做网站用什么虚拟主机河北住房和建设厅官方网站
一、二路分支
- 逻辑:程序中某段代码需要在满足某个条件时才能运行
- 形式:
- if 语句:表达一种 如果-则 的条件执行关系
- if-else 语句:表达一种 如果-否则 的互斥分支关系
- 流程图:
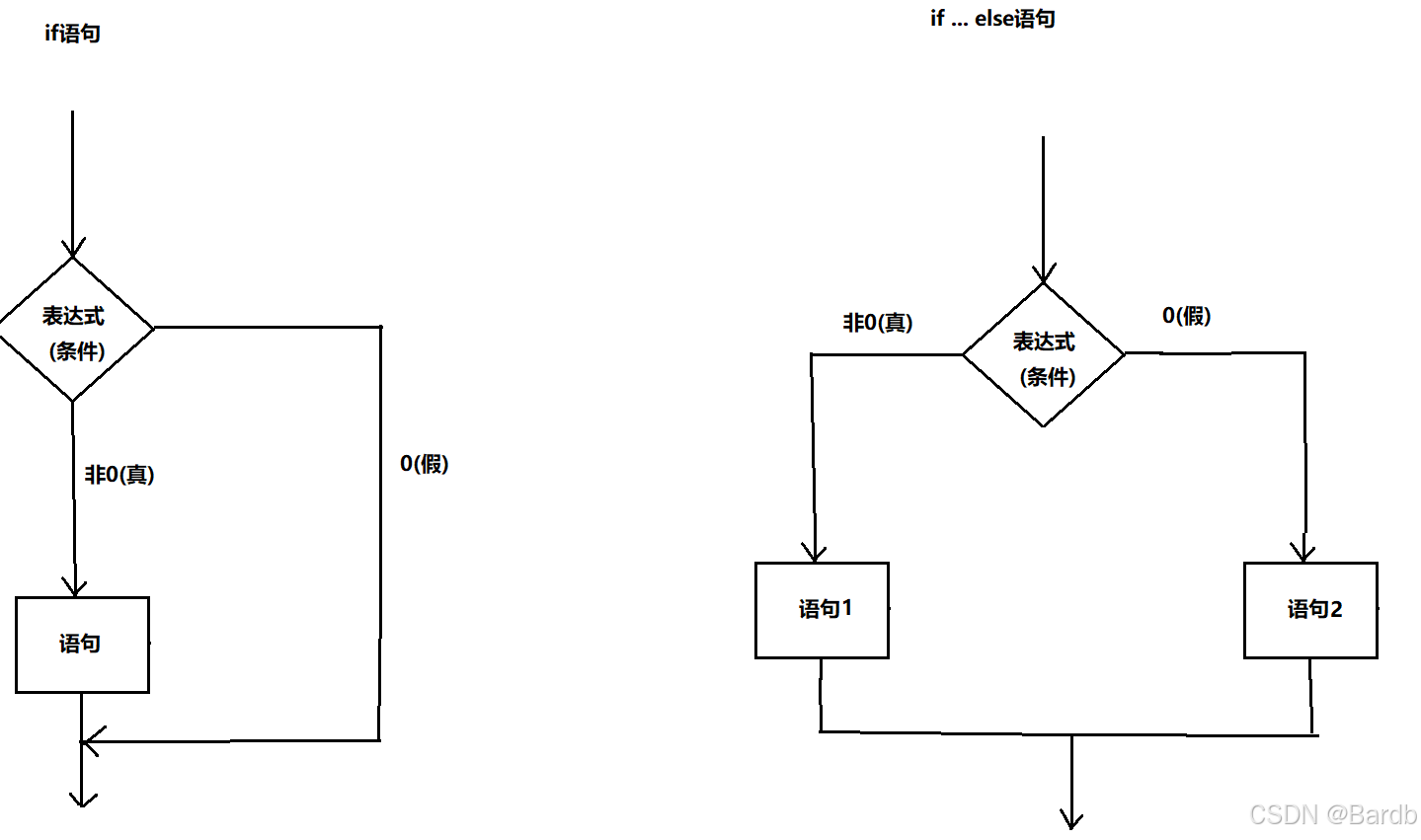
- 注意:
- if 语句可以单独使用,else 语句不可以,else 语句必须跟if语句配套使用
- 不管是 if 语句还是 else 语句,代码块都必须使用大括号{}括起来,否则只有首句有效
- 注意if语句后面是否有;号,如果其加了;号,不论语句判断是否正确,都将会执行{}里的内容
- 示例代码:
#include <stdio.h>
int main(int argc, char const *argv[])
{// (1)、if 语句:表达一种 如果-则 的条件执行关系// 1、输入整型数据int n = 0;int num = 0;// printf("请输入一个整型数据!\n");// while ( n!= 1)// {// n = scanf("%d", &num);// if ( n!= 1)// {// printf("格式错误:请重新输入(整型数据)!!!:\n");// }// while( getchar() != '\n');// }// printf("num == %d\n", num);// 2、判断整型数据if ( (num % 2) == 0) // 判断num是否为偶数{printf("num是偶数(语句1)\n"); }// (2)、if-else 语句:表达一种 如果-否则 的互斥分支关系if ( (num % 3) == 0) {printf("num是3的倍数(语句2)\n"); }else{printf("num不是3的倍数(语句3)\n"); }// (3)、if 语句可以单独使用,else 语句不可以,else 语句必须跟if语句配套使用if ( num == 100) // 可以单独使用{}// printf("hello world!\n"); // if...else中间不能写其它语句,否则会报错else // 不可以单独使用{}// (4)、不管是 if 语句还是 else 语句,代码块都必须使用大括号{}括起来,否则只有首句有效int flag = 0;int n1 = 0;int n2 = 0;int n3 = 0;// 建议的写法:if (flag == 0) // 有花括号,if语句的作用范围为{}括起来的所有语句{n1 = 100;n2 = 200;n3 = 300;}else // 有花括号,else语句的作用范围为{}括起来的所有语句{n1 = 111;n2 = 222;n3 = 333; }printf("n1 == %d, n2 == %d, n3 == %d\n", n1, n2, n3);// 不太建议的写法1:if (flag == 1) // 没有{}括号,if语句的作用范围仅限于一行n1 = 11;n2 = 22; // 影响不了下面的语句n3 = 33;printf("n1 == %d, n2 == %d, n3 == %d\n", n1, n2, n3);// 不太建议的写法2:if (flag == 0) n1 = 11111;elsen2 = 22222; // 没有{}括号,else语句的作用范围仅限于一行n3 = 33333; // 影响不了下面的语句printf("n1 == %d, n2 == %d, n3 == %d\n", n1, n2, n3);// (5)、注意if语句后面是否有;号,如果其加了;号,不论语句判断是否正确,都将会执行{}里的内容int ts_x = 0;int ts_y = 0;printf("请输入触摸屏的x和y轴的坐标(整型,整型)!