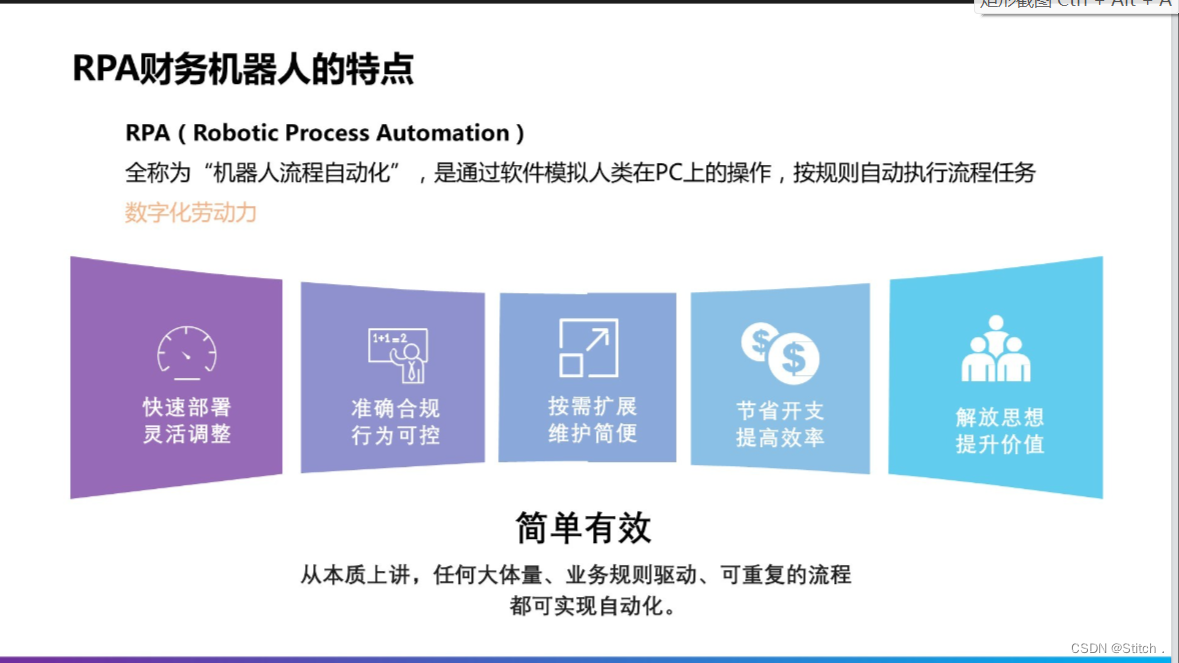










四、基础讲解








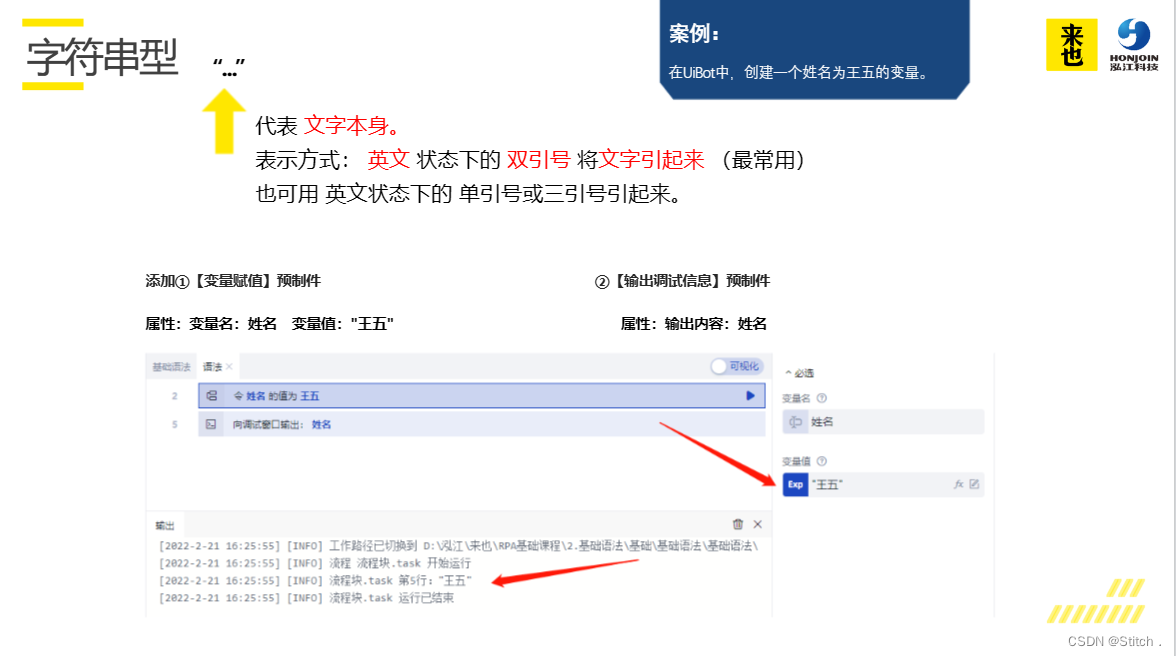






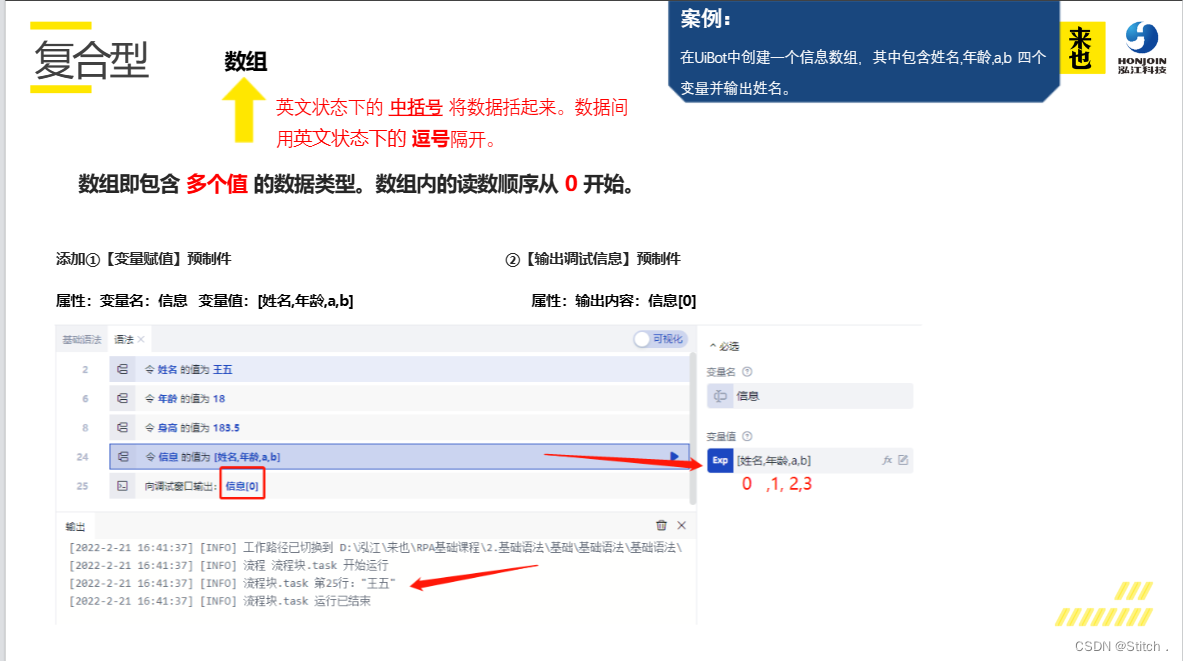









五、课后习题
