在excel中怎么做邮箱网站关键词点击优化工具
pipeline自动化,提交代码后,就自动打包,打包成功后自动发布
第一步 pipeline提交代码后,自动打包。
1 在Repos,分支里选择要触发的分支,这里选择cn_china,对该分支设置分支策略
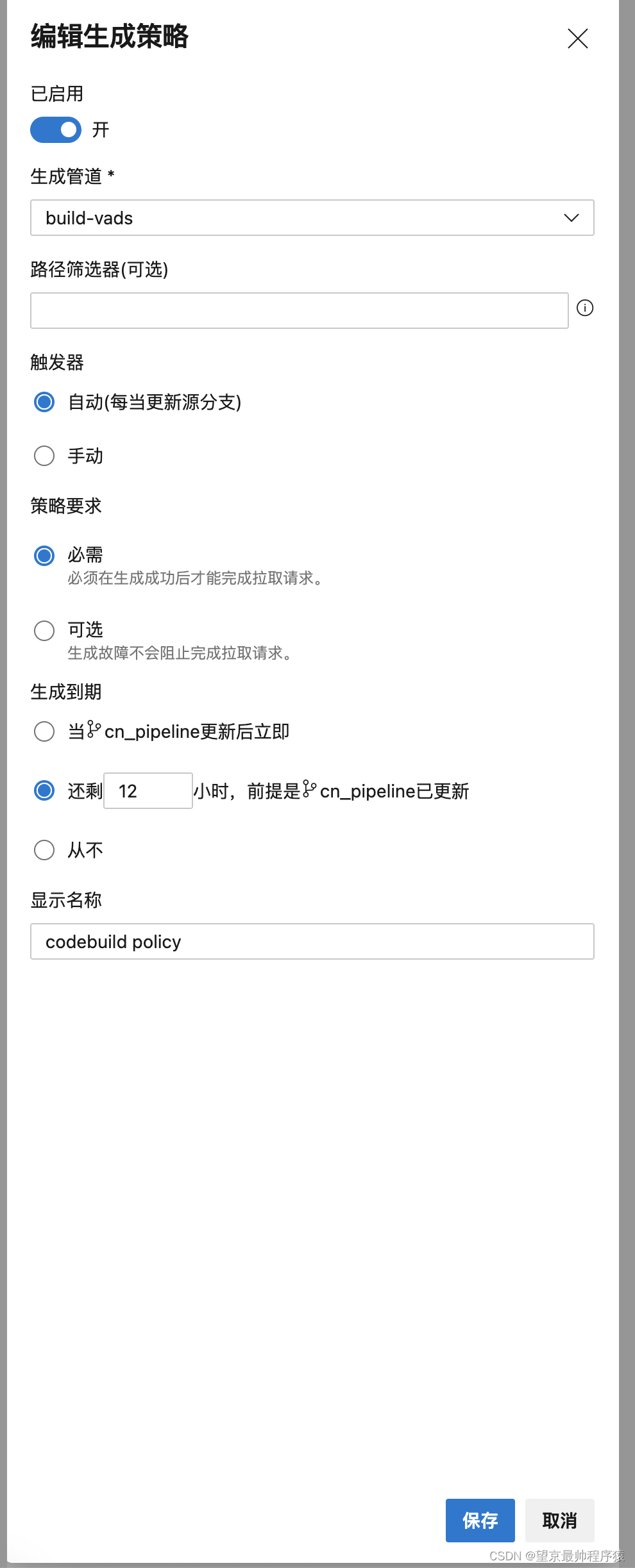