\n");while (1){// 1、输入触摸屏数据while ( n!= 2){n = scanf("(%d,%d)", &ts_x, &ts_y);if ( n!= 2){printf("格式错误:请重新输入触摸屏的x和y轴的坐标(整型,整型)!!!:\n");}while( getchar() != '\n');}n = 0; // 2、判断触摸屏数据if ( (ts_x >100 && ts_x < 200) && (ts_y>100 && ts_y < 200)); // 这个if后面加了;号,意味着其作用范围到此行为止,所以影响不了下面的{}语句{ // 此处已经变为了单独的语句了,不管if语句是否为真或假printf("手指点击了这个地方\n");}}return 0;
}二、多路分支
- 逻辑:根据不同的条件执行不同的代码片段
- 语法:
- 流程图:
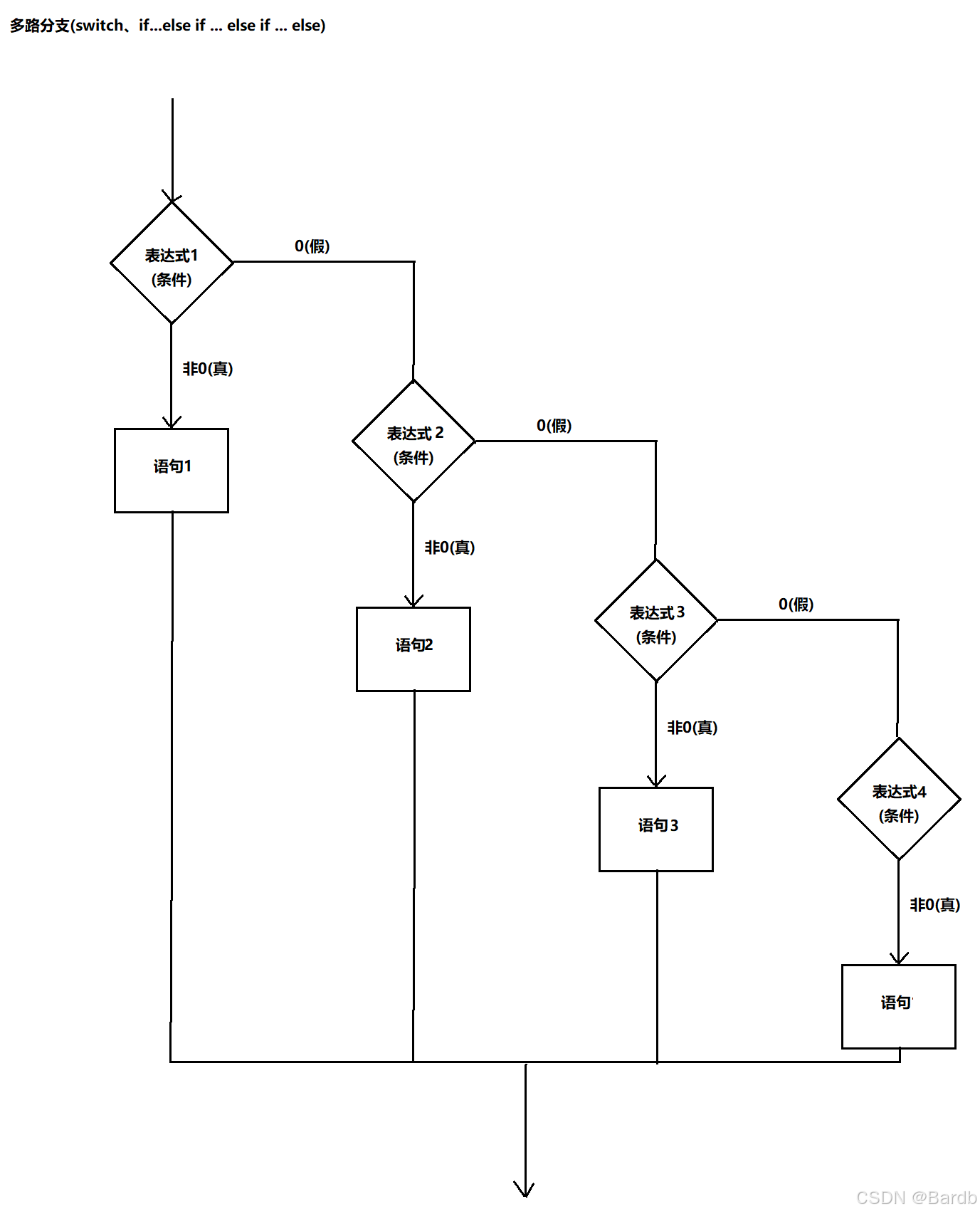
- 要点解析:
- switch(n) 语句中的 n 必须是一个整型表达式,即 switch 判断的数据必须是整型(字符(本质上就是单字节整型)、整型数据(变量(num1、num2...)、常量(1,2,3...)、整型表达式)
- case 语句只能带整型常量,包括普通整型或字符,不包括 const 型数据。
- break 语句的作用是跳出整个 swtich 结构,没有 break 程序会略过case往下执行
- default 语句不是必须的,一般放在最后面(因此不需要 break)
#include <stdio.h>
int main(int argc, char const *argv[])
{// (1)、if...else if ... else if ...elseint flag = 2;if (flag == 1){printf("执行语句1\n");}// printf("hello wordl!\n"); // 会报错,if...else中间不能有其它语句,否则会打断其连续性(逻辑)else if(flag == 2){printf("执行语句2\n");}else if(flag == 3){printf("执行语句3\n");}else{printf("执行语句4\n");}// (2)、switch语句的基本用法// 1、switch(n)语句中的n为字符, case 语句为:字符char ch1 = 'a';switch (ch1) // 1、switch(n) 语句中的 n 必须是一个整型表达式,即 switch 判断的数据必须是整型(字符(本质上就是单字节整型)、整型数据(变量(num1、num2...)、常量(1,2,3...)、整型表达式){case 'a': // 2、case 语句只能带整型常量,包括普通整型或字符,不包括 const 型数据printf("11111111\n");break; // 3、break 语句的作用是跳出整个 swtich 结构,没有 break 程序会略过case往下执行default: // 3、default 语句不是必须的,一般放在最后面(因此不需要 break)printf("shijienameda,woxiangdainiqukankan!