姑苏网站建设淘宝客做自己的网站
阿里云服务器全方位介绍包括云服务器ECS优势、云服务器租用价格、云服务器使用场景及限制说明,阿里云服务器网分享云服务器ECS介绍、个人和企业免费试用、云服务器活动、云服务器ECS规格、优势、功能及应用场景详细你说明:
目录
什么是云服务器ECS?
云服务器活动和租用费用
免费云服务器申请
云服务器ECS实例规格
云服务器产品优势
云服务器产品功能
拥有丰富ECS实例类型和多种存储选择
支持VPC专有网络
支持快照与多种镜像类型
多种付费和存储选择
云服务器应用场景
通用Web网站应用
在线游戏
大数据分析
深度学习
云服务器客户案例

什么是云服务器ECS?
阿里云服务器ECS英文全程Elastic Compute Service,云服务器ECS是一种安全可靠、弹性可伸缩的云计算服务。阿里云提供多种云服务器ECS实例规格,如通用算力型u1、ECS计算型c7、通用型g7、GPU实例等。云计算的出现,帮助用户降低IT成本,免去公司或个人前期采购IT硬件的成本,云服务器让用户像使用水、电、天然气等公共资源一样便捷、高效地使用服务器,像新浪微博、淘宝都是基于阿里云的云计算服务,阿里云作为国内第一云,市场份额占比远超友商,上云就上阿里云,可以在阿里云CLUB中心:aliyun.club 领取专属代金券。

阿里云服务器ECS
关于云服务器ECS的视频介绍如下:
云服务器活动和租用费用
阿里云服务器ECS目前通用算力型u1实例价格较为划算,轻量应用服务器价格成本比较低,详细参考活动: aliyunfuwuqi.com/go/aliyun 活动包括云小站、新人、学生和精选。
阿里云服务器根据以上活动,整理了云服务器ECS和轻量应用服务器的配置报价表:
| 云服务器规格 | CPU内存 | 公网带宽 | 系统盘 | 阿里云百科 |
|---|---|---|---|---|
| 云服务器u1(ecs.u1-c1m1.large) | 2核2G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 731.52元1年 |
| 云服务器u1(ecs.u1-c1m2.large) | 2核4G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 761.33元1年 |
| 云服务器u1(ecs.u1-c1m1.xlarge) | 4核4G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 1308.24元1年 |
| 云服务器u1(ecs.u1-c1m2.xlarge) | 4核8G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 1367.86元1年 |
| 云服务器u1(ecs.u1-c1m1.2xlarge) | 8核8G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 2461.68元1年 |
| 云服务器u1(ecs.u1-c1m2.2xlarge) | 8核16G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 2580.91元1年 |
| 云服务器c7(ecs.c7.large) | 2核4G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 1718.61元1年 |
