网站 手机 app建个网站的电话
jenkins中使用allure生成报告需要注意工作环境和路径的配置
前提条件:
jenkins容器中已安装jdk和allure

jenkins中配置全局工具环境:


项目中配置allure路径:
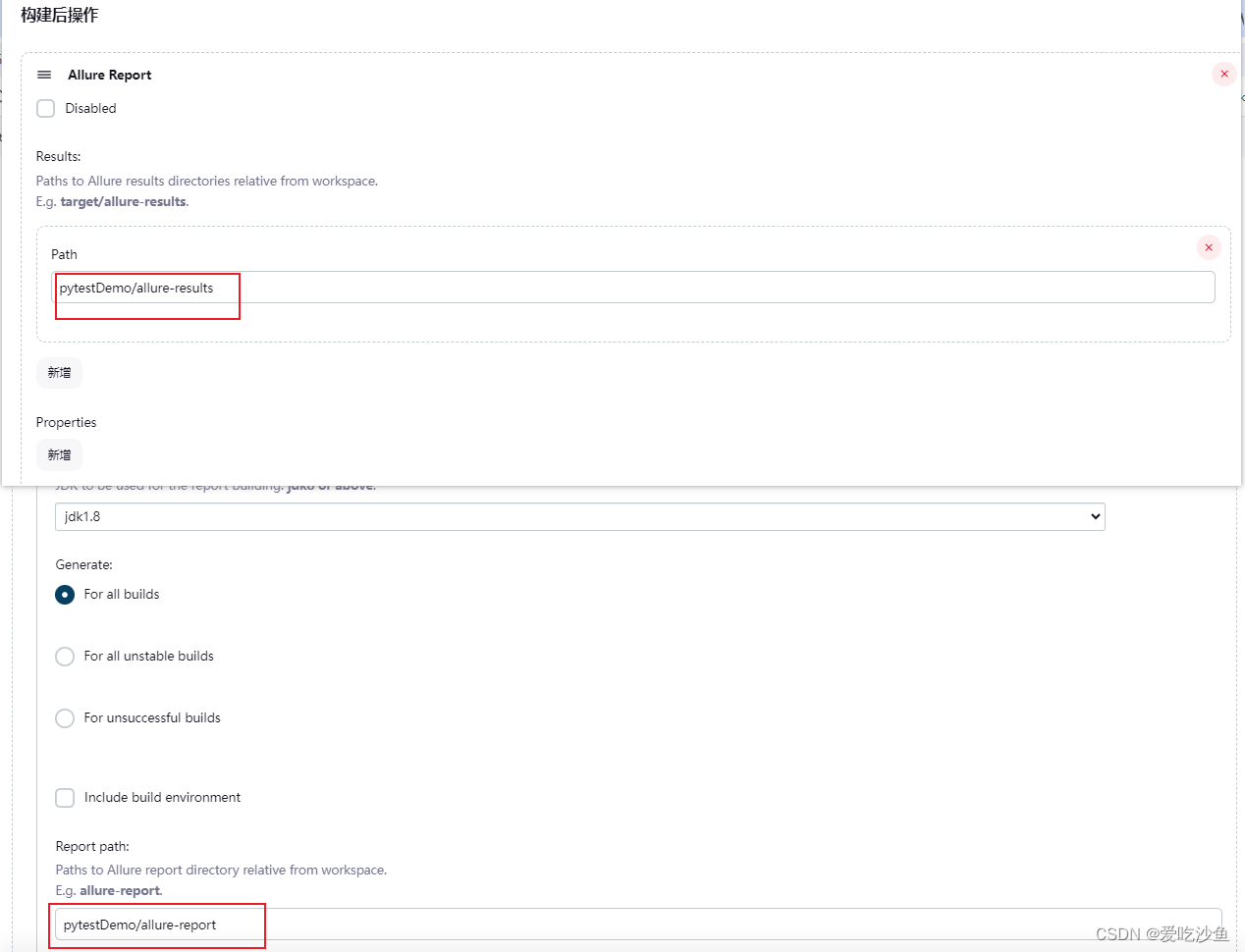
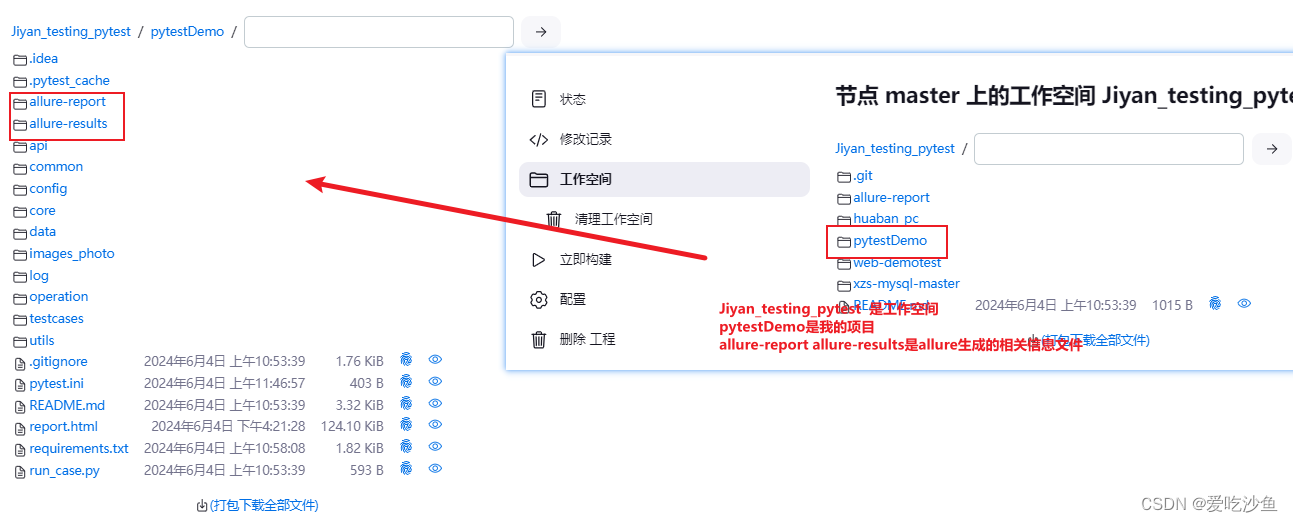
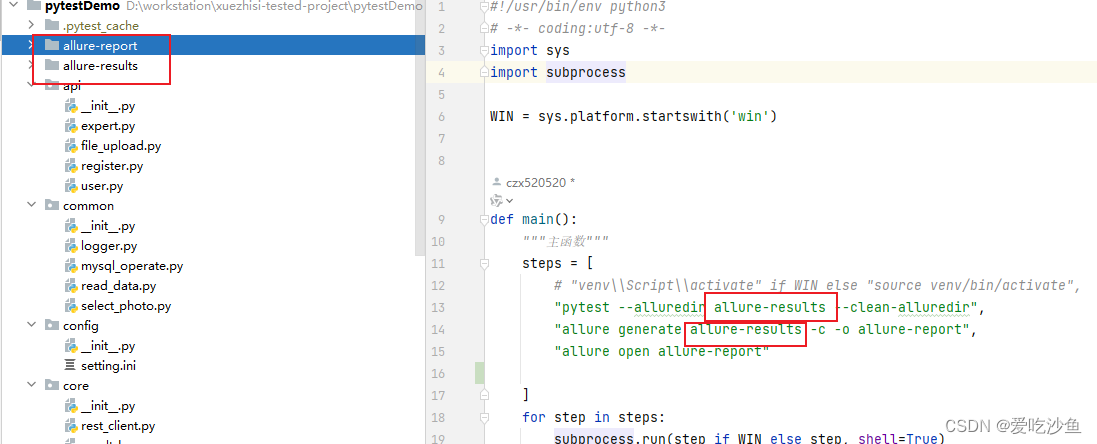