\n"); break;}// 2、switch(n)语句中的n:整型数据, case 语句为:字符int n1 = 1;switch (n1) {case 1: printf("aaaaaaaaaaa\n");break; default:printf("shijienameda,woxiangdainiqukankan!\n"); break;}// 3、switch(n)语句中的n:常量数据(字符常量、整型常量), case 语句为:'a'...'z'switch ('a') {case 'a'...'z': printf("!!!!!!!!!!!!!\n");break; default: printf("shijienameda,woxiangdainiqukankan!\n"); break;}// 4、switch(n)语句中的n:整型表达式, case 语句为:普通整型或字符int a = 100;int b = 99;int c = 0;switch (c=a+b) {case 1: printf("^^^^^^^^^^\n");break; default: printf("shijienameda,woxiangdainiqukankan!\n"); break;}// (3)、实际项目中如果使用switch语句(指纹解锁)int finger_flag = 0;int n = 0;int finger_idbuf[5] = {0};int count = 0;char select = 0;while (1){switch (finger_flag){case 0:goto run_label;break;case 1:printf("1、请按指纹!\n");scanf("%d", &n); // 模拟指纹操作while( getchar() != '\n');if (n == 1) // 让其接下下面的操作finger_flag = 2; elsefinger_flag = 1;break;case 2:printf("2、指纹正常!\n");scanf("%d", &n); while( getchar() != '\n');if (n == 1) finger_flag = 3; elsefinger_flag = 1; break;case 3:printf("3、请再次按指纹!\n");scanf("%d", &n); while( getchar() != '\n');if (n == 1) finger_flag = 4; elsefinger_flag = 1; break;case 4:printf("4、指纹正常!\n");scanf("%d", &n); while( getchar() != '\n');if (n == 1) finger_flag = 5; elsefinger_flag = 1; break;case 5:printf("5、正在对比两次指纹\n");scanf("%d", &n); while( getchar() != '\n');if (n == 1) finger_flag = 6; elsefinger_flag = 1; break;case 