2 在生产验证中增加新的策略
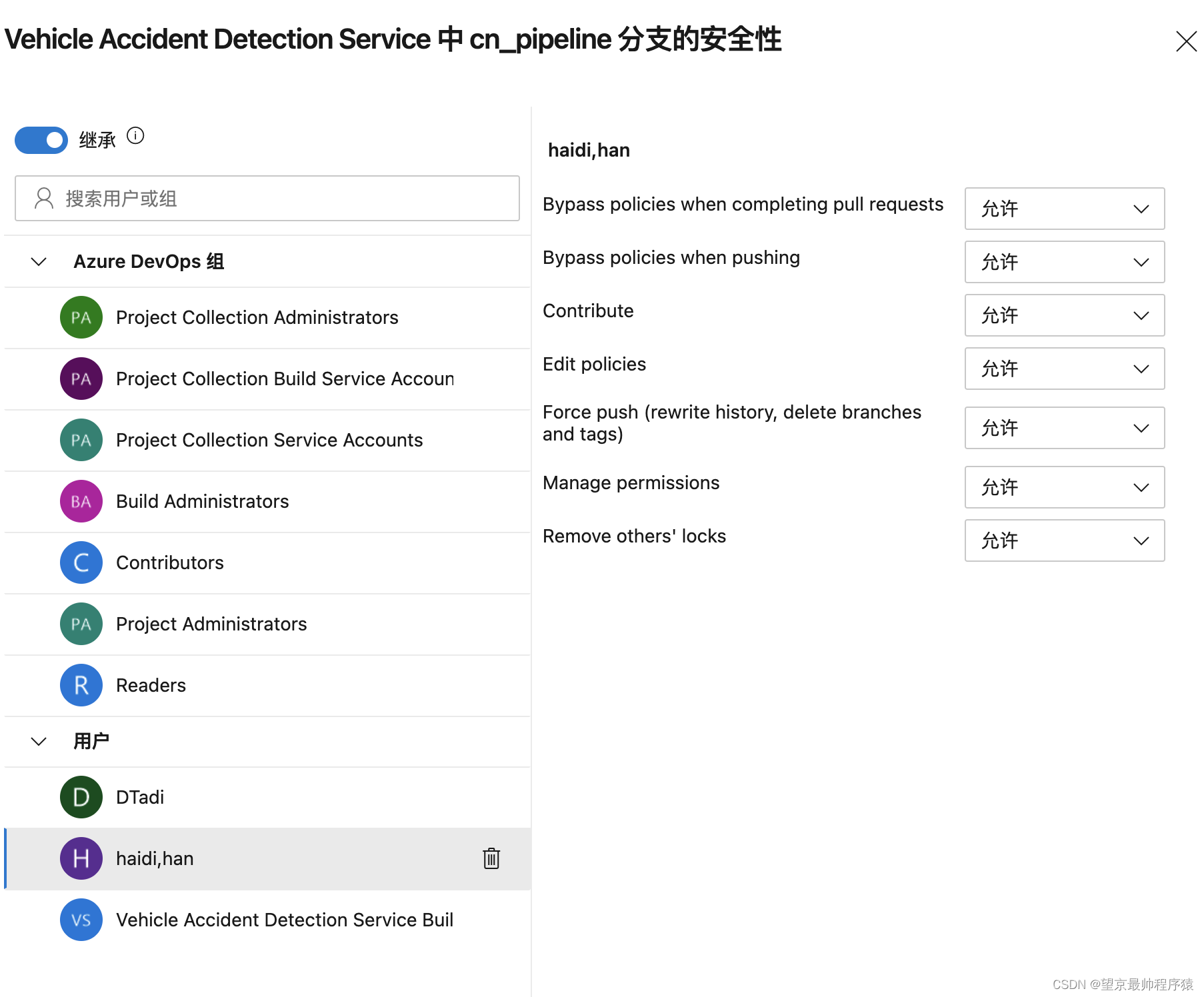
3 在分支安全性中,设置 Bypass policies when completing pull request,Bypass policies when pusing 为允许,否则提交代码报错。