| 云服务器c7(ecs.c7.xlarge) | 4核8G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 3127.61元1年 |
| 云服务器c7(ecs.c7.2xlarge) | 8核16G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 5945.63元1年 |
| 云服务器g7(ecs.g7.large) | 2核8G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 2117.95元1年 |
| 云服务器g7(ecs.g7.xlarge) | 4核16G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 3926.30元1年 |
| 云服务器g7(ecs.g7.2xlarge) | 8核32G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 7543.01元1年 |
| 云服务器r7(ecs.r7.large) | 2核16G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 2715.74元1年 |
| 云服务器r7(ecs.r7.xlarge) | 4核32G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 5121.88元1年 |
| 云服务器r7(ecs.r7.2xlarge) | 8核64G | 1M/2M/3M/4M/5M | 40GB ESSD云盘 | 9934.16元1年 |
| 轻量应用服务器 | 2核2G | 峰值带宽3M | 50GB高效云盘 | 108元一年 |
| 轻量应用服务器 | 2核4G | 峰值带宽4M | 60GB高效云盘 | 297.98元12个月 |
免费云服务器申请
阿里云个人用户和企业用户均可以申请免费云服务器,最长可以免费使用3个月,如下图:
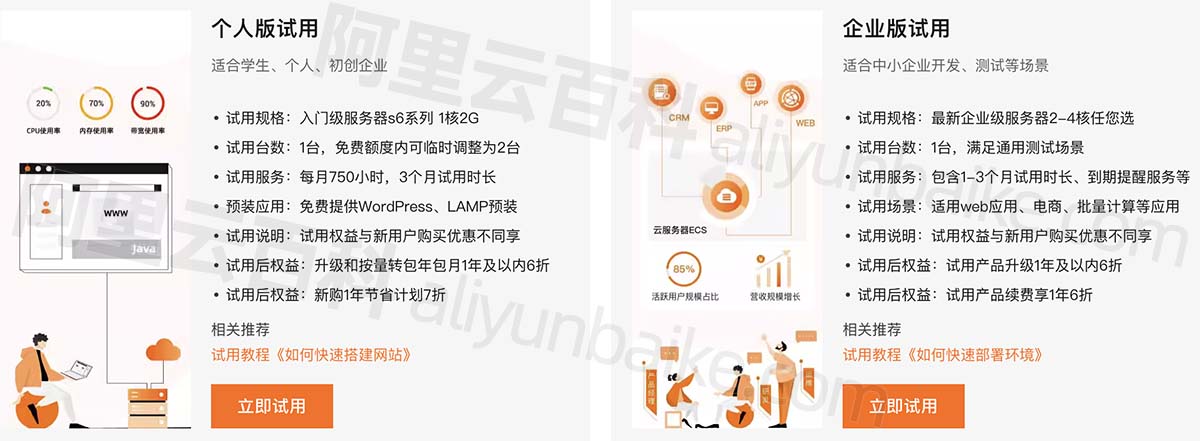
阿里云服务器免费试用
| 个人版试用:适合学生、个人、初创企业 | 企业版试用:适合中小企业开发、测试等场景 |
|---|---|
| 试用规格:入门级服务器s6系列 1核2G 试用台数:1台,免费额度内可临时调整为2台 试用服务:每月750小时,3个月试用时长 预装应用:免费提供WordPress、LAMP预装 试用说明:试用权益与新用户购买优惠不同享 试用后权益:升级和按量转包年包月1年及以内6折 试用后权益:新购1年节省计划7折 | 试用规格:最新企业级服务器2-4核任您选 试用台数:1台,满足通用测试场景 试用服务:包含1-3个月试用时长、到期提醒服务等 试用场景:适用web应用、电商、批量计算等应用 试用说明:试用权益与新用户购买优惠不同享 试用后权益:试用产品升级1年及以内6折 试用后权益:试用产品续费享1年6折 |
云服务器ECS实例规格
阿里云服务器ECS支持多种实例规格,如轻量应用服务器、ECS共享型s6、突发性能t6/t5、通用型g7/g6e、计算型c7/c6e、内存型、大数据型、GPU型、本地SSD型、高主频型、FPGA型、弹性裸金属服务器等。
云服务器ECS实例规格不同,CPU型号、主频性能都不同,详细参考参考:aliyunfuwuqi.com/go/cpu