6:printf("6、对比成功,两次指纹一致\n");printf("请输入指针ID号:\n");scanf("%d", &finger_idbuf[count]);while( getchar() != '\n');printf("查询(c) 继续(y) 退出(n)\n");scanf("%c", &select); while( getchar() != '\n');count++;if (select == 'y') finger_flag = 1; else if(select == 'n') finger_flag = 99; else if(select == 'c') {printf("指纹库里面的ID号:\n");for (int i = 0; i < 5; i++){printf("finger_idbuf[%d] = %d\n", i, finger_idbuf[i]);}finger_flag = 1; } break;default :goto exit_sys_label;break;}}
int n2 = 0;int cnt = 0;run_label:n2 = 1;cnt = 0;switch (n2){case 0:printf("1111111\n"); break;case 1:printf("2222222\n"); cnt = 100; case 2:printf("3333333\n");cnt = 200; case 3:printf("444444\n"); cnt = 300; break;default:break;}printf("cnt == %d\n", cnt);exit_sys_label:printf("已退出指纹模块系统\n");return 0;
}
三、const ---
- 逻辑:使一个变量不可修改
- 作用:
- 修饰普通变量,使之不可修改
- 修饰指针变量,使之不可修改或者使其指向的目标不可修改
#include <stdio.h>
int main(int argc, char const *argv[])
{// (1)、没有const修饰的时候int num1 = 100; // 定义了一个int型的变量(该变量可读可写)num1 = 200;printf("num1 == %d\n", num1);// (2)、有const修饰的时候// 1、写法1:int const num2 = 200; // 初始化,该变量设置成了只读(该变量的值不可变)// num2 = 400; // 可读不可写(报错误: error: assignment of read-only variable ‘num3’)printf("num2 == %d\n", num2);// 2、写法2:const int num3 = 300; // 初始化,该变量设置成了只读(该变量的值不可变)// num3 = 500; // 可读不可写(报错误: error: assignment of read-only variable ‘num3’)printf("num3 == %d\n", num3);// (3)、case 语句只能带整型常量,包括普通整型或字符,不包括 const 型数据。const int num4 = 100;switch ( num4 ){// case num4: case 100:printf("11111111\n");break;default:break;}return 0;
}四、while循环