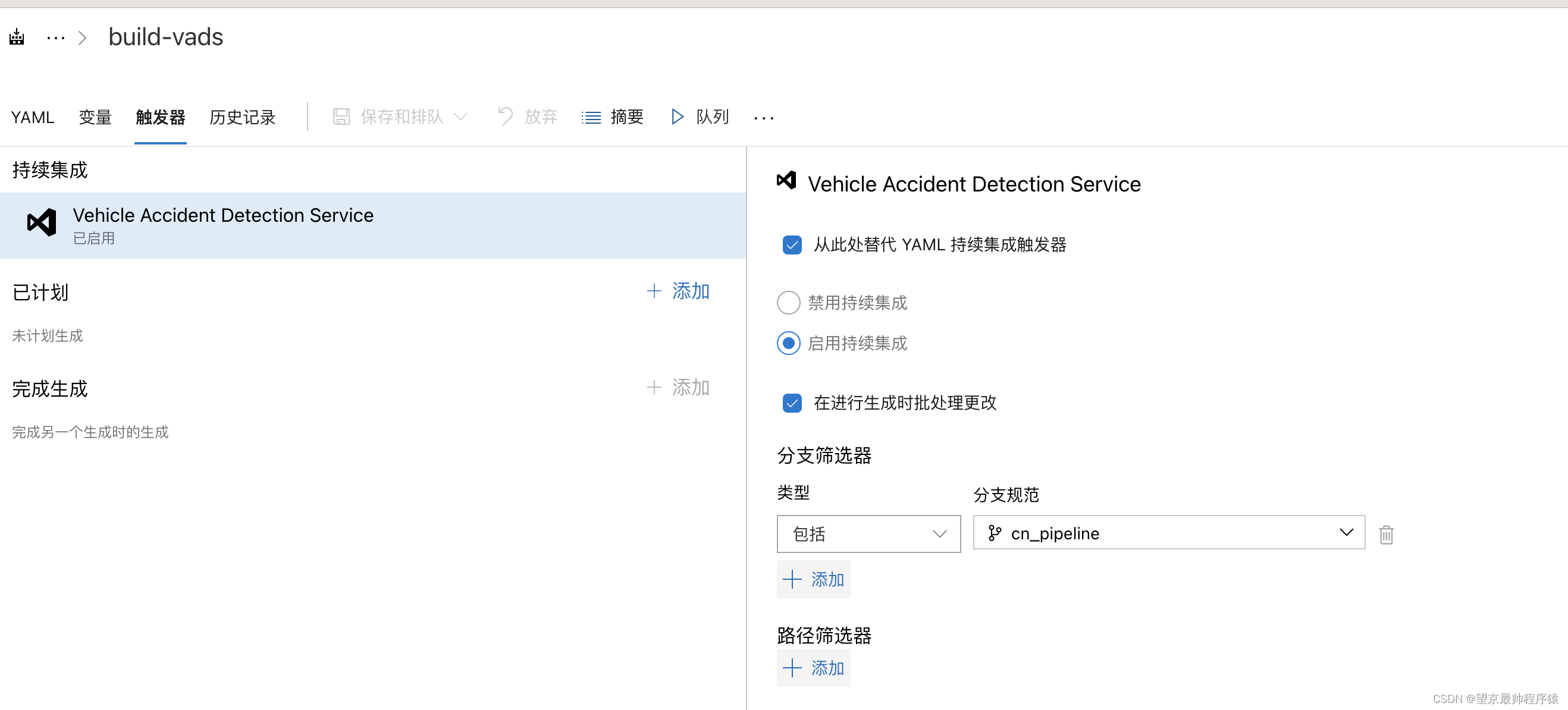
4 在build的触发中,把持续集成打开,并选择分支
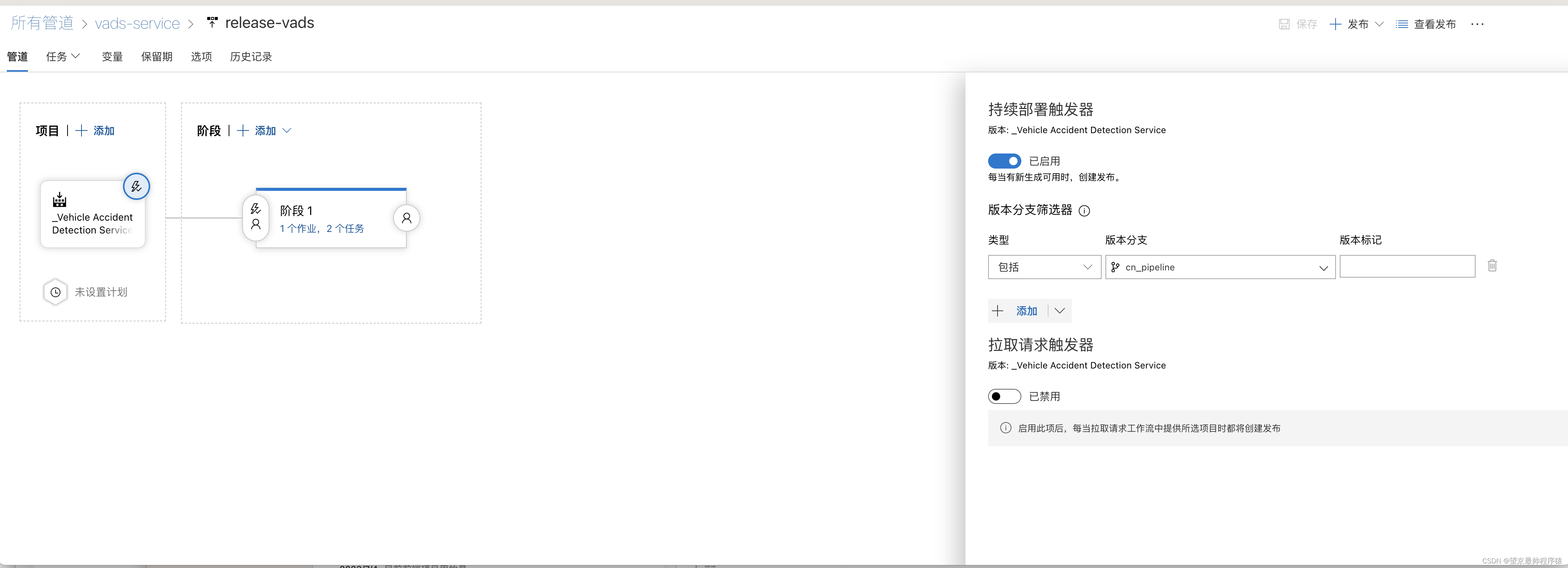
第二步 打包完成后,自动发布
在发布中,设置持续部署触发器
参考
如何利用Azure DevOps快速实现自动化构建、测试、打包及部署