云服务器产品优势
阿里云服务器弹性计算十余年深厚技术积淀,技术领先、性能优异、稳如磐石:
- 稳定:单实例可用性达 99.975%,多可用区多实例可用性达 99.995%,云盘可靠性达9个9,可实现宕机自动迁移、快照备份
- 弹性:支持分钟级别创建千台实例,多种弹性付费选择更贴合业务现状,同时带来弹性的扩容能力,实例与带宽均可随时升降配,云盘可扩容
- 安全:提供DDoS防护、木马查杀等服务,提供支持可信计算、硬件加密、虚拟化加密计算的实例,通过多方国际安全认证,ECS云盘支持数据加密功能
- 高性能:单实例最高可选256vCPU ,内存6TB,主频3.8GHz,性能最高可达2400万PPS,80Gbps,100万IOPS,1600万session,网络时延20us+
- 易用性:丰富的操作系统和应用软件,通过镜像可一键简单部署,同一镜像可在多台 ECS 中快速复制环境,轻松扩展
- 可拓展性:ECS 可与阿里云各种丰富的云产品无缝衔接,可持续为业务发展提供完整的计算、存储、安全等解决方案
云服务器产品功能
云服务器支持多种实例规格、计算架构、存储类型,支持VPC专有网络、快照镜像、多种付费模式和存储选择:
拥有丰富ECS实例类型和多种存储选择
面向各类企业应用场景,云服务器ECS将提供超过100款高性能规格族供您选择。按您的实际业务场景可选择不同配置实例搭配1到65块不同容量的存储磁盘。
- 计算架构:提供X86、ARM计算架构,在选型时您可以选择适合的架构,充分贴合您的业务场景。
- 实例规格:每种计算架构下提供多种面向不同场景的实例类型和规格,在满足您需求的同时提供极致的性价比。
- 存储类型:按您的实际业务场景可选择不同配置实例,搭配1到65块不同容量的存储磁盘。云盘、本地盘提供给您多样选择的同时,云盘将提供给您最高9个9的可靠性。
支持VPC专有网络
基于阿里云构建的一个隔离的网络环境,专有网络之间逻辑上彻底隔离,只能通过对外映射的IP(弹性公网IP和NAT IP)互联。由于使用隧道封装技术对云服务器的IP报文进行封装,所以云服务器的数据链路层(二层MAC地址)信息不会进入物理网络,实现了不同云服务器间二层网络隔离,因此也实现了不同专有网络间二层网络隔离。专有网络内的ECS使用安全组防火墙进行三层网络访问控制。
- 访问控制:灵活的访问控制规则。 满足政务、金融的安全隔离规范。
- 软件定义网络:按需配置网络设置,软件定义网络。管理操作实时生效。
- 丰富的网络连接方式:支持软件VPN;支持专线连接。
支持快照与多种镜像类型
阿里云服务器支持快照与多种镜像类型,支持您的业务快速部署。
- 快照安全系数更高:每个云盘有1256个快照额度,为客户数据提供更长的保护周期和更细的保护粒度。
- 自动快照策略:实现无人值守的自动化数据备份,减轻运维部门工作负担。
- 快照灵活易用:性能影响小,用户业务无感知,随时支持数据快照备份。支持秒级创建/回滚的极速快照和快照一致性组。
- 镜像种类丰富:公共镜像、镜像市场、自定义镜像、社区镜像满足各类型用户对于应用环境的快速部署、灵活管理的需求。
- 镜像构建服务:提供一站式镜像定制服务,支持镜像的定制、分发、共享等操作。
多种付费和存储选择
通过包年包月、按量付费、节省计划、预留实例券和抢占式5种付费模式分别满足长周期低成本以及周期高弹性的计算要求。
- 节省计划:适合用户在一定时间段内(1年或3年)有稳定使用云资源的场景(以元/小时为单位衡量)。在购买节省计划后,开通计划下的ECS、ECI等按量资源,每小时可享受计划折扣权益,每小时账单将自动进行抵扣。