- 逻辑:使得程序中每一段代码可以重复循环地运行
- 流程图:
- while循环:先判断,循环(入口判断)
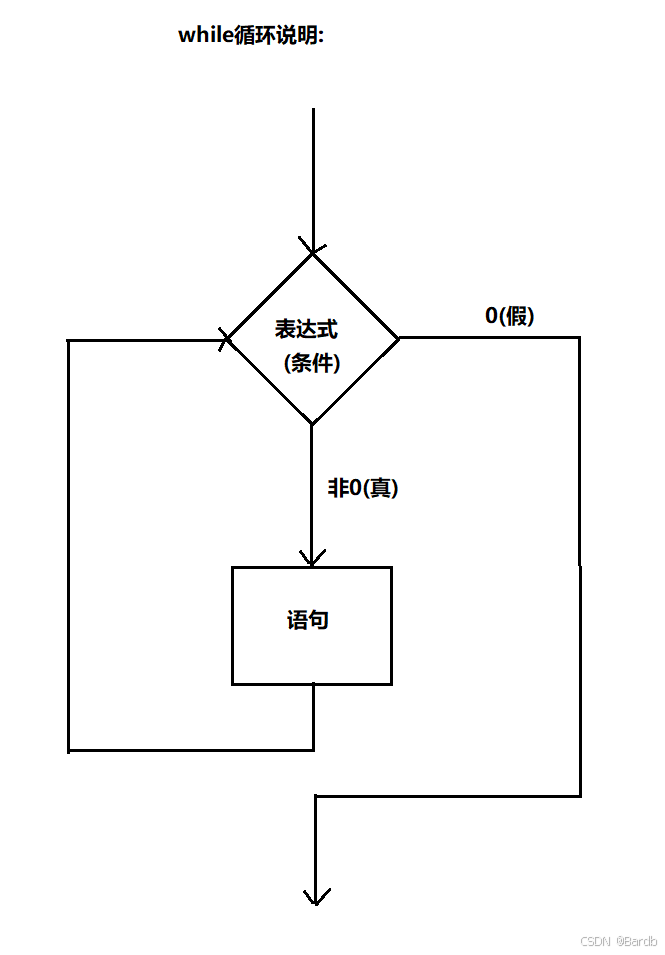
- 示例代码:
#include <stdio.h>// 界面功能函数
int inf1_flag = 0;
int inf2_flag = 0;
int inf3_flag = 0;
int n = 0;// 界面1
void Inf1_loop(void)
{printf("你正处在第一层循环中: 请输入控制语句!\n");scanf("%d", &n);while( getchar() !='\n');switch (n){case 1: // 功能1:进去inf2界面2inf2_flag = 1;printf("inf1:func1\n");break;case 2: // 功能2:printf("inf1:func2\n");break;case 3: // 功能3: 退出inf1_flag = 0;printf("退出inf1循环\n");break;}
}// 界面2
void Inf2_loop(void)
{printf("你正处在第二层循环中: 请输入控制语句!\n");scanf("%d", &n);while( getchar() !='\n');switch (n){case 1: // 功能1:进去inf3界面3inf3_flag = 1;printf("inf2:func1\n");break;case 2: // 功能2:printf("inf2:func2\n");break;case 3: // 功能3: 退出inf2_flag = 0;printf("退出inf2循环\n");break;}
}// 界面3
void Inf3_loop(void)
{printf("你正处在第三层循环中: 请输入控制语句!\n");scanf("%d", &n);while( getchar() !='\n');switch (n){case 1: // 功能1:printf("inf3:func1\n");break;case 2: // 功能2:printf("inf3:func2\n");break;case 3: // 功能3: 退出inf3_flag = 0;printf("退出inf3循环\n");break;}
}// 主函数
int main(int argc, char const *argv[])
{// (1)、基本用法:// 1、紧凑程度更好,不可以留遗言int flag1 = 0;while (flag1 < 5){flag1++;printf("flag1 == %d\n", flag1);}// 2、比较分散,但可以留遗言int flag2 = 0;while (1) // 死循环(因为条件一直为真){flag2++;printf("flag2 == %d\n", flag2); if (flag2 > 4){printf("啊,我死了,家产由最帅的那个继承\n"); // 退出前措施break;} }// (2)、多重循环 --- 界面(逻辑)功能跳转的时候inf1_flag = 1;while ( inf1_flag == 1) // 最外层循环(第一个界面(逻辑)){Inf1_loop();while ( inf2_flag == 1){Inf2_loop();while (inf3_flag == 1){Inf3_loop();}} }return 0;