课堂练习: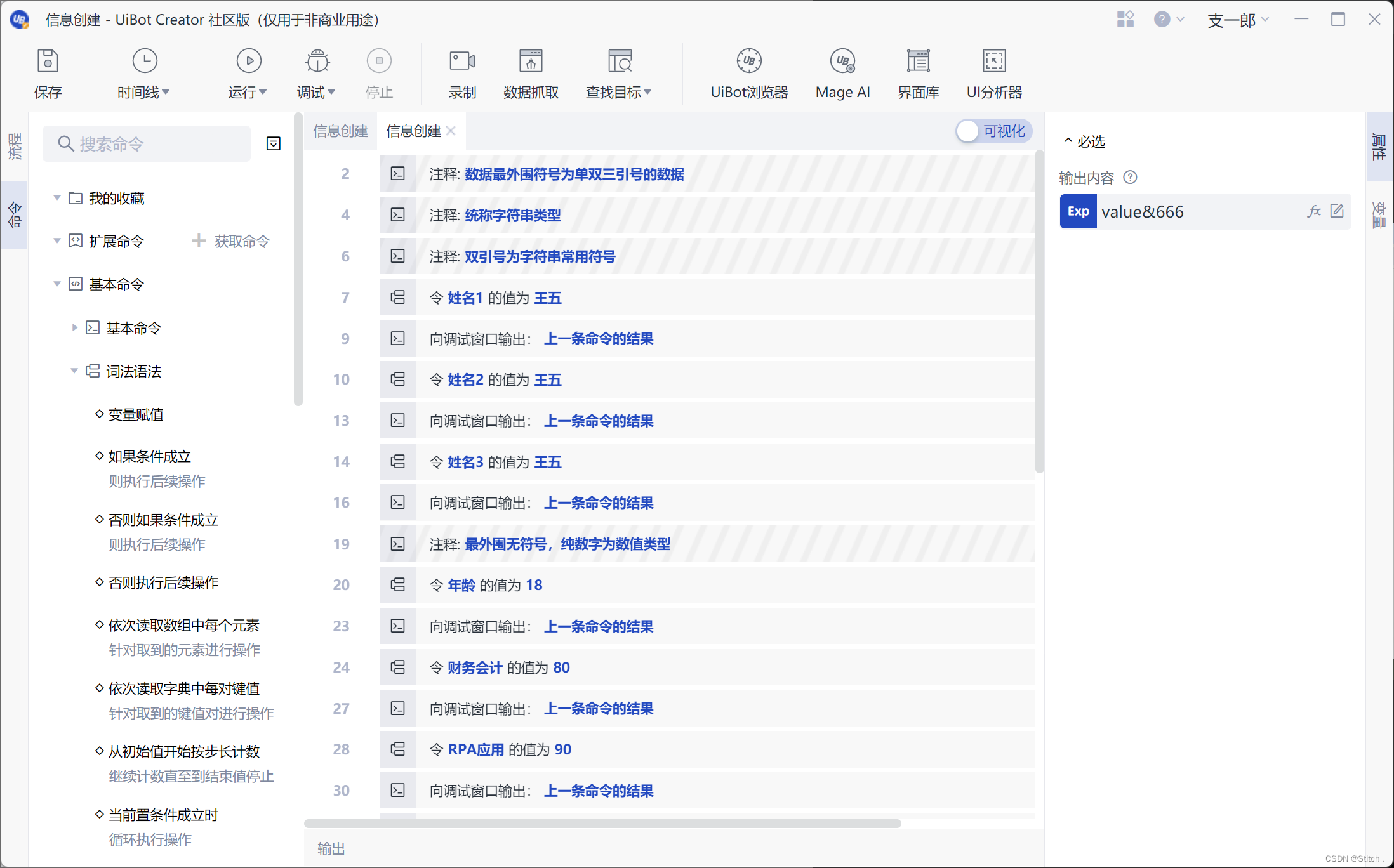




UiBot基本语法练习题
一、判断题
1、
字符串数据可以使用英文状态下的双引号、单引号或三引号中的任一种表示
A、正确/TrueB、错误/False
2、
在UiBot中计次循环【从初始值开始按步长计数】命令的属性<初始值>从0开始
A、正确/TrueB、错误/False
二、单项选择题
1、
已知变量:信息=["张三","男",18,"篮球"]。请问:信息[2]是什么
A、“张三”B、“男”C、18D、“篮球”
2、
在条件分支中“判断表达式”属性是什么类型?
A、数值型B、字符串型C、布尔型D、浮点型
三、多项选择题
1、
以下是逻辑运算符的是哪些
A、and
B、or
C、not
D、but
四、填空题
略
答案:A、A、C、C、ABC