- 包年包月购买:适合长期稳定的业务,购买周期越长,折扣越高,最高可享受5年3折。
- 按量付费购买:紧贴业务需求购买资源的付费方式,秒级计费,用多少花多少。
- 预留实例券:一种抵扣券,适合需要兼顾灵活性和成本的业务,或者需要预留实例资源的业务。搭配按量付费实例使用,可以抵扣掉按量付费实例计算部分的账单。相比直接使用按量付费实例,成本最大可以降低79%。
- 抢占式实例:适合周期性离线计算场景,可使用远低于原价的成本获得资源,最低原价一折售卖,但会根据供需变化或者竞价价格而被释放。
云服务器应用场景
通用Web网站应用
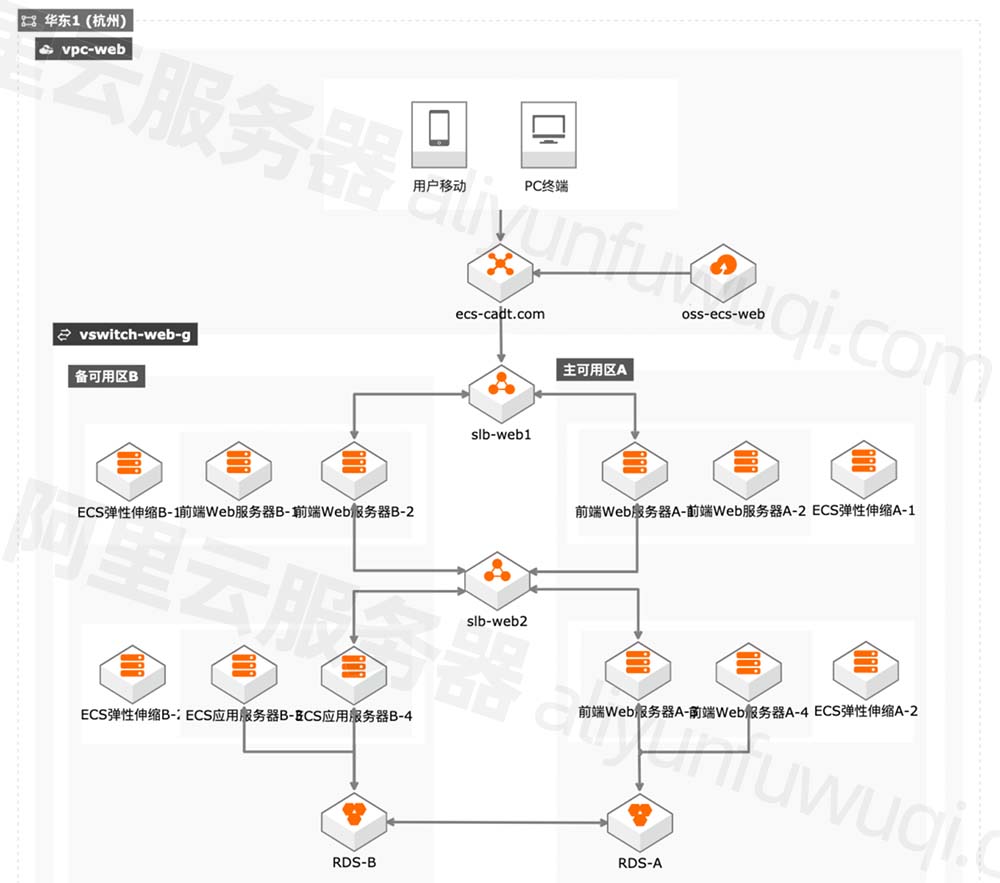
阿里云服务器网站应用
大部分Web应用使用的架构,阿里云推荐C/G/R系列服务器,兼顾高效搭建使用及高性能处理能力
- CDN网络为Web应用提供内容分发服务,保证优秀的用户体验与成本节约
- 内容缓存在OSS存储中,提供高可靠性、低成本的存储容量
- 负载均衡处理HTTP请求,并将流量分发到主业务可用区
- 前端和应用服务器部署在ECS 实例上,SLB可以做到负载均衡
- ESS弹性伸缩按需业务创建或释放资源,使您能够获得更优秀的业务性能和成本支出
- 部署在多可用区RDS上的数据库保证业务的容灾性能
在线游戏
高并发、瞬时计算量大的场景,阿里云推荐高主频及GPU服务器实现高计算性能与高图像渲染性能的需求
- 负载均衡处理HTTP请求,并将流量分发到指定的游戏服集群
- 连接服、游戏服、缓存服等通过ESS弹性伸缩按需创建或释放资源
- 部署在多可用区RDS上的数据库保证业务的容灾性能
大数据分析
对于频繁对存储读取的大数据应用场景,阿里云推荐大数据实例及本地盘实例,主从节点皆有性能优异表现
- 业务系统产生日志等数据传输到Hadoop大数据存储进行分析;或用户大数据存在OSS对象存储,并加载到Hadoop大数据系统中进行分析
- 基于ECS大数据实例构建高性价比、海量可扩展的云端Hadoop系统
- 分析结果可以存放在MySQL或NoSQL(HBase/MongoDB/Redis)等数据库,便于用户查询
- 大数据 Bi 及展示
深度学习
对于持续且大量的人工神经网络计算的深度学习场景,阿里云推荐GPU实例及AMD实例,不但性能表现卓越,同时大量节省成本
- 在数据层面可以与OSS对象存储、NAS文件存储、云盘等打通,满足深度学习海量训练数据的低成本存储和访问要求
- 通过EMR服务进行数据的预处理
- 通过云监控服务进行GPU资源的监控与告警
- 通过ECS、负载均衡、弹性伸缩、资源编排等快速在云端搭建完整AI深度学习业务系统
云服务器客户案例
新浪微博、火花思维、汇量科技和驻云科技均在使用阿里云服务器:
- 新浪微博:通过ECI+ASK的弹性伸缩和快速启动特性,大大缩短扩容时间,轻松支撑突发流量并保障业务稳定性。
- 火花思维:通过ECI的免运维&全自动化弹性伸缩能力,提高利用率,大幅降低成本和运维工作,助力业务高速增长。
- 汇量科技:基于阿里云的弹性伸缩能力共同推出弹性集群管理方案SpotMax,保证弹性资源可用性下实现了更低成本。
- 驻云科技:使用ROS的模版,一键部署企业级高可用SAP优秀实践,较其他云上SAP顾问,部署效率提升约30倍。
更多关于阿里云服务器ECS详细说明,请以官方页面为准:aliyunfuwuqi.com/go/ecs