}五、do-while循环
- 逻辑:使得程序中每一段代码可以重复循环地运行
- 流程图:
- do-while 循环:先循环,再判断(出口判断)
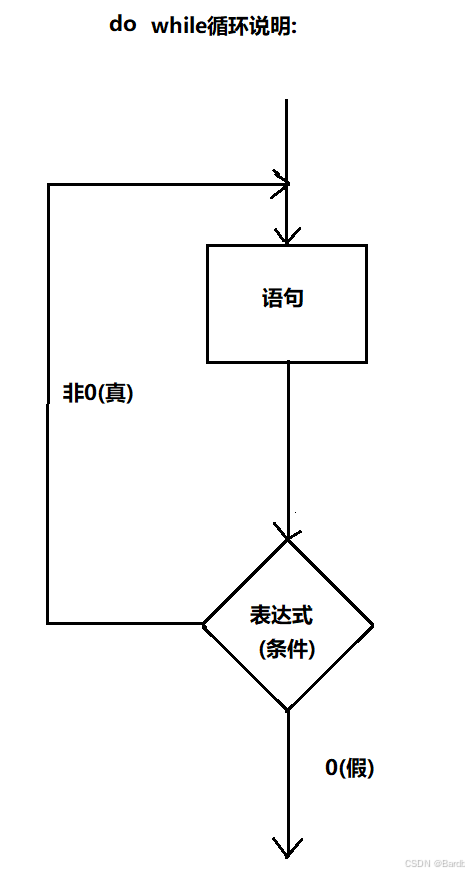
- 语法点:
- while 循环先进行判断,条件为真后才执行循环体,因此循环体可能一遍也不执行。
- do-while 循环先执行循环体,再进行判断,因此循环体至少会执行一遍。
- do-while 循环中的 while 语句后面有分号;
- 示例代码:
#include <stdio.h>
int main(int argc, char const *argv[])
{// // 1、测试:循环输出一系列的正数,直到100为止(不满足条件也会再执行一遍)// int num = 0;// printf("请输入一个整数\n");// scanf("%d", &num);// do// {// printf("%d\n", num);// num++;// } while (num<=100);// (2)、其它特性都和while循环一致// 1、紧凑程度更好,不可以留遗言int flag1 = 0;do{flag1++;printf("flag1 == %d\n", flag1);} while (flag1<5);// 2、比较分散,但可以留遗言int flag2 = 0;do{flag2++;printf("flag2 == %d\n", flag2);if (flag2 > 4){printf("快把浏览器记录删除了!!!快!!!\n"); // 退出前的措施printf("要留清白在人间\n");break;}} while (1);return 0;
}
六、for循环
- 逻辑:与 while 循环类似,但更加紧凑,for 循环将控制循环的变量集中在一行
- 语法点:
- 循环头的标准语法是: for(表达式1 ; 表达式2 ; 表达式3)
- 表达式3:一般用来更新循环控制变量
- 表达式2:一般用来作为循环判定条件,为真则进入循环,为假则跳出循环
- 表达式1:一般用来初始化循环控制变量
- 三个表达式均可以省略,但分号不能省略( for( ; ; ) == 相当于while(1) )
- 示例代码:
#include <stdio.h>
#include <unistd.h>int main(int argc, char const *argv[])
{// (1)、for循环和while循环的区别for (int i = 0; i < 5; i++) // 此处的int i;在新版本编译器中可以放在for循环体内,但是在低级编译器里面不行{printf("i == %d\n", i);}// 相当于:int num1 = 0; // 相当于for循环语句的:表达式1while (num1 < 5) // 相当于for循环语句的:表达式2{printf("num1 == %d\n", num1); // 相当于for循环语句的要运行的语句num1++; // 相当于for循环语句的:表达式3}// // (2)、- 三个表达式均可以省略,但分号不能省略( for( ; ; ) == 相当于while(1) )// for ( ; ; )// {// printf("111111\n");// sleep(1);// }// // (3)、单独使用表达式1// for (int num2,num3=1,num4; ; )// {// printf("num2 == %d\n", num2);// printf("num3 == %d\n", num3);// printf("num4 == %d\n", num4);// sleep(1);// }// // (4)、单独使用表达式2// // 1、简单的条件// int num5 = 0;// for ( ; num5<5; )// {// printf("num5 == %d\n", num5);// num5++;// sleep(1);// }// // 2、笔试题// int a2 = 0;// int n3 = 0;// int b2 = 9;// for ( ; a2=10,n3=10,b2>10; ) // 先执行>号,再执行a2=10,n3=10,// {// printf("1111111111111\n");// sleep(1);// }// printf("a2 == %d\n", a2);// printf("n3 == %d\n", n3);// (5)、单独使用表达式3int a3 = 0;int n4 = 0;int b3 = 0;for ( ; ; a3++,n4++,n4=a3+b3){printf("a3 == %d\n", a3);printf("n4 == %d\n", n4);printf("b3 == %d\n", b3);sleep(1);}return 0;
}七、break与continue
- 逻辑:
- break:① 跳出 switch 语句; ② 跳出当前层的循环体
- continue:结束当次循环,进入下次循环
- 示例代码:
#include <stdio.h>
int main(int argc, char const *argv[])
{// // (1)、- break:① 跳出 switch 语句; ② 跳出当前层的循环体// // 1、跳出 switch 语句// int n1 = 0;// int flag = 1;// while ( flag == 1)// {// scanf("%d", &n1);// while( getchar()!='\n');// switch (n1)// {// case 1:// printf("1111111\n");// flag = 0; // 如果要连带着退出while循环,建议设置flag来直接退出// break; // 这个break只是退出switch语句,并非退出while循环// case 2:// printf("222222\n");// break;// default:// break;// }// }// // 2、跳出当前层的循环体// // a、while循环体(do...while也是如此)// int n2 = 0;// while (1)// {// scanf("%d", &n2);// while( getchar()!='\n');// if (n2 == 1)// {// printf("333333333!