路径来源:
Path需要选择相对路径的allure-report、allure-results
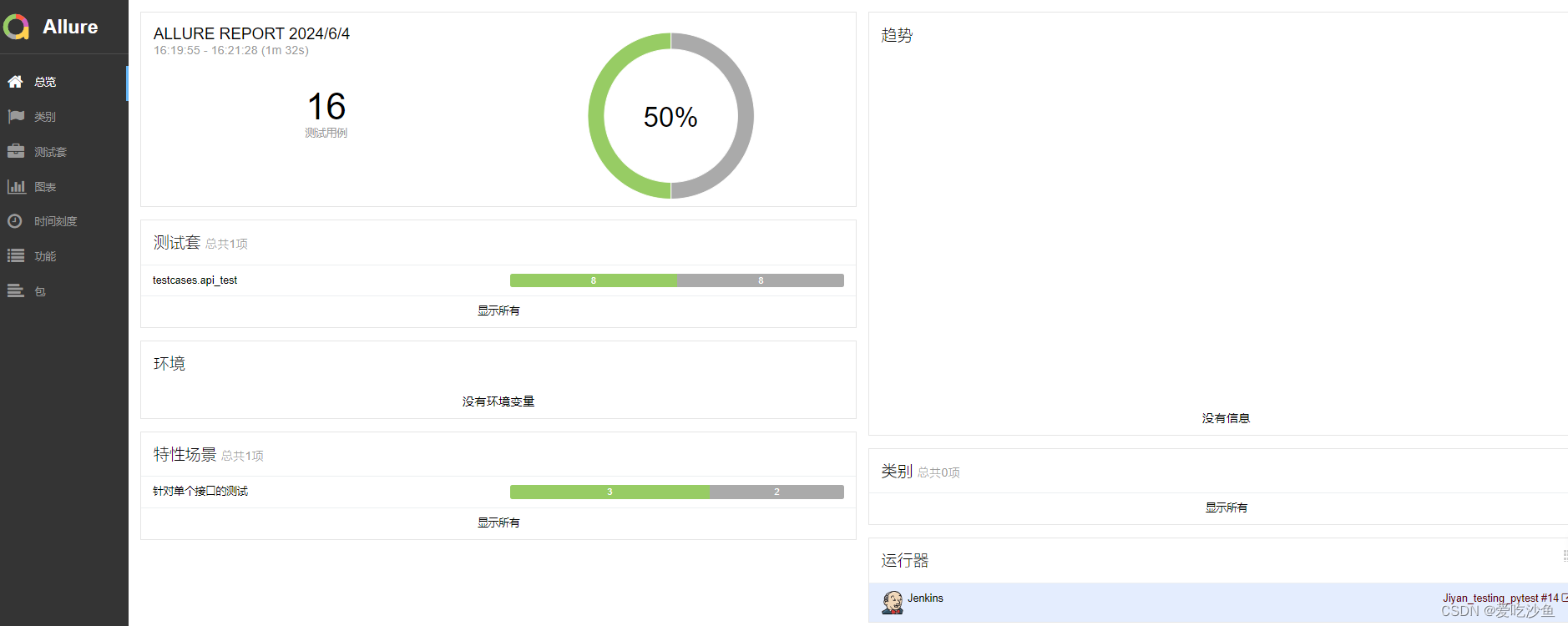
jenkins中使用allure生成报告需要注意工作环境和路径的配置
前提条件:
jenkins容器中已安装jdk和allure
jenkins中配置全局工具环境:
项目中配置allure路径:
路径来源:
Path需要选择相对路径的allure-report、allure-results