\n");// break; // 跳出当前循环// }// else// {// printf("44444444444\n");// }// }// b、for循环体int n3 = 0;for (int i = 0; i < 10; i++, n3++){if (n3 == 5){printf("5555555555555555\n"); break;} }int n4 = 0;for ( ; ; ){if (n4 == 5){printf("6666666666666\n"); break;} n4++; }// (2)、- continue:结束当次循环,进入下次循环for (int i = 0; i < 100; i++){if ((i%7) == 0) // 避免一些你不想执行的操作,但是又要继续下一个循环,就使用continue{continue;}printf("%d\n", i);}return 0;
}八、goto语句
- 逻辑:无条件跳转
- 语法:
- goto语句直接跳转到本代码块中({}的范围)的标签处
- 标签指的是以冒号结尾的标识符
- 作用:
- goto语句的无条件跳转不利于程序的可读性,不建议使用(不推荐,除非迫不得已)
- goto语句常被用在程序的错误处理中(推荐)
- goto语句常被用在程序的调试中(推荐)
- 示例代码:
#include <stdio.h>
#include <unistd.h>// 普通函数(模拟一个函数功能,然后其有很多的错误返回值)
int Func(int num)
{// 申请资源switch (num){case 1: // 返回-1,-2,-3就不是正常退出 return -1;case 2: return -2;case 3: return -3;}return 0; // 返回0就是正常退出
}// 主函数
int main(int argc, char const *argv[])
{// (1)、goto语句常被用在程序的错误处理中int ret = Func(0);if (ret < 0){printf("111111111111111111111111111\n", __LINE__);goto func_error_label; // - goto语句直接跳转到本代码块中({}的范围)的标签处}printf("Func函数正常运行中!\n");// (2)、goto语句常被用在程序的调试中goto debug_label; // 1、调试while (1){while (1){while (1){while (1){while (1){sleep(1);printf("我现在在第五层循环中!\n");goto while1_label; // 2、功能嵌套了太多的循环,导致逻辑紊乱,迫不得已}}} }
while1_label:printf("回到了第一层循环中!\n");}
debug_label:printf("正在调试的语句!\n");跳转逻辑最好都是向下,不要一会上,一会下func_error_label: // - 标签指的是以冒号结尾的标识符switch (ret){case -1: printf("解决问题,将错误码为-1的问题解决(%d行)(一般是将资源回收,避免浪费系统资源)\n", __LINE__);break;case -2: printf("解决问题,将错误码为-2的问题解决(%d行)(一般是将资源回收,避免浪费系统资源)\n", __LINE__);break;case -3: printf("解决问题,将错误码为-1的问题解决(%d行)(一般是将资源回收,避免浪费系统资源)\n", __LINE__);break;}return 0;
}至此,希望看完这篇文章的你有所收获,我是Bardb,译音八分贝,期待下期与你相见!